 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship between Architecture and Adversarially Robust Generalization
Paper and Code
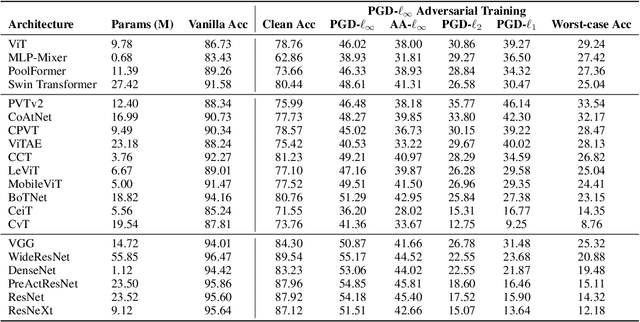
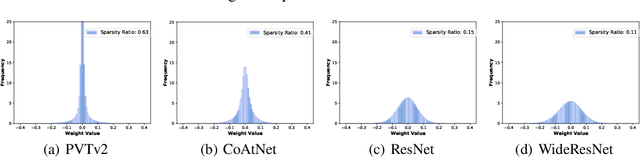
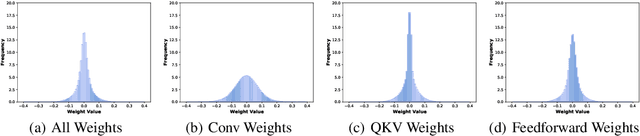

Adversarial training has been demonstrated to be one of the most effective remedies for defending adversarial examples, yet it often suffers from the huge robustness generalization gap on unseen testing adversaries, deemed as the \emph{adversarially robust generalization problem}. Despite the preliminary understandings devoted on adversarially robust generalization, little is known from the architectural perspective. Thus, this paper tries to bridge the gap by systematically examining the most representative architectures (e.g., Vision Transformers and CNNs). In particular, we first comprehensively evaluated \emph{20} adversarially trained architectures on ImageNette and CIFAR-10 datasets towards several adversaries (multiple $\ell_p$-norm adversarial attacks), and found that Vision Transformers (e.g., PVT, CoAtNet) often yield better adversarially robust generalization. To further understand what architectural ingredients favor adversarially robust generalization, we delve into several key building blocks and revealed the fact via the lens of Rademacher complexity that the higher weight sparsity contributes significantly towards the better adversarially robust generalization of Vision Transformers, which can be often achieved by attention layers. Our extensive studies discovered the close relationship between architectural design and adversarially robust generalization, and instantiated several important insights. We hope our findings could help to better understand the mechanism towards designing robust deep learning architectures.