 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Correlation-Aware Hard Negative Generation
Nov 20, 2024Hard negative generation aims to generate informative negative samples that help to determine the decision boundaries and thus facilitate advancing deep metric learning. Current works select pair/triplet samples, learn their correlations, and fuse them to generate hard negatives. However, these works merely consider the local correlations of selected samples, ignoring global sample correlations that would provide more significant information to generate more informative negatives. In this work, we propose a Globally Correlation-Aware Hard Negative Generation (GCA-HNG) framework, which first learns sample correlations from a global perspective and exploits these correlations to guide generating hardness-adaptive and diverse negatives. Specifically, this approach begins by constructing a structured graph to model sample correlations, where each node represents a specific sample and each edge represents the correlations between corresponding samples. Then, we introduce an iterative graph message propagation to propagate the messages of node and edge through the whole graph and thus learn the sample correlations globally. Finally, with the guidance of the learned global correlations, we propose a channel-adaptive manner to combine an anchor and multiple negatives for HNG. Compared to current methods, GCA-HNG allows perceiving sample correlations with numerous negatives from a global and comprehensive perspective and generates the negatives with better hardness and diversity. Extensive experiment results demonstrate that the proposed GCA-HNG is superior to related methods on four image retrieval benchmark datasets. Codes and trained models are available at \url{https://github.com/PWenJay/GCA-HNG}.
One-Shot Diffusion Mimicker for Handwritten Text Generation
Sep 11, 2024Existing handwritten text generation methods often require more than ten handwriting samples as style references. However, in practical applications, users tend to prefer a handwriting generation model that operates with just a single reference sample for its convenience and efficiency. This approach, known as "one-shot generation", significantly simplifies the process but poses a significant challenge due to the difficulty of accurately capturing a writer's style from a single sample, especially when extracting fine details from the characters' edges amidst sparse foreground and undesired background noise. To address this problem, we propose a One-shot Diffusion Mimicker (One-DM) to generate handwritten text that can mimic any calligraphic style with only one reference sample. Inspired by the fact that high-frequency information of the individual sample often contains distinct style patterns (e.g., character slant and letter joining), we develop a novel style-enhanced module to improve the style extraction by incorporating high-frequency components from a single sample. We then fuse the style features with the text content as a merged condition for guiding the diffusion model to produce high-quality handwritten text images. Extensive experiments demonstrate that our method can successfully generate handwriting scripts with just one sample reference in multiple languages, even outperforming previous methods using over ten samples. Our source code is available at https://github.com/dailenson/One-DM.
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Sep 04, 2024Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023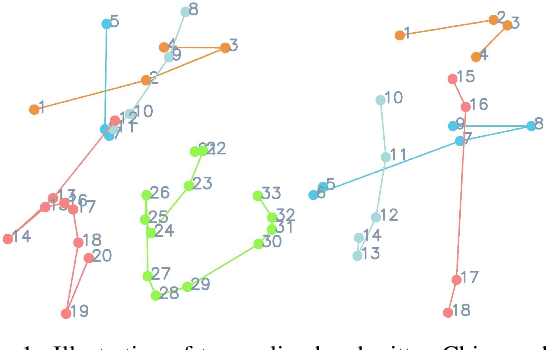



Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation
Mar 13, 2023



The study of ancient writings has great value for archaeology and philology. Essential forms of material are photographic characters, but manual photographic character recognition is extremely time-consuming and expertise-dependent. Automatic classification is therefore greatly desired. However, the current performance is limited due to the lack of annotated data. Data generation is an inexpensive but useful solution for data scarcity. Nevertheless, the diverse glyph shapes and complex background textures of photographic ancient characters make the generation task difficult, leading to the unsatisfactory results of existing methods. In this paper, we propose an unsupervised generative adversarial network called AGTGAN. By the explicit global and local glyph shape style modeling followed by the stroke-aware texture transfer, as well as an associate adversarial learning mechanism, our method can generate characters with diverse glyphs and realistic textures. We evaluate our approach on the photographic ancient character datasets, e.g., OBC306 and CSDD. Our method outperforms the state-of-the-art approaches in various metrics and performs much better in terms of the diversity and authenticity of generated samples. With our generated images, experiments on the largest photographic oracle bone character dataset show that our method can achieve a significant increase in classification accuracy, up to 16.34%.