 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracleAgent: A Multimodal Reasoning Agent for Oracle Bone Script Research
Oct 30, 2025As one of the earliest writing systems, Oracle Bone Script (OBS) preserves the cultural and intellectual heritage of ancient civilizations. However, current OBS research faces two major challenges: (1) the interpretation of OBS involves a complex workflow comprising multiple serial and parallel sub-tasks, and (2) the efficiency of OBS information organization and retrieval remains a critical bottleneck, as scholars often spend substantial effort searching for, compiling, and managing relevant resources. To address these challenges, we present OracleAgent, the first agent system designed for the structured management and retrieval of OBS-related information. OracleAgent seamlessly integrates multiple OBS analysis tools, empowered by large language models (LLMs), and can flexibly orchestrate these components. Additionally, we construct a comprehensive domain-specific multimodal knowledge base for OBS, which is built through a rigorous multi-year process of data collection, cleaning, and expert annotation. The knowledge base comprises over 1.4M single-character rubbing images and 80K interpretation texts. OracleAgent leverages this resource through its multimodal tools to assist experts in retrieval tasks of character, document, interpretation text, and rubbing image. Extensive experiments demonstrate that OracleAgent achieves superior performance across a range of multimodal reasoning and generation tasks, surpassing leading mainstream multimodal large language models (MLLMs) (e.g., GPT-4o). Furthermore, our case study illustrates that OracleAgent can effectively assist domain experts, significantly reducing the time cost of OBS research. These results highlight OracleAgent as a significant step toward the practical deployment of OBS-assisted research and automated interpretation systems.
A comprehensive survey of oracle character recognition: challenges, benchmarks, and beyond
Nov 18, 2024



Oracle character recognition-an analysis of ancient Chinese inscriptions found on oracle bones-has become a pivotal field intersecting archaeology, paleography, and historical cultural studies. Traditional methods of oracle character recognition have relied heavily on manual interpretation by experts, which is not only labor-intensive but also limits broader accessibility to the general public. With recent breakthroughs in pattern recognition and deep learning, there is a growing movement towards the automation of oracle character recognition (OrCR), showing considerable promise in tackling the challenges inherent to these ancient scripts. However, a comprehensive understanding of OrCR still remains elusive. Therefore, this paper presents a systematic and structured survey of the current landscape of OrCR research. We commence by identifying and analyzing the key challenges of OrCR. Then, we provide an overview of the primary benchmark datasets and digital resources available for OrCR. A review of contemporary research methodologies follows, in which their respective efficacies, limitations, and applicability to the complex nature of oracle characters are critically highlighted and examined. Additionally, our review extends to ancillary tasks associated with OrCR across diverse disciplines, providing a broad-spectrum analysis of its applications. We conclude with a forward-looking perspective, proposing potential avenues for future investigations that could yield significant advancements in the field.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024
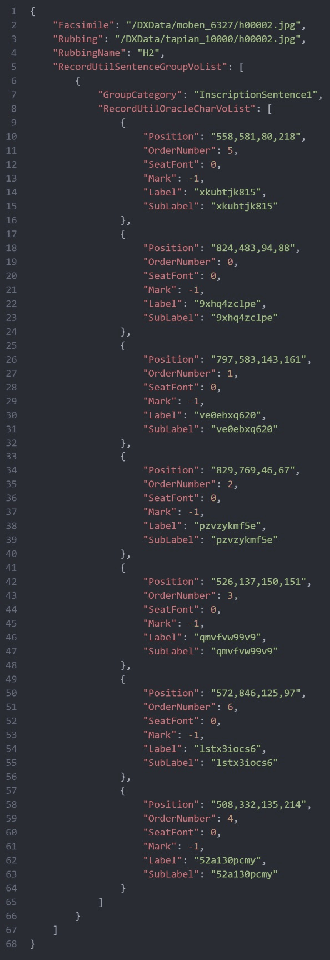
Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.
Puzzle Pieces Picker: Deciphering Ancient Chinese Characters with Radical Reconstruction
Jun 05, 2024



Oracle Bone Inscriptions is one of the oldest existing forms of writing in the world. However, due to the great antiquity of the era, a large number of Oracle Bone Inscriptions (OBI) remain undeciphered, making it one of the global challenges in the field of paleography today. This paper introduces a novel approach, namely Puzzle Pieces Picker (P$^3$), to decipher these enigmatic characters through radical reconstruction. We deconstruct OBI into foundational strokes and radicals, then employ a Transformer model to reconstruct them into their modern (conterpart)\textcolor{blue}{counterparts}, offering a groundbreaking solution to ancient script analysis. To further this endeavor, a new Ancient Chinese Character Puzzles (ACCP) dataset was developed, comprising an extensive collection of character images from seven key historical stages, annotated with detailed radical sequences. The experiments have showcased considerable promising insights, underscoring the potential and effectiveness of our approach in deciphering the intricacies of ancient Chinese scripts. Through this novel dataset and methodology, we aim to bridge the gap between traditional philology and modern document analysis techniques, offering new insights into the rich history of Chinese linguistic heritage.
Deciphering Oracle Bone Language with Diffusion Models
Jun 02, 2024



Originating from China's Shang Dynasty approximately 3,000 years ago, the Oracle Bone Script (OBS) is a cornerstone in the annals of linguistic history, predating many established writing systems. Despite the discovery of thousands of inscriptions, a vast expanse of OBS remains undeciphered, casting a veil of mystery over this ancient language. The emergence of modern AI technologies presents a novel frontier for OBS decipherment, challenging traditional NLP methods that rely heavily on large textual corpora, a luxury not afforded by historical languages. This paper introduces a novel approach by adopting image generation techniques, specifically through the development of Oracle Bone Script Decipher (OBSD). Utilizing a conditional diffusion-based strategy, OBSD generates vital clues for decipherment, charting a new course for AI-assisted analysis of ancient languages. To validate its efficacy, extensive experiments were conducted on an oracle bone script dataset, with quantitative results demonstrating the effectiveness of OBSD. Code and decipherment results will be made available at https://github.com/guanhaisu/OBSD.
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation
Mar 13, 2023



The study of ancient writings has great value for archaeology and philology. Essential forms of material are photographic characters, but manual photographic character recognition is extremely time-consuming and expertise-dependent. Automatic classification is therefore greatly desired. However, the current performance is limited due to the lack of annotated data. Data generation is an inexpensive but useful solution for data scarcity. Nevertheless, the diverse glyph shapes and complex background textures of photographic ancient characters make the generation task difficult, leading to the unsatisfactory results of existing methods. In this paper, we propose an unsupervised generative adversarial network called AGTGAN. By the explicit global and local glyph shape style modeling followed by the stroke-aware texture transfer, as well as an associate adversarial learning mechanism, our method can generate characters with diverse glyphs and realistic textures. We evaluate our approach on the photographic ancient character datasets, e.g., OBC306 and CSDD. Our method outperforms the state-of-the-art approaches in various metrics and performs much better in terms of the diversity and authenticity of generated samples. With our generated images, experiments on the largest photographic oracle bone character dataset show that our method can achieve a significant increase in classification accuracy, up to 16.34%.