 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising ESG: quantifying data uncertainty from missing data with Machine Learning and prediction intervals
Jul 29, 2024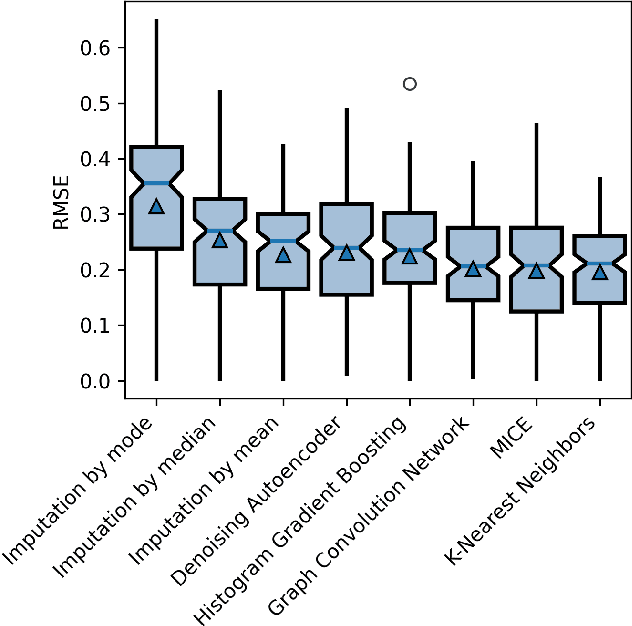


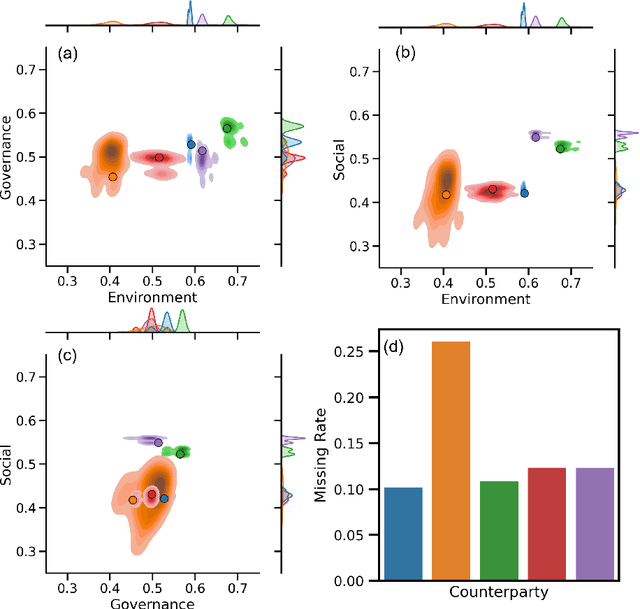
Environmental, Social, and Governance (ESG) datasets are frequently plagued by significant data gaps, leading to inconsistencies in ESG ratings due to varying imputation methods. This paper explores the application of established machine learning techniques for imputing missing data in a real-world ESG dataset, emphasizing the quantification of uncertainty through prediction intervals. By employing multiple imputation strategies, this study assesses the robustness of imputation methods and quantifies the uncertainty associated with missing data. The findings highlight the importance of probabilistic machine learning models in providing better understanding of ESG scores, thereby addressing the inherent risks of wrong ratings due to incomplete data. This approach improves imputation practices to enhance the reliability of ESG ratings.