 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Few-Step Distillation and Low-Bit Quantization for Wan2.2 Dual-Expert Video Diffusion Models
May 30, 2026Large video diffusion models achieve strong visual quality but remain expensive to deploy because each sample requires many denoising steps and a large resident parameter footprint. This paper studies a deployment-oriented compression pipeline for Wan2.2-T2V-A14B by combining few-step distribution-matching distillation with low-bit quantization. The pipeline follows the model's dual-expert denoising route, calibrates the high-noise and low-noise branches separately, protects sensitive entrance layers, and uses HiF4-style low-bit representation to improve dynamic-range coverage. Quantization is calibrated on the distilled few-step student rather than on the original long-step trajectory, reducing activation-distribution mismatch during inference. The proposed co-design keeps the quantized model close to the same-step full-precision model and surpasses the original full-precision baseline at 8 and 20 steps on average. The 20-step setting gives the best quality-efficiency trade-off in the tested configurations.
Incremental BPE Tokenization
May 29, 2026We propose a novel algorithm for incremental Byte Pair Encoding (BPE) tokenization. The algorithm processes each input byte in worst-case $\mathcal{O}(\log^2 t)$ time, leading to an overall complexity of $\mathcal{O}(n \log^2 t)$, where $n$ is the input length and $t$ is the maximum token length. The algorithm incrementally maintains BPE tokenization results for every prefix of the input text, implementing the standard BPE merge procedure defined by a fixed set of merge rules. This enables efficient partial tokenization in streaming settings. Functioning as a drop-in replacement for standard BPE, our approach achieves a speedup of up to ${\sim}3\times$ over Hugging Face's tokenizers, and demonstrates significant latency reductions over OpenAI's tiktoken on pathological inputs. We further introduce an eager output algorithm that enables streaming output, emitting tokens as soon as token boundaries are determined during incremental tokenization. Overall, our results demonstrate that BPE tokenization can be performed incrementally with strong worst-case guarantees, while providing practical latency benefits in modern large language model pipelines. Code: https://github.com/ModelTC/mtc-inc-bpe
SGMD: Score Gradient Matching Distillation for Few-Step Video Diffusion Distillation
May 28, 2026Distribution Matching Distillation (DMD) is a widely used paradigm for accelerating inference in few-step video diffusion models. However, DMD-style video distillation faces two coupled challenges: the fake score must track a continuously evolving generator, making training costly when frequent updates are required, while reverse-KL-style matching can be mode-seeking and conservative for preserving strong motion dynamics. To address these issues, we propose \textbf{Score Gradient Matching Distillation (SGMD)}. SGMD adopts a fake-score perspective by directly optimizing the fake score toward the teacher, while using teacher stop-gradient Fisher as a stable distribution-matching objective. We provide a gradient analysis that motivates this objective choice under ideal tracking. Building on this, SGMD introduces a pair of dual potentials: negative-residual (NR) for outer-loop correction and residual-contraction (RC) for inner-loop tracking. Empirically, compared to DMD2, SGMD achieves an approximately $\sim 3\times$ training speedup and substantially improves motion dynamics for 4-step distilled models while preserving temporal consistency. A human study confirms that SGMD is preferred in motion quality and overall preference, while visual quality and text alignment remain comparable. Code is available at https://github.com/ModelTC/LightX2V.
SenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
InCoder-32B-Thinking: Industrial Code World Model for Thinking
Apr 03, 2026Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Feb 04, 2026Advanced autoregressive (AR) video generation models have improved visual fidelity and interactivity, but the quadratic complexity of attention remains a primary bottleneck for efficient deployment. While existing sparse attention solutions have shown promise on bidirectional models, we identify that applying these solutions to AR models leads to considerable performance degradation for two reasons: isolated consideration of chunk generation and insufficient utilization of past informative context. Motivated by these observations, we propose \textsc{Light Forcing}, the \textit{first} sparse attention solution tailored for AR video generation models. It incorporates a \textit{Chunk-Aware Growth} mechanism to quantitatively estimate the contribution of each chunk, which determines their sparsity allocation. This progressive sparsity increase strategy enables the current chunk to inherit prior knowledge in earlier chunks during generation. Additionally, we introduce a \textit{Hierarchical Sparse Attention} to capture informative historical and local context in a coarse-to-fine manner. Such two-level mask selection strategy (\ie, frame and block level) can adaptively handle diverse attention patterns. Extensive experiments demonstrate that our method outperforms existing sparse attention in quality (\eg, 84.5 on VBench) and efficiency (\eg, $1.2{\sim}1.3\times$ end-to-end speedup). Combined with FP8 quantization and LightVAE, \textsc{Light Forcing} further achieves a $2.3\times$ speedup and 19.7\,FPS on an RTX~5090 GPU. Code will be released at \href{https://github.com/chengtao-lv/LightForcing}{https://github.com/chengtao-lv/LightForcing}.
Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
Feb 02, 2026Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping
Nov 19, 2025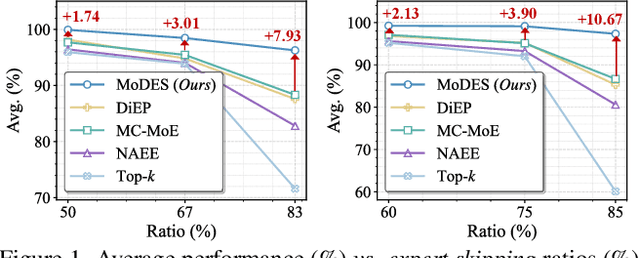

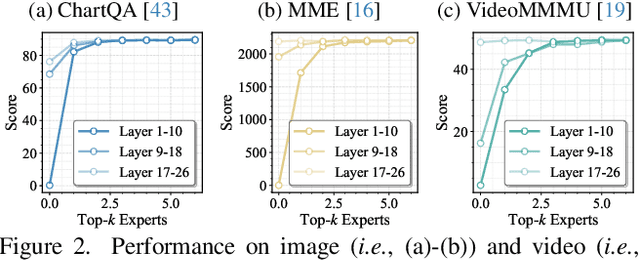
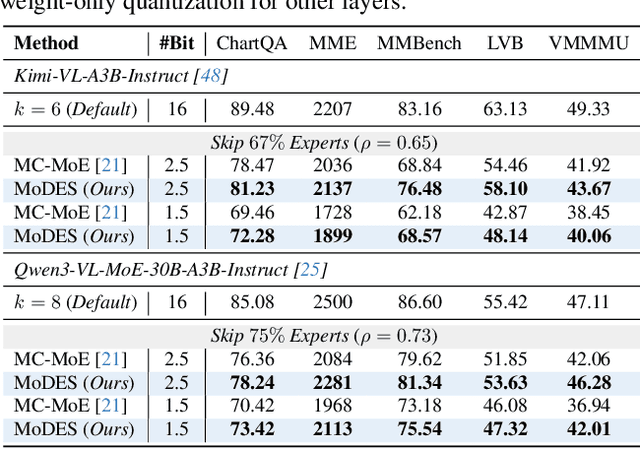
Mixture-of-Experts (MoE) Multimodal large language models (MLLMs) excel at vision-language tasks, but they suffer from high computational inefficiency. To reduce inference overhead, expert skipping methods have been proposed to deactivate redundant experts based on the current input tokens. However, we find that applying these methods-originally designed for unimodal large language models (LLMs)-to MLLMs results in considerable performance degradation. This is primarily because such methods fail to account for the heterogeneous contributions of experts across MoE layers and modality-specific behaviors of tokens within these layers. Motivated by these findings, we propose MoDES, the first training-free framework that adaptively skips experts to enable efficient and accurate MoE MLLM inference. It incorporates a globally-modulated local gating (GMLG) mechanism that integrates global layer-wise importance into local routing probabilities to accurately estimate per-token expert importance. A dual-modality thresholding (DMT) method is then applied, which processes tokens from each modality separately, to derive the skipping schedule. To set the optimal thresholds, we introduce a frontier search algorithm that exploits monotonicity properties, cutting convergence time from several days to a few hours. Extensive experiments for 3 model series across 13 benchmarks demonstrate that MoDES far outperforms previous approaches. For instance, when skipping 88% experts for Qwen3-VL-MoE-30B-A3B-Instruct, the performance boost is up to 10.67% (97.33% vs. 86.66%). Furthermore, MoDES significantly enhances inference speed, improving the prefilling time by 2.16$\times$ and the decoding time by 1.26$\times$.