 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Decoding: Mitigating Hallucinations in Large Vision-Language Models via History-Aware Residual Guidance
Feb 01, 2026Large Vision-Language Models (LVLMs) can reason effectively from image-text inputs and perform well in various multimodal tasks. Despite this success, they are affected by language priors and often produce hallucinations. Hallucinations denote generated content that is grammatically and syntactically coherent, yet bears no match or direct relevance to actual visual input. To address this problem, we propose Residual Decoding (ResDec). It is a novel training-free method that uses historical information to aid decoding. The method relies on the internal implicit reasoning mechanism and token logits evolution mechanism of LVLMs to correct biases. Extensive experiments demonstrate that ResDec effectively suppresses hallucinations induced by language priors, significantly improves visual grounding, and reduces object hallucinations. In addition to mitigating hallucinations, ResDec also performs exceptionally well on comprehensive LVLM benchmarks, highlighting its broad applicability.
HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
AD-H: Autonomous Driving with Hierarchical Agents
Jun 05, 2024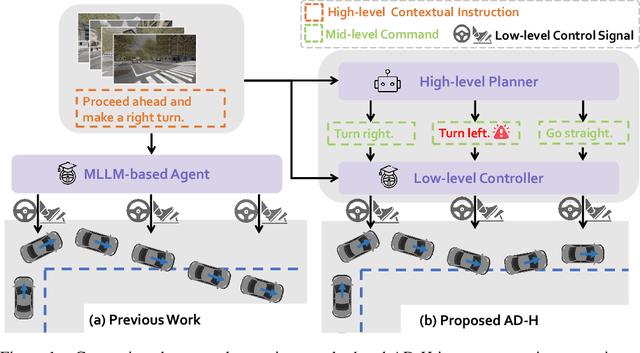

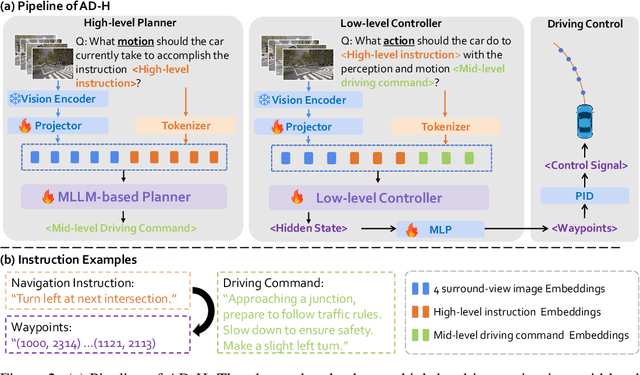

Due to the impressive capabilities of multimodal large language models (MLLMs), recent works have focused on employing MLLM-based agents for autonomous driving in large-scale and dynamic environments. However, prevalent approaches often directly translate high-level instructions into low-level vehicle control signals, which deviates from the inherent language generation paradigm of MLLMs and fails to fully harness their emergent powers. As a result, the generalizability of these methods is highly restricted by autonomous driving datasets used during fine-tuning. To tackle this challenge, we propose to connect high-level instructions and low-level control signals with mid-level language-driven commands, which are more fine-grained than high-level instructions but more universal and explainable than control signals, and thus can effectively bridge the gap in between. We implement this idea through a hierarchical multi-agent driving system named AD-H, including a MLLM planner for high-level reasoning and a lightweight controller for low-level execution. The hierarchical design liberates the MLLM from low-level control signal decoding and therefore fully releases their emergent capability in high-level perception, reasoning, and planning. We build a new dataset with action hierarchy annotations. Comprehensive closed-loop evaluations demonstrate several key advantages of our proposed AD-H system. First, AD-H can notably outperform state-of-the-art methods in achieving exceptional driving performance, even exhibiting self-correction capabilities during vehicle operation, a scenario not encountered in the training dataset. Second, AD-H demonstrates superior generalization under long-horizon instructions and novel environmental conditions, significantly surpassing current state-of-the-art methods. We will make our data and code publicly accessible at https://github.com/zhangzaibin/AD-H
PP-MobileSeg: Explore the Fast and Accurate Semantic Segmentation Model on Mobile Devices
Apr 11, 2023The success of transformers in computer vision has led to several attempts to adapt them for mobile devices, but their performance remains unsatisfactory in some real-world applications. To address this issue, we propose PP-MobileSeg, a semantic segmentation model that achieves state-of-the-art performance on mobile devices. PP-MobileSeg comprises three novel parts: the StrideFormer backbone, the Aggregated Attention Module (AAM), and the Valid Interpolate Module (VIM). The four-stage StrideFormer backbone is built with MV3 blocks and strided SEA attention, and it is able to extract rich semantic and detailed features with minimal parameter overhead. The AAM first filters the detailed features through semantic feature ensemble voting and then combines them with semantic features to enhance the semantic information. Furthermore, we proposed VIM to upsample the downsampled feature to the resolution of the input image. It significantly reduces model latency by only interpolating classes present in the final prediction, which is the most significant contributor to overall model latency. Extensive experiments show that PP-MobileSeg achieves a superior tradeoff between accuracy, model size, and latency compared to other methods. On the ADE20K dataset, PP-MobileSeg achieves 1.57% higher accuracy in mIoU than SeaFormer-Base with 32.9% fewer parameters and 42.3% faster acceleration on Qualcomm Snapdragon 855. Source codes are available at https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.8.
EISeg: An Efficient Interactive Segmentation Tool based on PaddlePaddle
Oct 18, 2022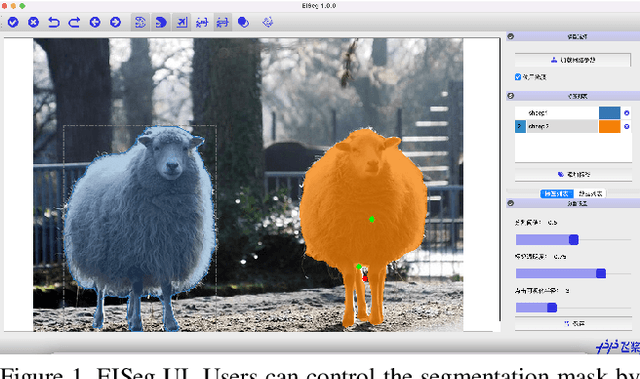

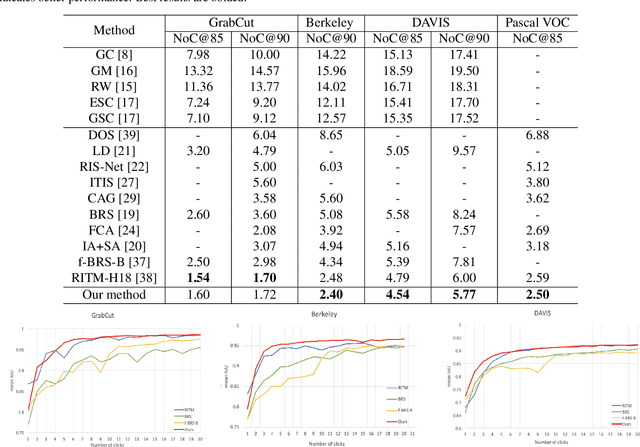
In recent years, the rapid development of deep learning has brought great advancements to image and video segmentation methods based on neural networks. However, to unleash the full potential of such models, large numbers of high-quality annotated images are necessary for model training. Currently, many widely used open-source image segmentation software relies heavily on manual annotation which is tedious and time-consuming. In this work, we introduce EISeg, an Efficient Interactive SEGmentation annotation tool that can drastically improve image segmentation annotation efficiency, generating highly accurate segmentation masks with only a few clicks. We also provide various domain-specific models for remote sensing, medical imaging, industrial quality inspections, human segmentation, and temporal aware models for video segmentation. The source code for our algorithm and user interface are available at: https://github.com/PaddlePaddle/PaddleSeg.
Exploring the Relationship between Architecture and Adversarially Robust Generalization
Sep 28, 2022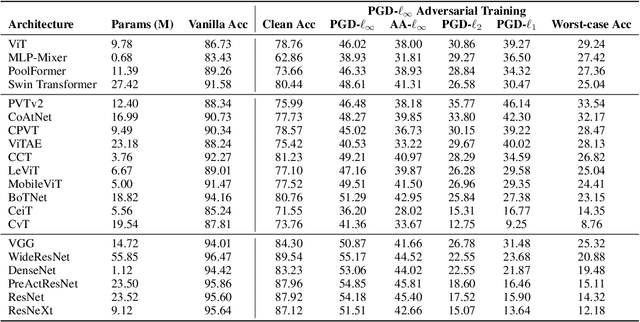
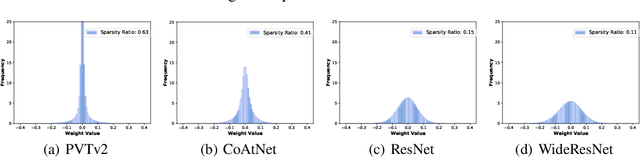
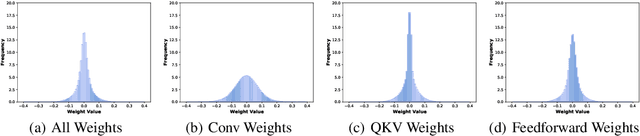

Adversarial training has been demonstrated to be one of the most effective remedies for defending adversarial examples, yet it often suffers from the huge robustness generalization gap on unseen testing adversaries, deemed as the \emph{adversarially robust generalization problem}. Despite the preliminary understandings devoted on adversarially robust generalization, little is known from the architectural perspective. Thus, this paper tries to bridge the gap by systematically examining the most representative architectures (e.g., Vision Transformers and CNNs). In particular, we first comprehensively evaluated \emph{20} adversarially trained architectures on ImageNette and CIFAR-10 datasets towards several adversaries (multiple $\ell_p$-norm adversarial attacks), and found that Vision Transformers (e.g., PVT, CoAtNet) often yield better adversarially robust generalization. To further understand what architectural ingredients favor adversarially robust generalization, we delve into several key building blocks and revealed the fact via the lens of Rademacher complexity that the higher weight sparsity contributes significantly towards the better adversarially robust generalization of Vision Transformers, which can be often achieved by attention layers. Our extensive studies discovered the close relationship between architectural design and adversarially robust generalization, and instantiated several important insights. We hope our findings could help to better understand the mechanism towards designing robust deep learning architectures.
PP-Matting: High-Accuracy Natural Image Matting
Apr 20, 2022
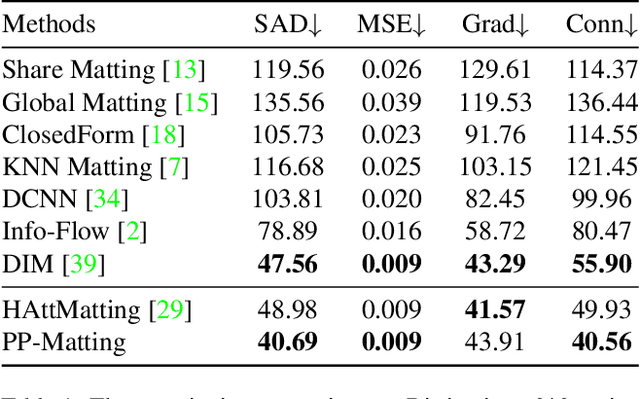
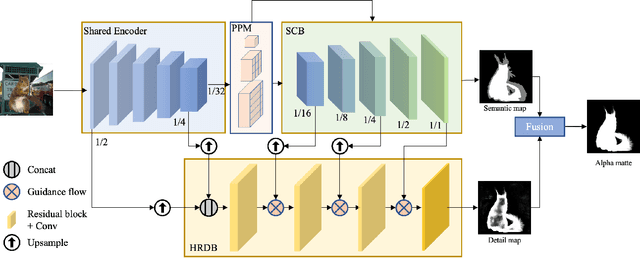
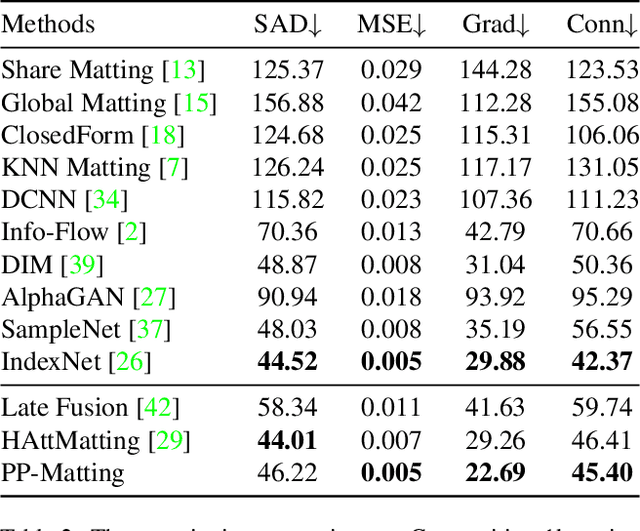
Natural image matting is a fundamental and challenging computer vision task. It has many applications in image editing and composition. Recently, deep learning-based approaches have achieved great improvements in image matting. However, most of them require a user-supplied trimap as an auxiliary input, which limits the matting applications in the real world. Although some trimap-free approaches have been proposed, the matting quality is still unsatisfactory compared to trimap-based ones. Without the trimap guidance, the matting models suffer from foreground-background ambiguity easily, and also generate blurry details in the transition area. In this work, we propose PP-Matting, a trimap-free architecture that can achieve high-accuracy natural image matting. Our method applies a high-resolution detail branch (HRDB) that extracts fine-grained details of the foreground with keeping feature resolution unchanged. Also, we propose a semantic context branch (SCB) that adopts a semantic segmentation subtask. It prevents the detail prediction from local ambiguity caused by semantic context missing. In addition, we conduct extensive experiments on two well-known benchmarks: Composition-1k and Distinctions-646. The results demonstrate the superiority of PP-Matting over previous methods. Furthermore, we provide a qualitative evaluation of our method on human matting which shows its outstanding performance in the practical application. The code and pre-trained models will be available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Apr 06, 2022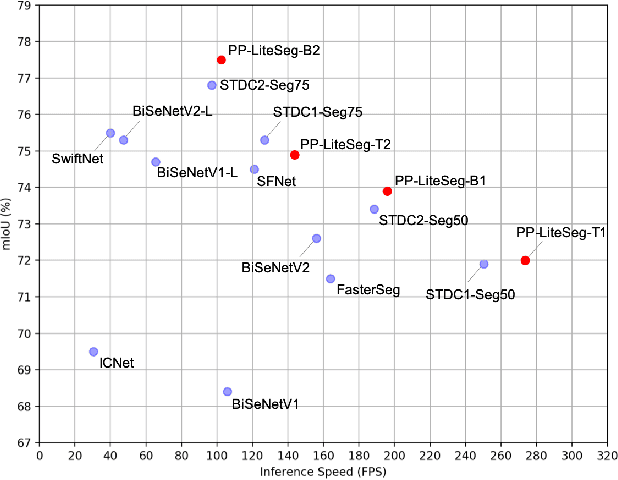

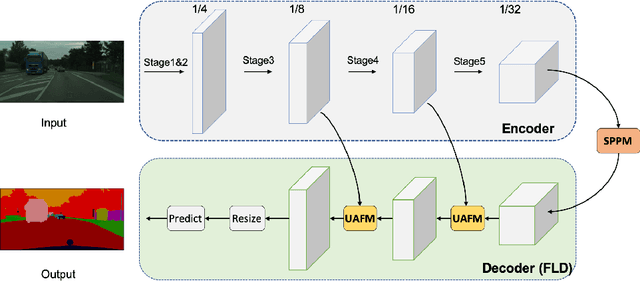
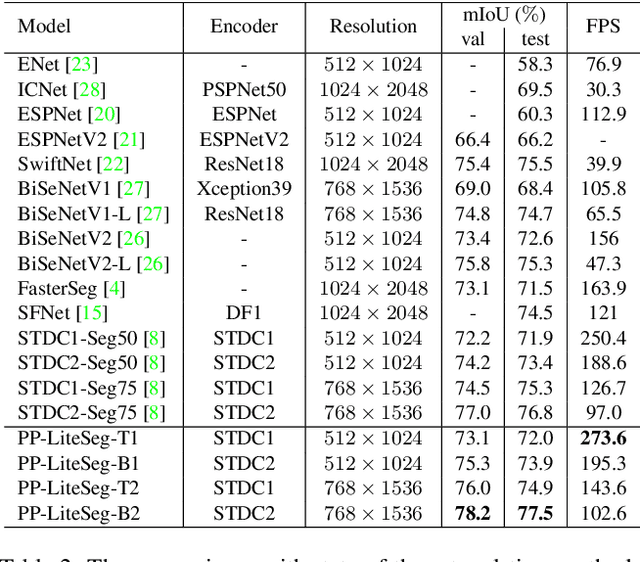
Real-world applications have high demands for semantic segmentation methods. Although semantic segmentation has made remarkable leap-forwards with deep learning, the performance of real-time methods is not satisfactory. In this work, we propose PP-LiteSeg, a novel lightweight model for the real-time semantic segmentation task. Specifically, we present a Flexible and Lightweight Decoder (FLD) to reduce computation overhead of previous decoder. To strengthen feature representations, we propose a Unified Attention Fusion Module (UAFM), which takes advantage of spatial and channel attention to produce a weight and then fuses the input features with the weight. Moreover, a Simple Pyramid Pooling Module (SPPM) is proposed to aggregate global context with low computation cost. Extensive evaluations demonstrate that PP-LiteSeg achieves a superior trade-off between accuracy and speed compared to other methods. On the Cityscapes test set, PP-LiteSeg achieves 72.0% mIoU/273.6 FPS and 77.5% mIoU/102.6 FPS on NVIDIA GTX 1080Ti. Source code and models are available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.
PP-HumanSeg: Connectivity-Aware Portrait Segmentation with a Large-Scale Teleconferencing Video Dataset
Dec 14, 2021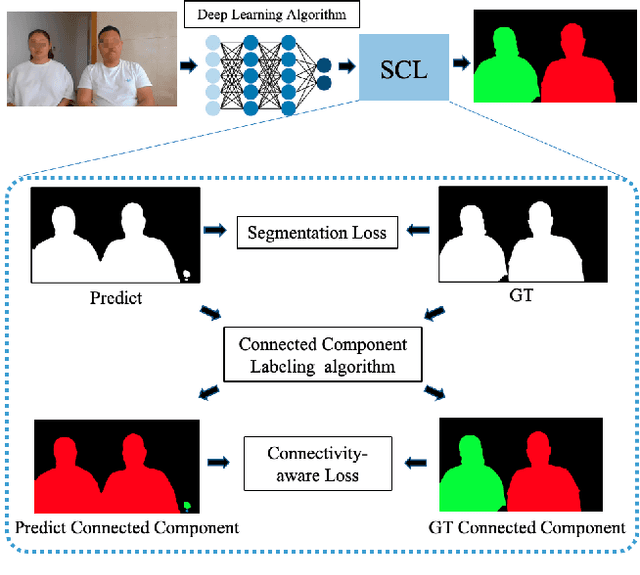


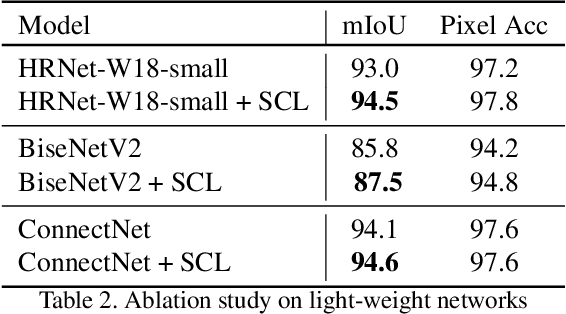
As the COVID-19 pandemic rampages across the world, the demands of video conferencing surge. To this end, real-time portrait segmentation becomes a popular feature to replace backgrounds of conferencing participants. While feature-rich datasets, models and algorithms have been offered for segmentation that extract body postures from life scenes, portrait segmentation has yet not been well covered in a video conferencing context. To facilitate the progress in this field, we introduce an open-source solution named PP-HumanSeg. This work is the first to construct a large-scale video portrait dataset that contains 291 videos from 23 conference scenes with 14K fine-labeled frames and extensions to multi-camera teleconferencing. Furthermore, we propose a novel Semantic Connectivity-aware Learning (SCL) for semantic segmentation, which introduces a semantic connectivity-aware loss to improve the quality of segmentation results from the perspective of connectivity. And we propose an ultra-lightweight model with SCL for practical portrait segmentation, which achieves the best trade-off between IoU and the speed of inference. Extensive evaluations on our dataset demonstrate the superiority of SCL and our model. The source code is available at https://github.com/PaddlePaddle/PaddleSeg.
EdgeFlow: Achieving Practical Interactive Segmentation with Edge-Guided Flow
Sep 20, 2021
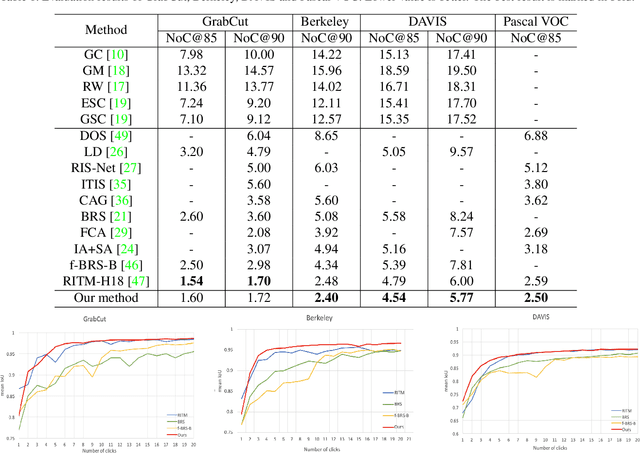
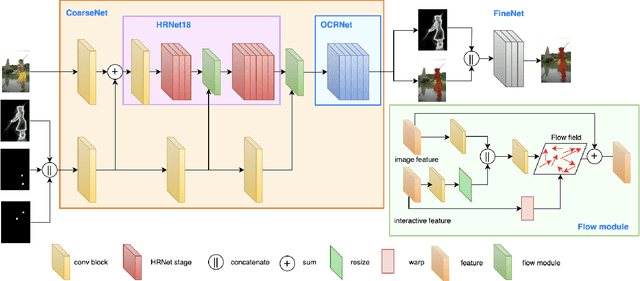

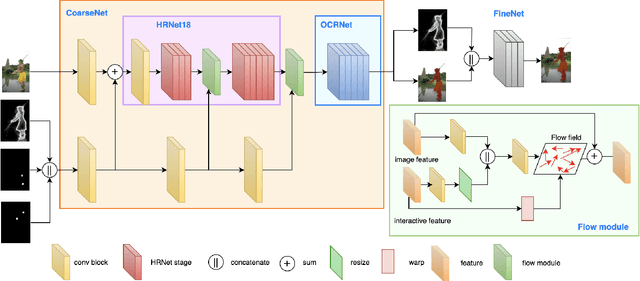
High-quality training data play a key role in image segmentation tasks. Usually, pixel-level annotations are expensive, laborious and time-consuming for the large volume of training data. To reduce labelling cost and improve segmentation quality, interactive segmentation methods have been proposed, which provide the result with just a few clicks. However, their performance does not meet the requirements of practical segmentation tasks in terms of speed and accuracy. In this work, we propose EdgeFlow, a novel architecture that fully utilizes interactive information of user clicks with edge-guided flow. Our method achieves state-of-the-art performance without any post-processing or iterative optimization scheme. Comprehensive experiments on benchmarks also demonstrate the superiority of our method. In addition, with the proposed method, we develop an efficient interactive segmentation tool for practical data annotation tasks. The source code and tool is avaliable at https://github.com/PaddlePaddle/PaddleSeg.