 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform Trained Transformer: Accelerating Naive 4K Video Generation Over 10$\times$
Dec 15, 2025Native 4K (2160$\times$3840) video generation remains a critical challenge due to the quadratic computational explosion of full-attention as spatiotemporal resolution increases, making it difficult for models to strike a balance between efficiency and quality. This paper proposes a novel Transformer retrofit strategy termed $\textbf{T3}$ ($\textbf{T}$ransform $\textbf{T}$rained $\textbf{T}$ransformer) that, without altering the core architecture of full-attention pretrained models, significantly reduces compute requirements by optimizing their forward logic. Specifically, $\textbf{T3-Video}$ introduces a multi-scale weight-sharing window attention mechanism and, via hierarchical blocking together with an axis-preserving full-attention design, can effect an "attention pattern" transformation of a pretrained model using only modest compute and data. Results on 4K-VBench show that $\textbf{T3-Video}$ substantially outperforms existing approaches: while delivering performance improvements (+4.29$\uparrow$ VQA and +0.08$\uparrow$ VTC), it accelerates native 4K video generation by more than 10$\times$. Project page at https://zhangzjn.github.io/projects/T3-Video
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/
Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation
Apr 25, 2025Recent advances in Talking Head Generation (THG) have achieved impressive lip synchronization and visual quality through diffusion models; yet existing methods struggle to generate emotionally expressive portraits while preserving speaker identity. We identify three critical limitations in current emotional talking head generation: insufficient utilization of audio's inherent emotional cues, identity leakage in emotion representations, and isolated learning of emotion correlations. To address these challenges, we propose a novel framework dubbed as DICE-Talk, following the idea of disentangling identity with emotion, and then cooperating emotions with similar characteristics. First, we develop a disentangled emotion embedder that jointly models audio-visual emotional cues through cross-modal attention, representing emotions as identity-agnostic Gaussian distributions. Second, we introduce a correlation-enhanced emotion conditioning module with learnable Emotion Banks that explicitly capture inter-emotion relationships through vector quantization and attention-based feature aggregation. Third, we design an emotion discrimination objective that enforces affective consistency during the diffusion process through latent-space classification. Extensive experiments on MEAD and HDTF datasets demonstrate our method's superiority, outperforming state-of-the-art approaches in emotion accuracy while maintaining competitive lip-sync performance. Qualitative results and user studies further confirm our method's ability to generate identity-preserving portraits with rich, correlated emotional expressions that naturally adapt to unseen identities.
HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
SVFR: A Unified Framework for Generalized Video Face Restoration
Jan 03, 2025



Face Restoration (FR) is a crucial area within image and video processing, focusing on reconstructing high-quality portraits from degraded inputs. Despite advancements in image FR, video FR remains relatively under-explored, primarily due to challenges related to temporal consistency, motion artifacts, and the limited availability of high-quality video data. Moreover, traditional face restoration typically prioritizes enhancing resolution and may not give as much consideration to related tasks such as facial colorization and inpainting. In this paper, we propose a novel approach for the Generalized Video Face Restoration (GVFR) task, which integrates video BFR, inpainting, and colorization tasks that we empirically show to benefit each other. We present a unified framework, termed as stable video face restoration (SVFR), which leverages the generative and motion priors of Stable Video Diffusion (SVD) and incorporates task-specific information through a unified face restoration framework. A learnable task embedding is introduced to enhance task identification. Meanwhile, a novel Unified Latent Regularization (ULR) is employed to encourage the shared feature representation learning among different subtasks. To further enhance the restoration quality and temporal stability, we introduce the facial prior learning and the self-referred refinement as auxiliary strategies used for both training and inference. The proposed framework effectively combines the complementary strengths of these tasks, enhancing temporal coherence and achieving superior restoration quality. This work advances the state-of-the-art in video FR and establishes a new paradigm for generalized video face restoration. Code and video demo are available at https://github.com/wangzhiyaoo/SVFR.git.
HiFiVFS: High Fidelity Video Face Swapping
Nov 27, 2024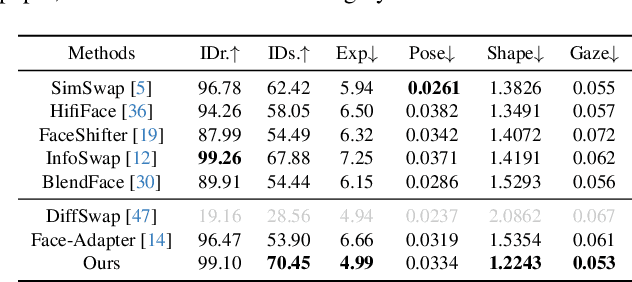
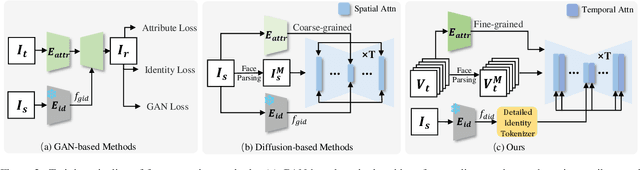

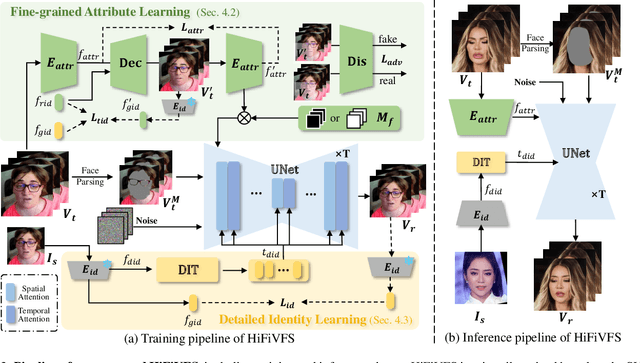
Face swapping aims to generate results that combine the identity from the source with attributes from the target. Existing methods primarily focus on image-based face swapping. When processing videos, each frame is handled independently, making it difficult to ensure temporal stability. From a model perspective, face swapping is gradually shifting from generative adversarial networks (GANs) to diffusion models (DMs), as DMs have been shown to possess stronger generative capabilities. Current diffusion-based approaches often employ inpainting techniques, which struggle to preserve fine-grained attributes like lighting and makeup. To address these challenges, we propose a high fidelity video face swapping (HiFiVFS) framework, which leverages the strong generative capability and temporal prior of Stable Video Diffusion (SVD). We build a fine-grained attribute module to extract identity-disentangled and fine-grained attribute features through identity desensitization and adversarial learning. Additionally, We introduce detailed identity injection to further enhance identity similarity. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) in video face swapping, both qualitatively and quantitatively.
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Nov 25, 2024



The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model
Sep 05, 2024Talking Head Generation (THG), typically driven by audio, is an important and challenging task with broad application prospects in various fields such as digital humans, film production, and virtual reality. While diffusion model-based THG methods present high quality and stable content generation, they often overlook the intrinsic style which encompasses personalized features such as speaking habits and facial expressions of a video. As consequence, the generated video content lacks diversity and vividness, thus being limited in real life scenarios. To address these issues, we propose a novel framework named Style-Enhanced Vivid Portrait (SVP) which fully leverages style-related information in THG. Specifically, we first introduce the novel probabilistic style prior learning to model the intrinsic style as a Gaussian distribution using facial expressions and audio embedding. The distribution is learned through the 'bespoked' contrastive objective, effectively capturing the dynamic style information in each video. Then we finetune a pretrained Stable Diffusion (SD) model to inject the learned intrinsic style as a controlling signal via cross attention. Experiments show that our model generates diverse, vivid, and high-quality videos with flexible control over intrinsic styles, outperforming existing state-of-the-art methods.
RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network
Jun 26, 2024Person-generic audio-driven face generation is a challenging task in computer vision. Previous methods have achieved remarkable progress in audio-visual synchronization, but there is still a significant gap between current results and practical applications. The challenges are two-fold: 1) Preserving unique individual traits for achieving high-precision lip synchronization. 2) Generating high-quality facial renderings in real-time performance. In this paper, we propose a novel generalized audio-driven framework RealTalk, which consists of an audio-to-expression transformer and a high-fidelity expression-to-face renderer. In the first component, we consider both identity and intra-personal variation features related to speaking lip movements. By incorporating cross-modal attention on the enriched facial priors, we can effectively align lip movements with audio, thus attaining greater precision in expression prediction. In the second component, we design a lightweight facial identity alignment (FIA) module which includes a lip-shape control structure and a face texture reference structure. This novel design allows us to generate fine details in real-time, without depending on sophisticated and inefficient feature alignment modules. Our experimental results, both quantitative and qualitative, on public datasets demonstrate the clear advantages of our method in terms of lip-speech synchronization and generation quality. Furthermore, our method is efficient and requires fewer computational resources, making it well-suited to meet the needs of practical applications.
ClotheDreamer: Text-Guided Garment Generation with 3D Gaussians
Jun 24, 2024High-fidelity 3D garment synthesis from text is desirable yet challenging for digital avatar creation. Recent diffusion-based approaches via Score Distillation Sampling (SDS) have enabled new possibilities but either intricately couple with human body or struggle to reuse. We introduce ClotheDreamer, a 3D Gaussian-based method for generating wearable, production-ready 3D garment assets from text prompts. We propose a novel representation Disentangled Clothe Gaussian Splatting (DCGS) to enable separate optimization. DCGS represents clothed avatar as one Gaussian model but freezes body Gaussian splats. To enhance quality and completeness, we incorporate bidirectional SDS to supervise clothed avatar and garment RGBD renderings respectively with pose conditions and propose a new pruning strategy for loose clothing. Our approach can also support custom clothing templates as input. Benefiting from our design, the synthetic 3D garment can be easily applied to virtual try-on and support physically accurate animation. Extensive experiments showcase our method's superior and competitive performance. Our project page is at https://ggxxii.github.io/clothedreamer.