 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEach Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Compass-Thinker-7B Technical Report
Aug 12, 2025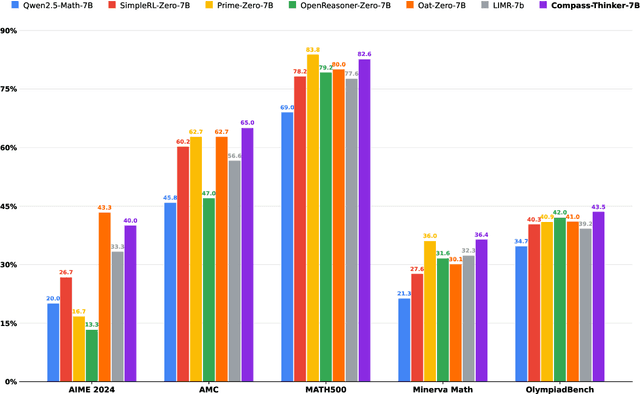

Recent R1-Zero-like research further demonstrates that reasoning extension has given large language models (LLMs) unprecedented reasoning capabilities, and Reinforcement Learning is the core technology to elicit its complex reasoning. However, conducting RL experiments directly on hyperscale models involves high computational costs and resource demands, posing significant risks. We propose the Compass-Thinker-7B model, which aims to explore the potential of Reinforcement Learning with less computational resources and costs, and provides insights for further research into RL recipes for larger models. Compass-Thinker-7B is trained from an open source model through a specially designed Reinforcement Learning Pipeline. we curate a dataset of 30k verifiable mathematics problems for the Reinforcement Learning Pipeline. By configuring data and training settings with different difficulty distributions for different stages, the potential of the model is gradually released and the training efficiency is improved. Extensive evaluations show that Compass-Thinker-7B possesses exceptional reasoning potential, and achieves superior performance on mathematics compared to the same-sized RL model.Especially in the challenging AIME2024 evaluation, Compass-Thinker-7B achieves 40% accuracy.
Cross-domain Dialogue Policy Transfer via Simultaneous Speech-act and Slot Alignment
Apr 20, 2018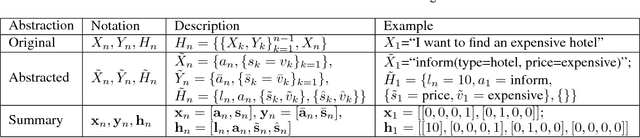
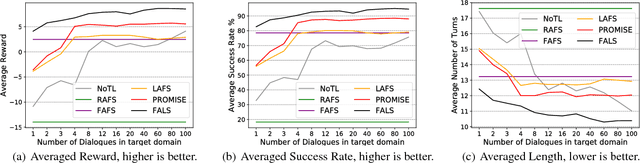
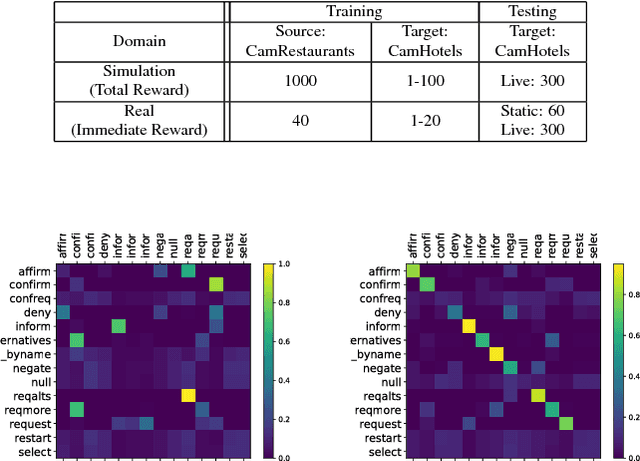
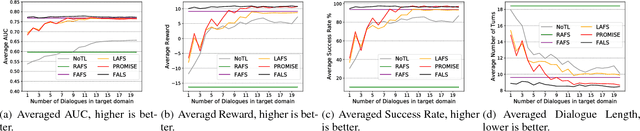
Dialogue policy transfer enables us to build dialogue policies in a target domain with little data by leveraging knowledge from a source domain with plenty of data. Dialogue sentences are usually represented by speech-acts and domain slots, and the dialogue policy transfer is usually achieved by assigning a slot mapping matrix based on human heuristics. However, existing dialogue policy transfer methods cannot transfer across dialogue domains with different speech-acts, for example, between systems built by different companies. Also, they depend on either common slots or slot entropy, which are not available when the source and target slots are totally disjoint and no database is available to calculate the slot entropy. To solve this problem, we propose a Policy tRansfer across dOMaIns and SpEech-acts (PROMISE) model, which is able to transfer dialogue policies across domains with different speech-acts and disjoint slots. The PROMISE model can learn to align different speech-acts and slots simultaneously, and it does not require common slots or the calculation of the slot entropy. Experiments on both real-world dialogue data and simulations demonstrate that PROMISE model can effectively transfer dialogue policies across domains with different speech-acts and disjoint slots.
Fine Grained Knowledge Transfer for Personalized Task-oriented Dialogue Systems
Nov 11, 2017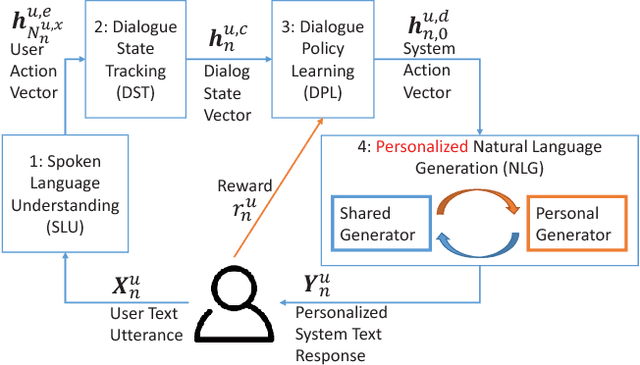
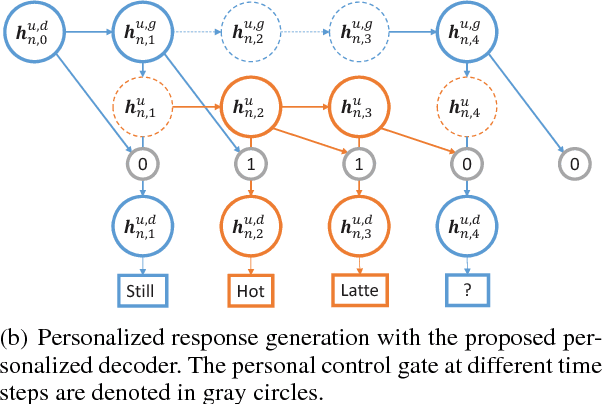

Training a personalized dialogue system requires a lot of data, and the data collected for a single user is usually insufficient. One common practice for this problem is to share training dialogues between different users and train multiple sequence-to-sequence dialogue models together with transfer learning. However, current sequence-to-sequence transfer learning models operate on the entire sentence, which might cause negative transfer if different personal information from different users is mixed up. We propose a personalized decoder model to transfer finer granularity phrase-level knowledge between different users while keeping personal preferences of each user intact. A novel personal control gate is introduced, enabling the personalized decoder to switch between generating personalized phrases and shared phrases. The proposed personalized decoder model can be easily combined with various deep models and can be trained with reinforcement learning. Real-world experimental results demonstrate that the phrase-level personalized decoder improves the BLEU over multiple sentence-level transfer baseline models by as much as 7.5%.
Integrating User and Agent Models: A Deep Task-Oriented Dialogue System
Nov 10, 2017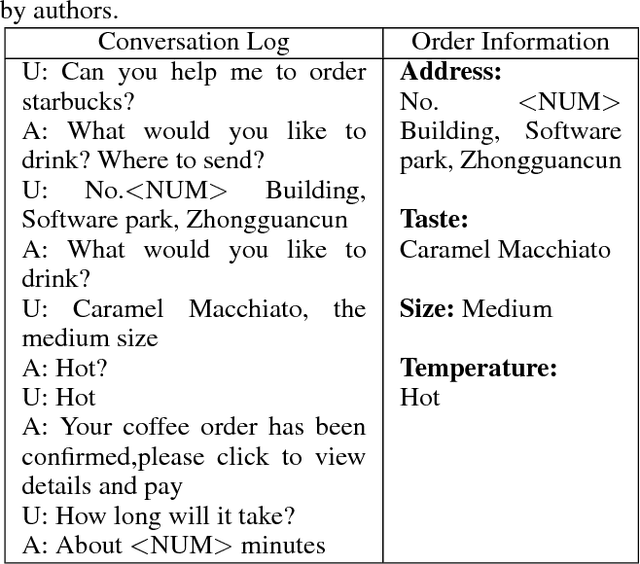
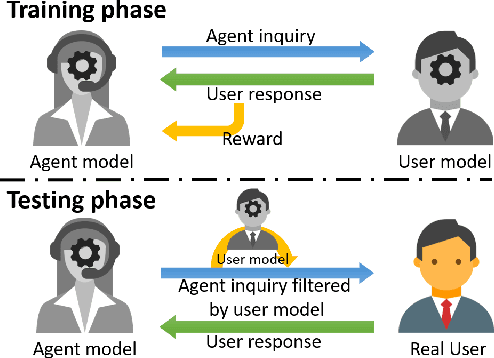
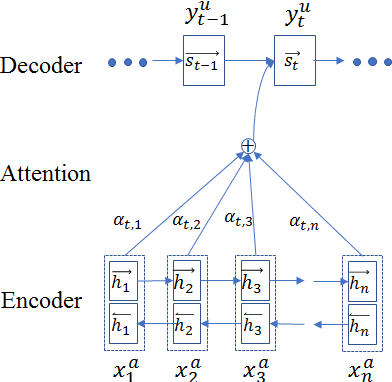
Task-oriented dialogue systems can efficiently serve a large number of customers and relieve people from tedious works. However, existing task-oriented dialogue systems depend on handcrafted actions and states or extra semantic labels, which sometimes degrades user experience despite the intensive human intervention. Moreover, current user simulators have limited expressive ability so that deep reinforcement Seq2Seq models have to rely on selfplay and only work in some special cases. To address those problems, we propose a uSer and Agent Model IntegrAtion (SAMIA) framework inspired by an observation that the roles of the user and agent models are asymmetric. Firstly, this SAMIA framework model the user model as a Seq2Seq learning problem instead of ranking or designing rules. Then the built user model is used as a leverage to train the agent model by deep reinforcement learning. In the test phase, the output of the agent model is filtered by the user model to enhance the stability and robustness. Experiments on a real-world coffee ordering dataset verify the effectiveness of the proposed SAMIA framework.
Flexible End-to-End Dialogue System for Knowledge Grounded Conversation
Sep 13, 2017

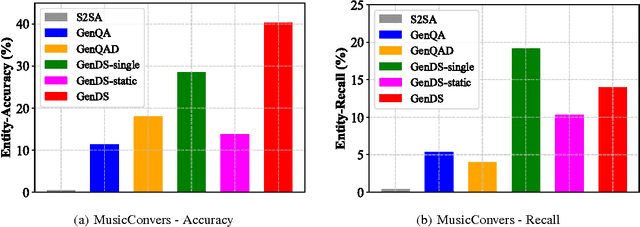

In knowledge grounded conversation, domain knowledge plays an important role in a special domain such as Music. The response of knowledge grounded conversation might contain multiple answer entities or no entity at all. Although existing generative question answering (QA) systems can be applied to knowledge grounded conversation, they either have at most one entity in a response or cannot deal with out-of-vocabulary entities. We propose a fully data-driven generative dialogue system GenDS that is capable of generating responses based on input message and related knowledge base (KB). To generate arbitrary number of answer entities even when these entities never appear in the training set, we design a dynamic knowledge enquirer which selects different answer entities at different positions in a single response, according to different local context. It does not rely on the representations of entities, enabling our model deal with out-of-vocabulary entities. We collect a human-human conversation data (ConversMusic) with knowledge annotations. The proposed method is evaluated on CoversMusic and a public question answering dataset. Our proposed GenDS system outperforms baseline methods significantly in terms of the BLEU, entity accuracy, entity recall and human evaluation. Moreover,the experiments also demonstrate that GenDS works better even on small datasets.
Personalizing a Dialogue System with Transfer Reinforcement Learning
May 26, 2017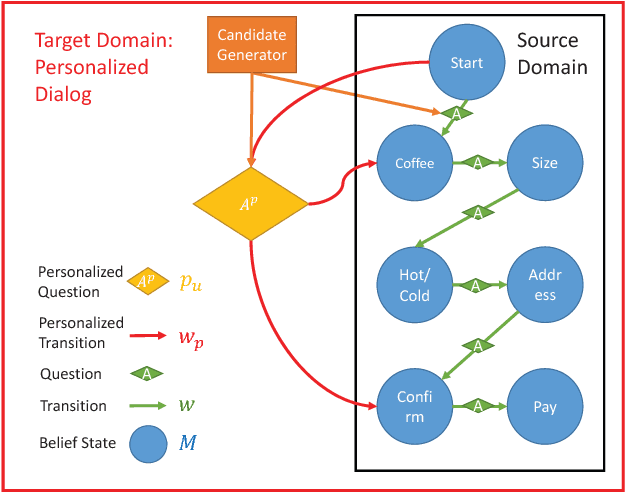


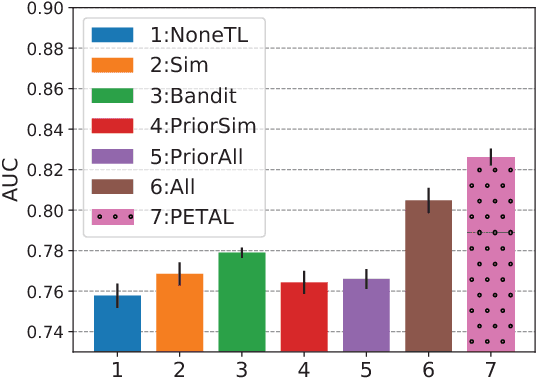
It is difficult to train a personalized task-oriented dialogue system because the data collected from each individual is often insufficient. Personalized dialogue systems trained on a small dataset can overfit and make it difficult to adapt to different user needs. One way to solve this problem is to consider a collection of multiple users' data as a source domain and an individual user's data as a target domain, and to perform a transfer learning from the source to the target domain. By following this idea, we propose "PETAL"(PErsonalized Task-oriented diALogue), a transfer-learning framework based on POMDP to learn a personalized dialogue system. The system first learns common dialogue knowledge from the source domain and then adapts this knowledge to the target user. This framework can avoid the negative transfer problem by considering differences between source and target users. The policy in the personalized POMDP can learn to choose different actions appropriately for different users. Experimental results on a real-world coffee-shopping data and simulation data show that our personalized dialogue system can choose different optimal actions for different users, and thus effectively improve the dialogue quality under the personalized setting.