Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Bias with a Synthetic Data Generator: Empirical Evidence and Philosophical Interpretation
Paper and Code

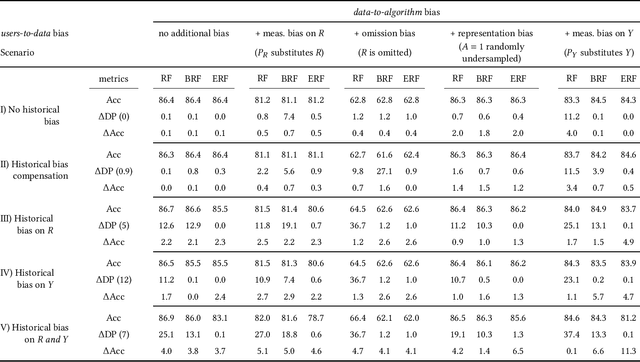
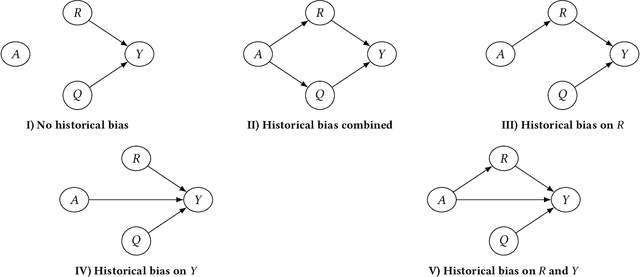
Machine learning applications are becoming increasingly pervasive in our society. Since these decision-making systems rely on data-driven learning, risk is that they will systematically spread the bias embedded in data. In this paper, we propose to analyze biases by introducing a framework for generating synthetic data with specific types of bias and their combinations. We delve into the nature of these biases discussing their relationship to moral and justice frameworks. Finally, we exploit our proposed synthetic data generator to perform experiments on different scenarios, with various bias combinations. We thus analyze the impact of biases on performance and fairness metrics both in non-mitigated and mitigated machine learning models.
* 8 pages, 2 figures. short version
View paper on