 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars
Feb 02, 2026Generating talking avatars is a fundamental task in video generation. Although existing methods can generate full-body talking avatars with simple human motion, extending this task to grounded human-object interaction (GHOI) remains an open challenge, requiring the avatar to perform text-aligned interactions with surrounding objects. This challenge stems from the need for environmental perception and the control-quality dilemma in GHOI generation. To address this, we propose a novel dual-stream framework, InteractAvatar, which decouples perception and planning from video synthesis for grounded human-object interaction. Leveraging detection to enhance environmental perception, we introduce a Perception and Interaction Module (PIM) to generate text-aligned interaction motions. Additionally, an Audio-Interaction Aware Generation Module (AIM) is proposed to synthesize vivid talking avatars performing object interactions. With a specially designed motion-to-video aligner, PIM and AIM share a similar network structure and enable parallel co-generation of motions and plausible videos, effectively mitigating the control-quality dilemma. Finally, we establish a benchmark, GroundedInter, for evaluating GHOI video generation. Extensive experiments and comparisons demonstrate the effectiveness of our method in generating grounded human-object interactions for talking avatars. Project page: https://interactavatar.github.io
PolyVivid: Vivid Multi-Subject Video Generation with Cross-Modal Interaction and Enhancement
Jun 09, 2025Despite recent advances in video generation, existing models still lack fine-grained controllability, especially for multi-subject customization with consistent identity and interaction. In this paper, we propose PolyVivid, a multi-subject video customization framework that enables flexible and identity-consistent generation. To establish accurate correspondences between subject images and textual entities, we design a VLLM-based text-image fusion module that embeds visual identities into the textual space for precise grounding. To further enhance identity preservation and subject interaction, we propose a 3D-RoPE-based enhancement module that enables structured bidirectional fusion between text and image embeddings. Moreover, we develop an attention-inherited identity injection module to effectively inject fused identity features into the video generation process, mitigating identity drift. Finally, we construct an MLLM-based data pipeline that combines MLLM-based grounding, segmentation, and a clique-based subject consolidation strategy to produce high-quality multi-subject data, effectively enhancing subject distinction and reducing ambiguity in downstream video generation. Extensive experiments demonstrate that PolyVivid achieves superior performance in identity fidelity, video realism, and subject alignment, outperforming existing open-source and commercial baselines.
HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation
May 08, 2025Customized video generation aims to produce videos featuring specific subjects under flexible user-defined conditions, yet existing methods often struggle with identity consistency and limited input modalities. In this paper, we propose HunyuanCustom, a multi-modal customized video generation framework that emphasizes subject consistency while supporting image, audio, video, and text conditions. Built upon HunyuanVideo, our model first addresses the image-text conditioned generation task by introducing a text-image fusion module based on LLaVA for enhanced multi-modal understanding, along with an image ID enhancement module that leverages temporal concatenation to reinforce identity features across frames. To enable audio- and video-conditioned generation, we further propose modality-specific condition injection mechanisms: an AudioNet module that achieves hierarchical alignment via spatial cross-attention, and a video-driven injection module that integrates latent-compressed conditional video through a patchify-based feature-alignment network. Extensive experiments on single- and multi-subject scenarios demonstrate that HunyuanCustom significantly outperforms state-of-the-art open- and closed-source methods in terms of ID consistency, realism, and text-video alignment. Moreover, we validate its robustness across downstream tasks, including audio and video-driven customized video generation. Our results highlight the effectiveness of multi-modal conditioning and identity-preserving strategies in advancing controllable video generation. All the code and models are available at https://hunyuancustom.github.io.
HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Talking Head Generation with Probabilistic Audio-to-Visual Diffusion Priors
Dec 07, 2022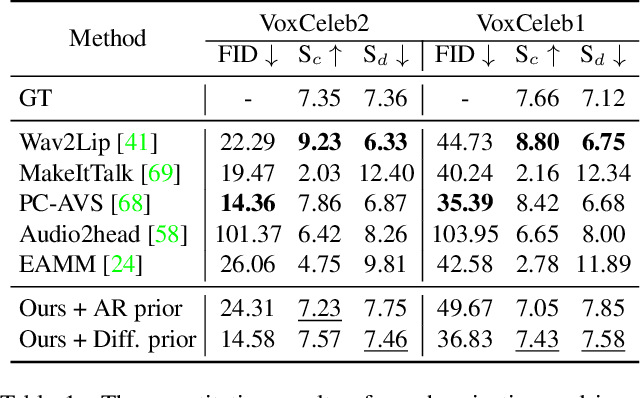
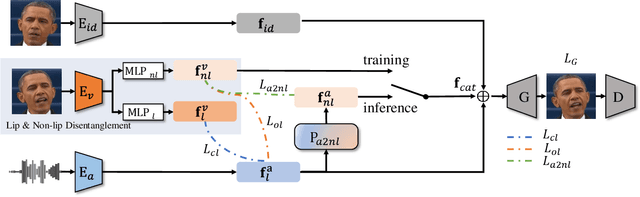
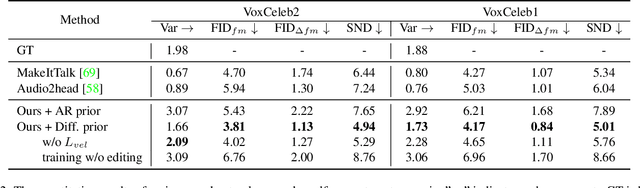
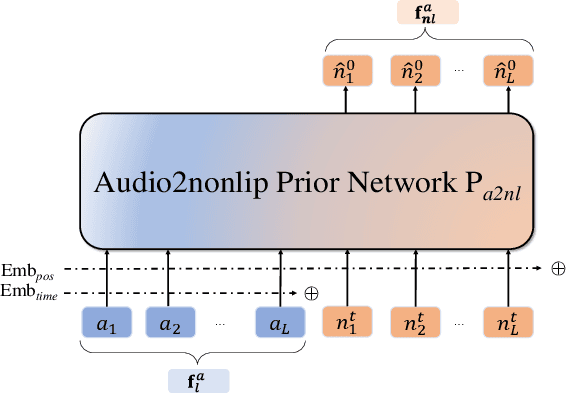
In this paper, we introduce a simple and novel framework for one-shot audio-driven talking head generation. Unlike prior works that require additional driving sources for controlled synthesis in a deterministic manner, we instead probabilistically sample all the holistic lip-irrelevant facial motions (i.e. pose, expression, blink, gaze, etc.) to semantically match the input audio while still maintaining both the photo-realism of audio-lip synchronization and the overall naturalness. This is achieved by our newly proposed audio-to-visual diffusion prior trained on top of the mapping between audio and disentangled non-lip facial representations. Thanks to the probabilistic nature of the diffusion prior, one big advantage of our framework is it can synthesize diverse facial motion sequences given the same audio clip, which is quite user-friendly for many real applications. Through comprehensive evaluations on public benchmarks, we conclude that (1) our diffusion prior outperforms auto-regressive prior significantly on almost all the concerned metrics; (2) our overall system is competitive with prior works in terms of audio-lip synchronization but can effectively sample rich and natural-looking lip-irrelevant facial motions while still semantically harmonized with the audio input.