 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Explanations as Interventions in Latent Space
Jun 14, 2021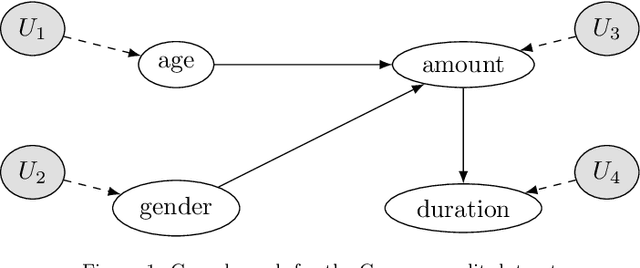
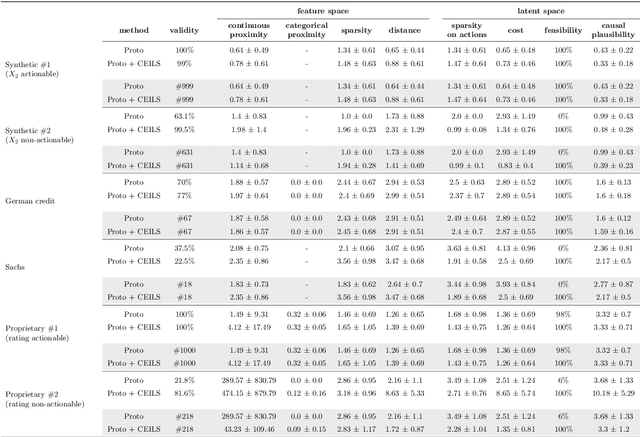
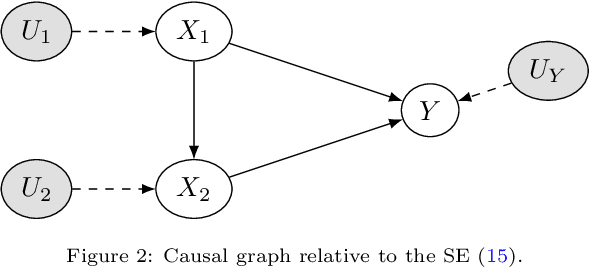
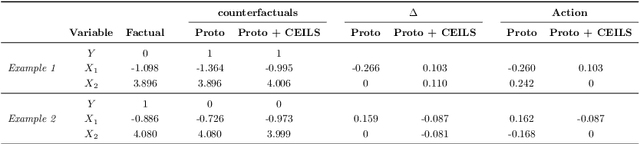
Explainable Artificial Intelligence (XAI) is a set of techniques that allows the understanding of both technical and non-technical aspects of Artificial Intelligence (AI) systems. XAI is crucial to help satisfying the increasingly important demand of \emph{trustworthy} Artificial Intelligence, characterized by fundamental characteristics such as respect of human autonomy, prevention of harm, transparency, accountability, etc. Within XAI techniques, counterfactual explanations aim to provide to end users a set of features (and their corresponding values) that need to be changed in order to achieve a desired outcome. Current approaches rarely take into account the feasibility of actions needed to achieve the proposed explanations, and in particular they fall short of considering the causal impact of such actions. In this paper, we present Counterfactual Explanations as Interventions in Latent Space (CEILS), a methodology to generate counterfactual explanations capturing by design the underlying causal relations from the data, and at the same time to provide feasible recommendations to reach the proposed profile. Moreover, our methodology has the advantage that it can be set on top of existing counterfactuals generator algorithms, thus minimising the complexity of imposing additional causal constrains. We demonstrate the effectiveness of our approach with a set of different experiments using synthetic and real datasets (including a proprietary dataset of the financial domain).
BeFair: Addressing Fairness in the Banking Sector
Feb 04, 2021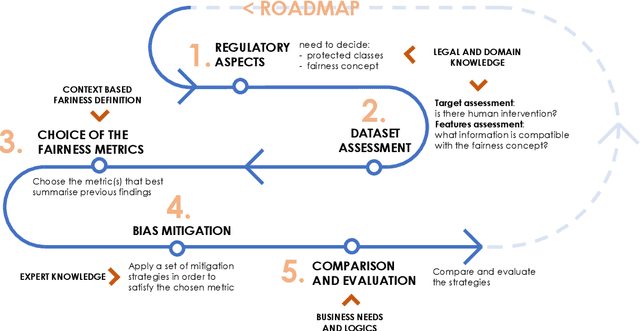
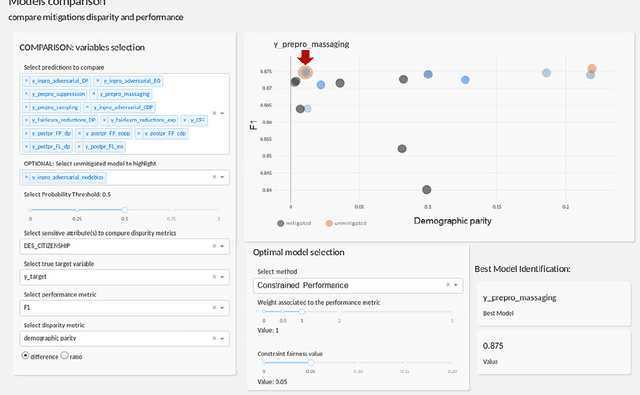
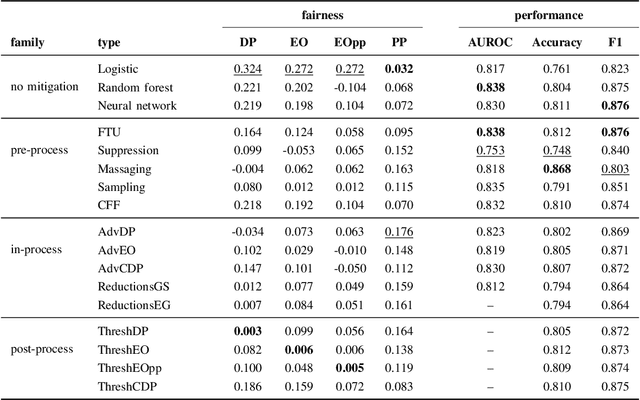
Algorithmic bias mitigation has been one of the most difficult conundrums for the data science community and Machine Learning (ML) experts. Over several years, there have appeared enormous efforts in the field of fairness in ML. Despite the progress toward identifying biases and designing fair algorithms, translating them into the industry remains a major challenge. In this paper, we present the initial results of an industrial open innovation project in the banking sector: we propose a general roadmap for fairness in ML and the implementation of a toolkit called BeFair that helps to identify and mitigate bias. Results show that training a model without explicit constraints may lead to bias exacerbation in the predictions.