 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF40: Toward Next-Generation Deepfake Detection
Paper and Code



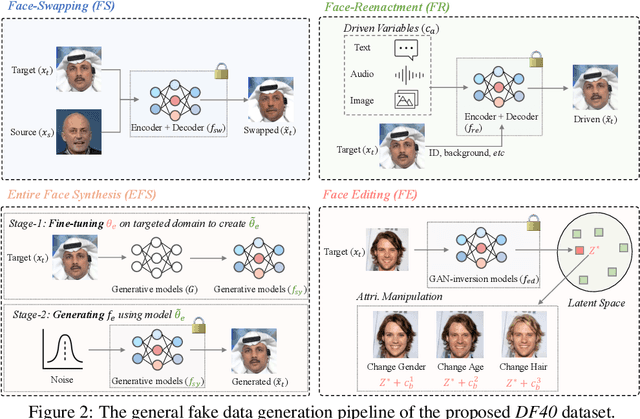
We propose a new comprehensive benchmark to revolutionize the current deepfake detection field to the next generation. Predominantly, existing works identify top-notch detection algorithms and models by adhering to the common practice: training detectors on one specific dataset (e.g., FF++) and testing them on other prevalent deepfake datasets. This protocol is often regarded as a "golden compass" for navigating SoTA detectors. But can these stand-out "winners" be truly applied to tackle the myriad of realistic and diverse deepfakes lurking in the real world? If not, what underlying factors contribute to this gap? In this work, we found the dataset (both train and test) can be the "primary culprit" due to: (1) forgery diversity: Deepfake techniques are commonly referred to as both face forgery (face-swapping and face-reenactment) and entire image synthesis (AIGC). Most existing datasets only contain partial types, with limited forgery methods implemented; (2) forgery realism: The dominant training dataset, FF++, contains old forgery techniques from the past five years. "Honing skills" on these forgeries makes it difficult to guarantee effective detection of nowadays' SoTA deepfakes; (3) evaluation protocol: Most detection works perform evaluations on one type, e.g., train and test on face-swapping only, which hinders the development of universal deepfake detectors. To address this dilemma, we construct a highly diverse and large-scale deepfake dataset called DF40, which comprises 40 distinct deepfake techniques. We then conduct comprehensive evaluations using 4 standard evaluation protocols and 7 representative detectors, resulting in over 2,000 evaluations. Through these evaluations, we analyze from various perspectives, leading to 12 new insightful findings contributing to the field. We also open up 5 valuable yet previously underexplored research questions to inspire future works.