 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFP-300K: Scaling First-Frame Propagation for Generalizable Video Editing
Jan 06, 2026First-Frame Propagation (FFP) offers a promising paradigm for controllable video editing, but existing methods are hampered by a reliance on cumbersome run-time guidance. We identify the root cause of this limitation as the inadequacy of current training datasets, which are often too short, low-resolution, and lack the task diversity required to teach robust temporal priors. To address this foundational data gap, we first introduce FFP-300K, a new large-scale dataset comprising 300K high-fidelity video pairs at 720p resolution and 81 frames in length, constructed via a principled two-track pipeline for diverse local and global edits. Building on this dataset, we propose a novel framework designed for true guidance-free FFP that resolves the critical tension between maintaining first-frame appearance and preserving source video motion. Architecturally, we introduce Adaptive Spatio-Temporal RoPE (AST-RoPE), which dynamically remaps positional encodings to disentangle appearance and motion references. At the objective level, we employ a self-distillation strategy where an identity propagation task acts as a powerful regularizer, ensuring long-term temporal stability and preventing semantic drift. Comprehensive experiments on the EditVerseBench benchmark demonstrate that our method significantly outperforming existing academic and commercial models by receiving about 0.2 PickScore and 0.3 VLM score improvement against these competitors.
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/
OracleAgent: A Multimodal Reasoning Agent for Oracle Bone Script Research
Oct 30, 2025As one of the earliest writing systems, Oracle Bone Script (OBS) preserves the cultural and intellectual heritage of ancient civilizations. However, current OBS research faces two major challenges: (1) the interpretation of OBS involves a complex workflow comprising multiple serial and parallel sub-tasks, and (2) the efficiency of OBS information organization and retrieval remains a critical bottleneck, as scholars often spend substantial effort searching for, compiling, and managing relevant resources. To address these challenges, we present OracleAgent, the first agent system designed for the structured management and retrieval of OBS-related information. OracleAgent seamlessly integrates multiple OBS analysis tools, empowered by large language models (LLMs), and can flexibly orchestrate these components. Additionally, we construct a comprehensive domain-specific multimodal knowledge base for OBS, which is built through a rigorous multi-year process of data collection, cleaning, and expert annotation. The knowledge base comprises over 1.4M single-character rubbing images and 80K interpretation texts. OracleAgent leverages this resource through its multimodal tools to assist experts in retrieval tasks of character, document, interpretation text, and rubbing image. Extensive experiments demonstrate that OracleAgent achieves superior performance across a range of multimodal reasoning and generation tasks, surpassing leading mainstream multimodal large language models (MLLMs) (e.g., GPT-4o). Furthermore, our case study illustrates that OracleAgent can effectively assist domain experts, significantly reducing the time cost of OBS research. These results highlight OracleAgent as a significant step toward the practical deployment of OBS-assisted research and automated interpretation systems.
CrossVTON: Mimicking the Logic Reasoning on Cross-category Virtual Try-on guided by Tri-zone Priors
Feb 20, 2025



Despite remarkable progress in image-based virtual try-on systems, generating realistic and robust fitting images for cross-category virtual try-on remains a challenging task. The primary difficulty arises from the absence of human-like reasoning, which involves addressing size mismatches between garments and models while recognizing and leveraging the distinct functionalities of various regions within the model images. To address this issue, we draw inspiration from human cognitive processes and disentangle the complex reasoning required for cross-category try-on into a structured framework. This framework systematically decomposes the model image into three distinct regions: try-on, reconstruction, and imagination zones. Each zone plays a specific role in accommodating the garment and facilitating realistic synthesis. To endow the model with robust reasoning capabilities for cross-category scenarios, we propose an iterative data constructor. This constructor encompasses diverse scenarios, including intra-category try-on, any-to-dress transformations (replacing any garment category with a dress), and dress-to-any transformations (replacing a dress with another garment category). Utilizing the generated dataset, we introduce a tri-zone priors generator that intelligently predicts the try-on, reconstruction, and imagination zones by analyzing how the input garment is expected to align with the model image. Guided by these tri-zone priors, our proposed method, CrossVTON, achieves state-of-the-art performance, surpassing existing baselines in both qualitative and quantitative evaluations. Notably, it demonstrates superior capability in handling cross-category virtual try-on, meeting the complex demands of real-world applications.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024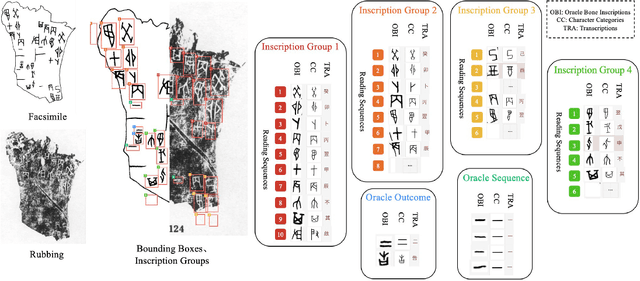
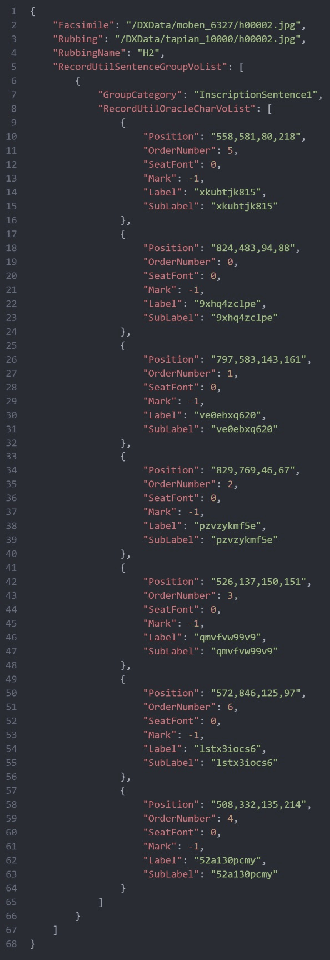
Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.
DiffuMatting: Synthesizing Arbitrary Objects with Matting-level Annotation
Mar 10, 2024Due to the difficulty and labor-consuming nature of getting highly accurate or matting annotations, there only exists a limited amount of highly accurate labels available to the public. To tackle this challenge, we propose a DiffuMatting which inherits the strong Everything generation ability of diffusion and endows the power of "matting anything". Our DiffuMatting can 1). act as an anything matting factory with high accurate annotations 2). be well-compatible with community LoRAs or various conditional control approaches to achieve the community-friendly art design and controllable generation. Specifically, inspired by green-screen-matting, we aim to teach the diffusion model to paint on a fixed green screen canvas. To this end, a large-scale greenscreen dataset (Green100K) is collected as a training dataset for DiffuMatting. Secondly, a green background control loss is proposed to keep the drawing board as a pure green color to distinguish the foreground and background. To ensure the synthesized object has more edge details, a detailed-enhancement of transition boundary loss is proposed as a guideline to generate objects with more complicated edge structures. Aiming to simultaneously generate the object and its matting annotation, we build a matting head to make a green color removal in the latent space of the VAE decoder. Our DiffuMatting shows several potential applications (e.g., matting-data generator, community-friendly art design and controllable generation). As a matting-data generator, DiffuMatting synthesizes general object and portrait matting sets, effectively reducing the relative MSE error by 15.4% in General Object Matting and 11.4% in Portrait Matting tasks.
PortraitBooth: A Versatile Portrait Model for Fast Identity-preserved Personalization
Dec 11, 2023



Recent advancements in personalized image generation using diffusion models have been noteworthy. However, existing methods suffer from inefficiencies due to the requirement for subject-specific fine-tuning. This computationally intensive process hinders efficient deployment, limiting practical usability. Moreover, these methods often grapple with identity distortion and limited expression diversity. In light of these challenges, we propose PortraitBooth, an innovative approach designed for high efficiency, robust identity preservation, and expression-editable text-to-image generation, without the need for fine-tuning. PortraitBooth leverages subject embeddings from a face recognition model for personalized image generation without fine-tuning. It eliminates computational overhead and mitigates identity distortion. The introduced dynamic identity preservation strategy further ensures close resemblance to the original image identity. Moreover, PortraitBooth incorporates emotion-aware cross-attention control for diverse facial expressions in generated images, supporting text-driven expression editing. Its scalability enables efficient and high-quality image creation, including multi-subject generation. Extensive results demonstrate superior performance over other state-of-the-art methods in both single and multiple image generation scenarios.