 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible End-to-End Dialogue System for Knowledge Grounded Conversation
Sep 13, 2017

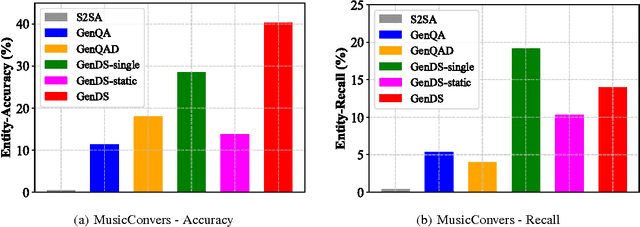

In knowledge grounded conversation, domain knowledge plays an important role in a special domain such as Music. The response of knowledge grounded conversation might contain multiple answer entities or no entity at all. Although existing generative question answering (QA) systems can be applied to knowledge grounded conversation, they either have at most one entity in a response or cannot deal with out-of-vocabulary entities. We propose a fully data-driven generative dialogue system GenDS that is capable of generating responses based on input message and related knowledge base (KB). To generate arbitrary number of answer entities even when these entities never appear in the training set, we design a dynamic knowledge enquirer which selects different answer entities at different positions in a single response, according to different local context. It does not rely on the representations of entities, enabling our model deal with out-of-vocabulary entities. We collect a human-human conversation data (ConversMusic) with knowledge annotations. The proposed method is evaluated on CoversMusic and a public question answering dataset. Our proposed GenDS system outperforms baseline methods significantly in terms of the BLEU, entity accuracy, entity recall and human evaluation. Moreover,the experiments also demonstrate that GenDS works better even on small datasets.