 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Enough? A map of the current limitations of the requirements to have "fair'' algorithms
Nov 21, 2023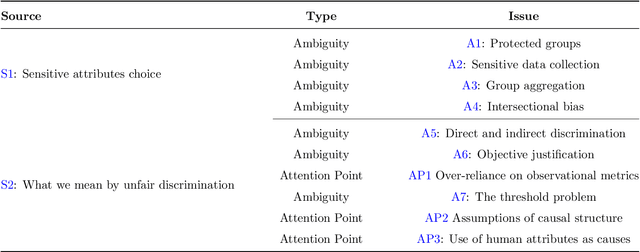
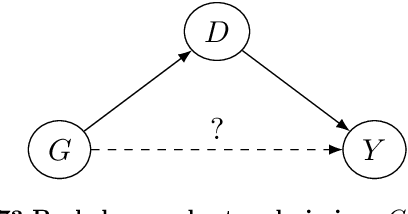

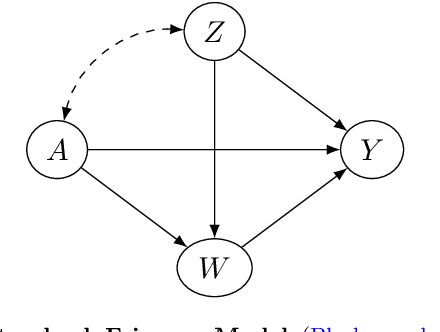
In the recent years, the raise in the usage and efficiency of Artificial Intelligence and, more in general, of Automated Decision-Making systems has brought with it an increasing and welcome awareness of the risks associated with such systems. One of such risks is that of perpetuating or even amplifying bias and unjust disparities present in the data from which many of these systems learn to adjust and optimise their decisions. This awareness has on one side encouraged several scientific communities to come up with more and more appropriate ways and methods to assess, quantify, and possibly mitigate such biases and disparities. On the other hand, it has prompted more and more layers of society, including policy makers, to call for ``fair'' algorithms. We believe that while a lot of excellent and multidisciplinary research is currently being conducted, what is still fundamentally missing is the awareness that having ``fair'' algorithms is per s\'e a nearly meaningless requirement, that needs to be complemented with a lot of additional societal choices to become actionable. Namely, there is a hiatus between what the society is demanding from Automated Decision-Making systems, and what this demand actually means in real-world scenarios. In this work, we outline the key features of such a hiatus, and pinpoint a list of fundamental ambiguities and attention points that we as a society must address in order to give a concrete meaning to the increasing demand of fairness in Automated Decision-Making systems.
Investigating Bias with a Synthetic Data Generator: Empirical Evidence and Philosophical Interpretation
Sep 13, 2022
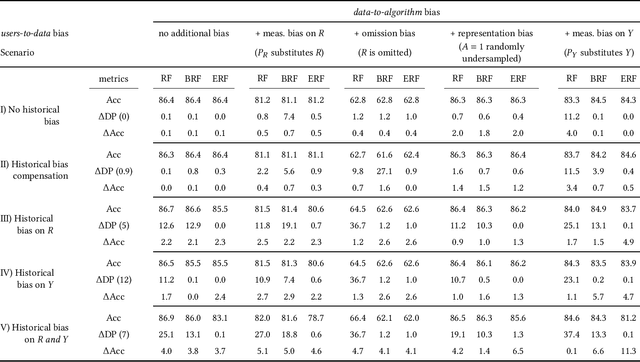
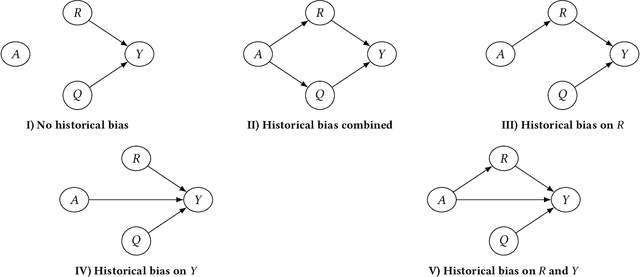
Machine learning applications are becoming increasingly pervasive in our society. Since these decision-making systems rely on data-driven learning, risk is that they will systematically spread the bias embedded in data. In this paper, we propose to analyze biases by introducing a framework for generating synthetic data with specific types of bias and their combinations. We delve into the nature of these biases discussing their relationship to moral and justice frameworks. Finally, we exploit our proposed synthetic data generator to perform experiments on different scenarios, with various bias combinations. We thus analyze the impact of biases on performance and fairness metrics both in non-mitigated and mitigated machine learning models.