 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximated Behavioral Metric-based State Projection for Federated Reinforcement Learning
May 15, 2025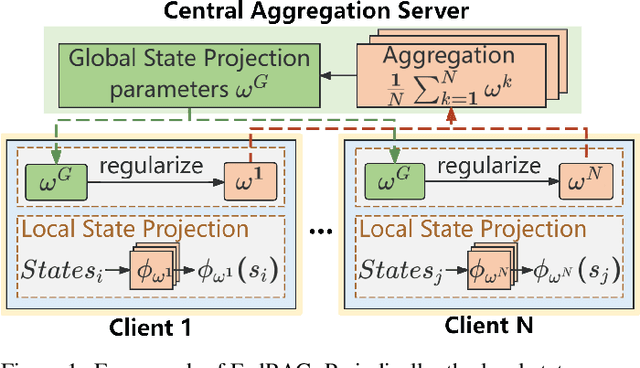

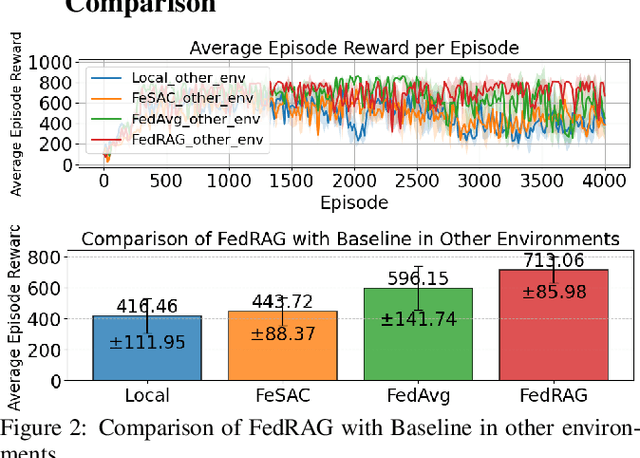
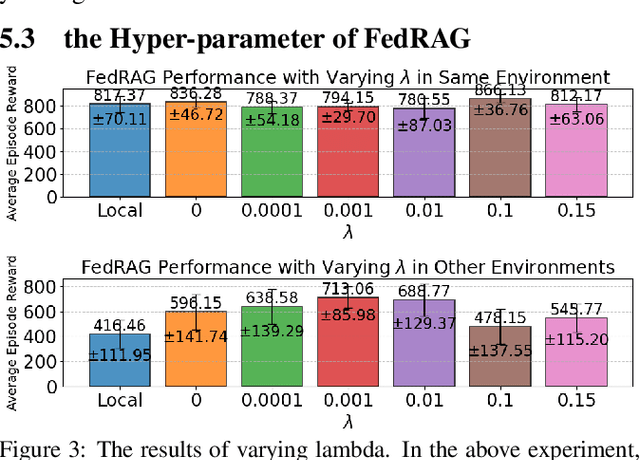
Federated reinforcement learning (FRL) methods usually share the encrypted local state or policy information and help each client to learn from others while preserving everyone's privacy. In this work, we propose that sharing the approximated behavior metric-based state projection function is a promising way to enhance the performance of FRL and concurrently provides an effective protection of sensitive information. We introduce FedRAG, a FRL framework to learn a computationally practical projection function of states for each client and aggregating the parameters of projection functions at a central server. The FedRAG approach shares no sensitive task-specific information, yet provides information gain for each client. We conduct extensive experiments on the DeepMind Control Suite to demonstrate insightful results.
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Sep 04, 2024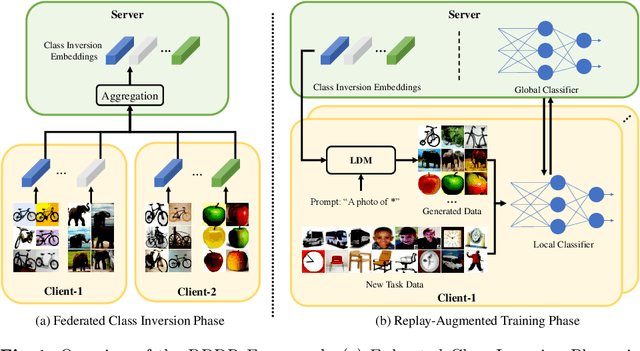
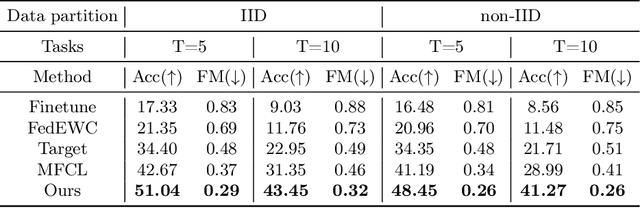
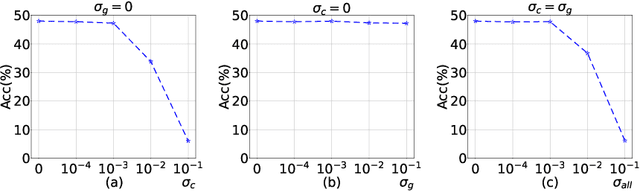
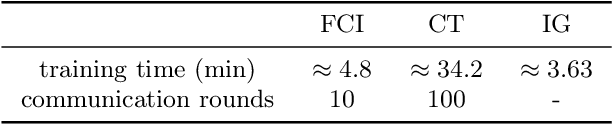
Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
PAS: A Position-Aware Similarity Measurement for Sequential Recommendation
May 19, 2022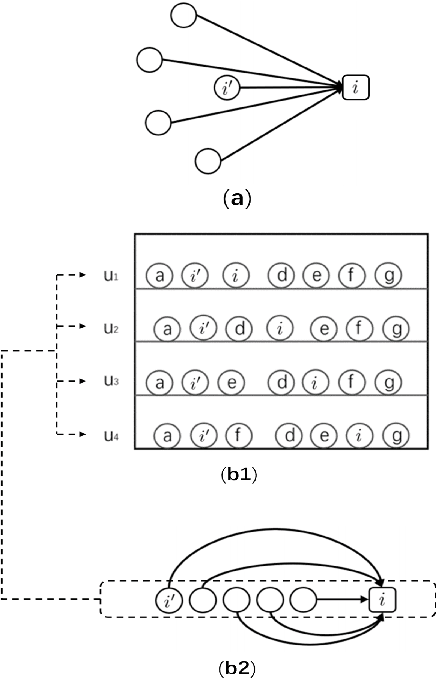
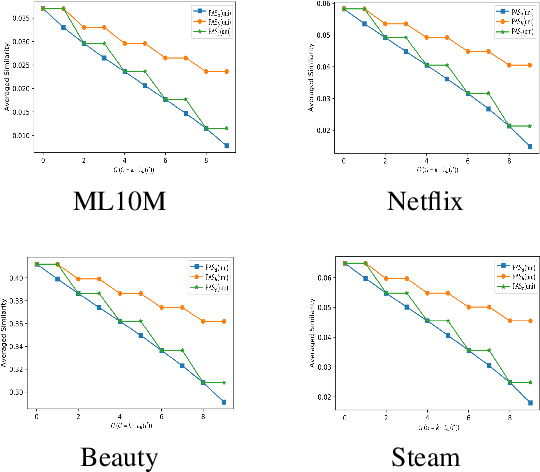
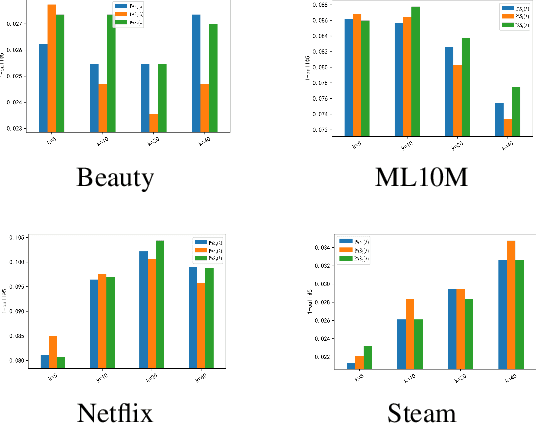
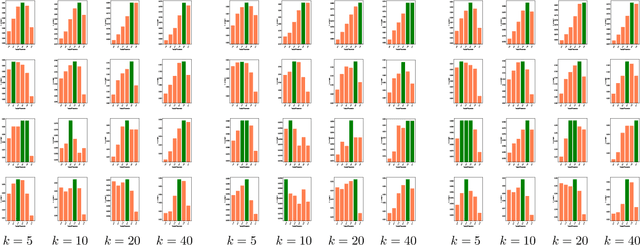
The common item-based collaborative filtering framework becomes a typical recommendation method when equipped with a certain item-to-item similarity measurement. On one hand, we realize that a well-designed similarity measurement is the key to providing satisfactory recommendation services. On the other hand, similarity measurements designed for sequential recommendation are rarely studied by the recommender systems community. Hence in this paper, we focus on devising a novel similarity measurement called position-aware similarity (PAS) for sequential recommendation. The proposed PAS is, to our knowledge, the first count-based similarity measurement that concurrently captures the sequential patterns from the historical user behavior data and from the item position information within the input sequences. We conduct extensive empirical studies on four public datasets, in which our proposed PAS-based method exhibits competitive performance even compared to the state-of-the-art sequential recommendation methods, including a very recent similarity-based method and two GNN-based methods.
Integrating User and Agent Models: A Deep Task-Oriented Dialogue System
Nov 10, 2017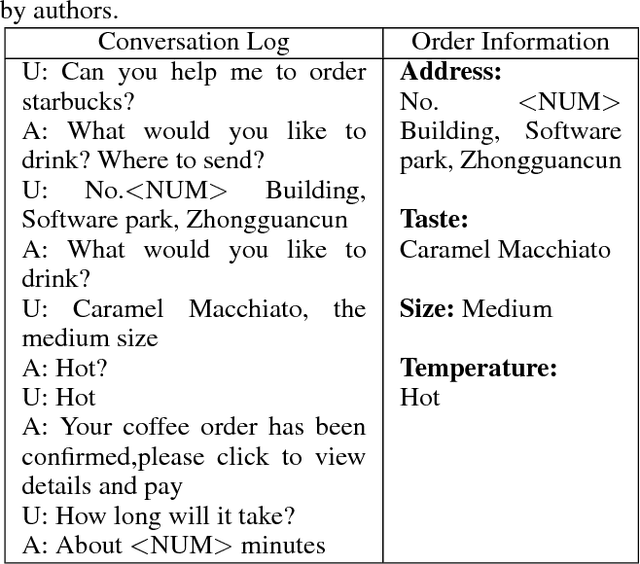
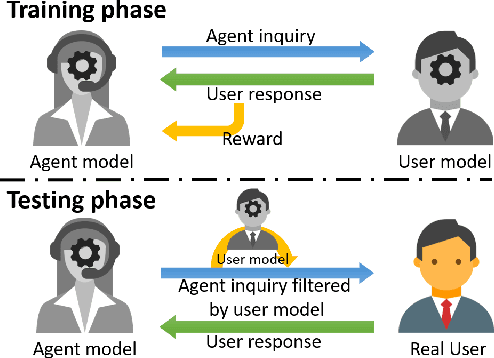
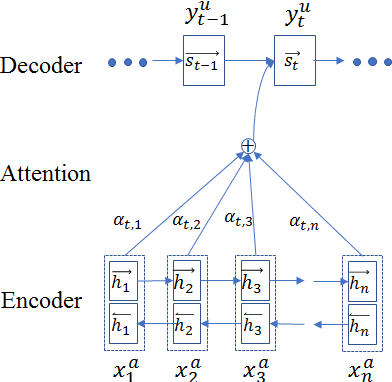
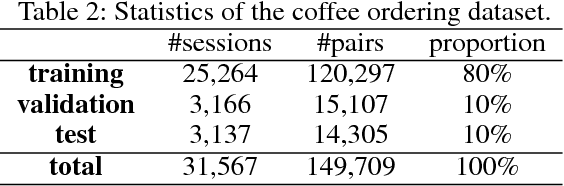
Task-oriented dialogue systems can efficiently serve a large number of customers and relieve people from tedious works. However, existing task-oriented dialogue systems depend on handcrafted actions and states or extra semantic labels, which sometimes degrades user experience despite the intensive human intervention. Moreover, current user simulators have limited expressive ability so that deep reinforcement Seq2Seq models have to rely on selfplay and only work in some special cases. To address those problems, we propose a uSer and Agent Model IntegrAtion (SAMIA) framework inspired by an observation that the roles of the user and agent models are asymmetric. Firstly, this SAMIA framework model the user model as a Seq2Seq learning problem instead of ranking or designing rules. Then the built user model is used as a leverage to train the agent model by deep reinforcement learning. In the test phase, the output of the agent model is filtered by the user model to enhance the stability and robustness. Experiments on a real-world coffee ordering dataset verify the effectiveness of the proposed SAMIA framework.
Partially Observable Markov Decision Process for Recommender Systems
Sep 01, 2016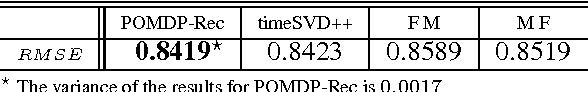
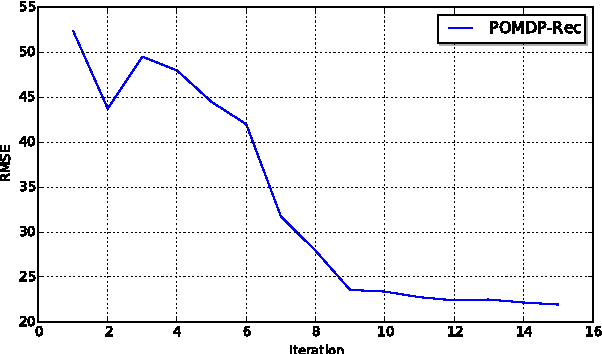
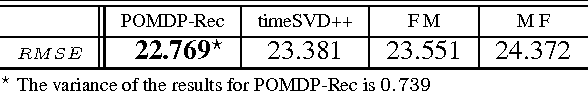
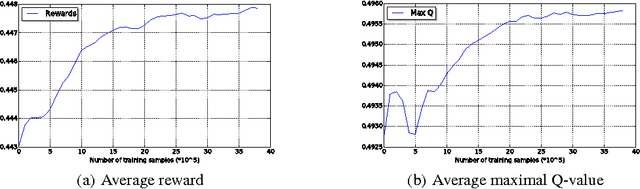
We report the "Recurrent Deterioration" (RD) phenomenon observed in online recommender systems. The RD phenomenon is reflected by the trend of performance degradation when the recommendation model is always trained based on users' feedbacks of the previous recommendations. There are several reasons for the recommender systems to encounter the RD phenomenon, including the lack of negative training data and the evolution of users' interests, etc. Motivated to tackle the problems causing the RD phenomenon, we propose the POMDP-Rec framework, which is a neural-optimized Partially Observable Markov Decision Process algorithm for recommender systems. We show that the POMDP-Rec framework effectively uses the accumulated historical data from real-world recommender systems and automatically achieves comparable results with those models fine-tuned exhaustively by domain exports on public datasets.
Selective Transfer Learning for Cross Domain Recommendation
Oct 26, 2012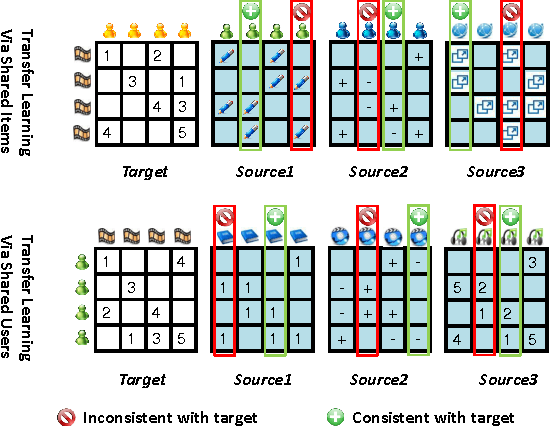
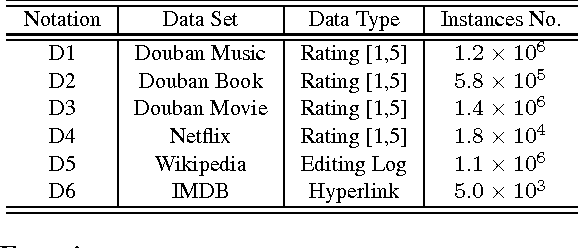
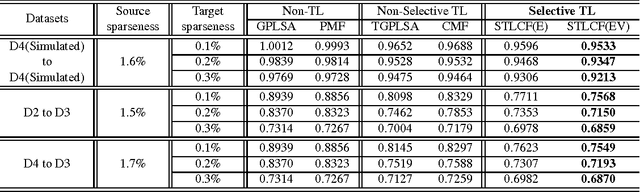
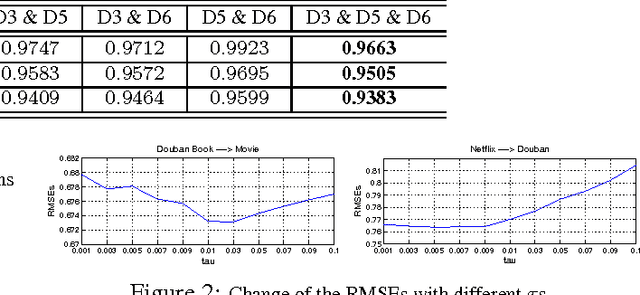
Collaborative filtering (CF) aims to predict users' ratings on items according to historical user-item preference data. In many real-world applications, preference data are usually sparse, which would make models overfit and fail to give accurate predictions. Recently, several research works show that by transferring knowledge from some manually selected source domains, the data sparseness problem could be mitigated. However for most cases, parts of source domain data are not consistent with the observations in the target domain, which may misguide the target domain model building. In this paper, we propose a novel criterion based on empirical prediction error and its variance to better capture the consistency across domains in CF settings. Consequently, we embed this criterion into a boosting framework to perform selective knowledge transfer. Comparing to several state-of-the-art methods, we show that our proposed selective transfer learning framework can significantly improve the accuracy of rating prediction tasks on several real-world recommendation tasks.