 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossVTON: Mimicking the Logic Reasoning on Cross-category Virtual Try-on guided by Tri-zone Priors
Feb 20, 2025



Despite remarkable progress in image-based virtual try-on systems, generating realistic and robust fitting images for cross-category virtual try-on remains a challenging task. The primary difficulty arises from the absence of human-like reasoning, which involves addressing size mismatches between garments and models while recognizing and leveraging the distinct functionalities of various regions within the model images. To address this issue, we draw inspiration from human cognitive processes and disentangle the complex reasoning required for cross-category try-on into a structured framework. This framework systematically decomposes the model image into three distinct regions: try-on, reconstruction, and imagination zones. Each zone plays a specific role in accommodating the garment and facilitating realistic synthesis. To endow the model with robust reasoning capabilities for cross-category scenarios, we propose an iterative data constructor. This constructor encompasses diverse scenarios, including intra-category try-on, any-to-dress transformations (replacing any garment category with a dress), and dress-to-any transformations (replacing a dress with another garment category). Utilizing the generated dataset, we introduce a tri-zone priors generator that intelligently predicts the try-on, reconstruction, and imagination zones by analyzing how the input garment is expected to align with the model image. Guided by these tri-zone priors, our proposed method, CrossVTON, achieves state-of-the-art performance, surpassing existing baselines in both qualitative and quantitative evaluations. Notably, it demonstrates superior capability in handling cross-category virtual try-on, meeting the complex demands of real-world applications.
VTON-HandFit: Virtual Try-on for Arbitrary Hand Pose Guided by Hand Priors Embedding
Aug 27, 2024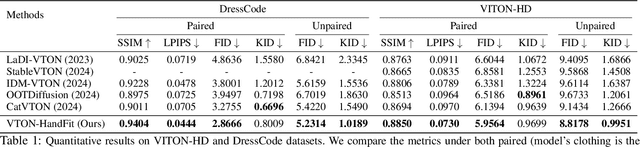
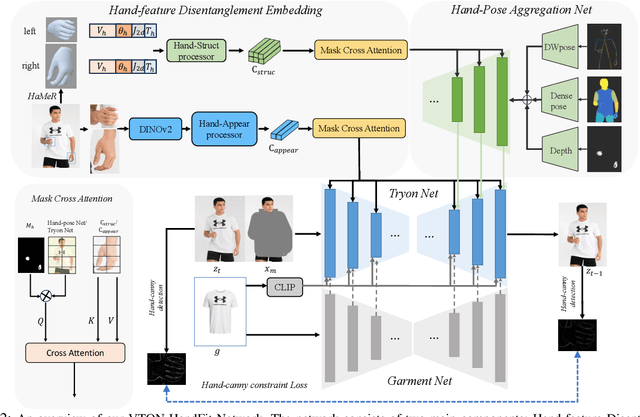


Although diffusion-based image virtual try-on has made considerable progress, emerging approaches still struggle to effectively address the issue of hand occlusion (i.e., clothing regions occluded by the hand part), leading to a notable degradation of the try-on performance. To tackle this issue widely existing in real-world scenarios, we propose VTON-HandFit, leveraging the power of hand priors to reconstruct the appearance and structure for hand occlusion cases. Firstly, we tailor a Handpose Aggregation Net using the ControlNet-based structure explicitly and adaptively encoding the global hand and pose priors. Besides, to fully exploit the hand-related structure and appearance information, we propose Hand-feature Disentanglement Embedding module to disentangle the hand priors into the hand structure-parametric and visual-appearance features, and customize a masked cross attention for further decoupled feature embedding. Lastly, we customize a hand-canny constraint loss to better learn the structure edge knowledge from the hand template of model image. VTON-HandFit outperforms the baselines in qualitative and quantitative evaluations on the public dataset and our self-collected hand-occlusion Handfit-3K dataset particularly for the arbitrary hand pose occlusion cases in real-world scenarios. The Code and dataset will be available at \url{https://github.com/VTON-HandFit/VTON-HandFit}.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024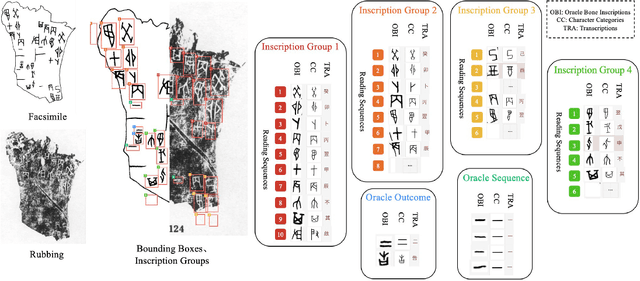
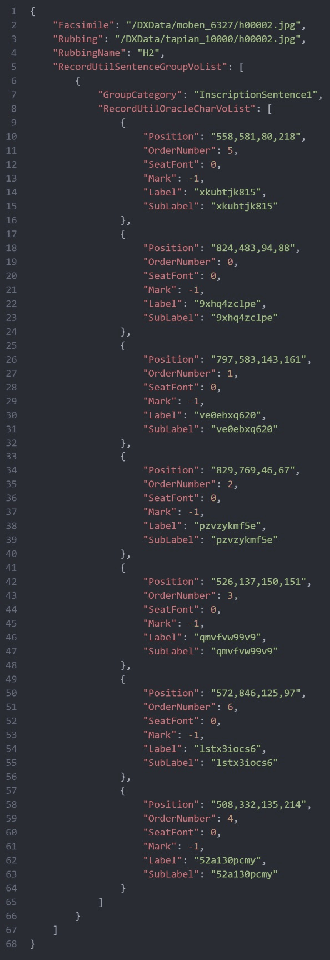
Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.