 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniBal: Towards Fast Instruct-tuning for Vision-Language Models via Omniverse Computation Balance
Paper and Code
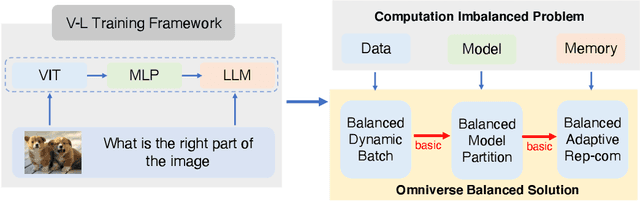

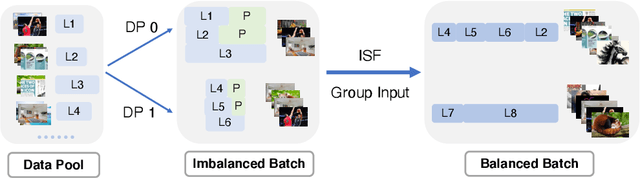

Recently, vision-language instruct-tuning models have made significant progress due to their more comprehensive understanding of the world. In this work, we discovered that large-scale 3D parallel training on those models leads to an imbalanced computation load across different devices. The vision and language parts are inherently heterogeneous: their data distribution and model architecture differ significantly, which affects distributed training efficiency. We rebalanced the computational loads from data, model, and memory perspectives to address this issue, achieving more balanced computation across devices. These three components are not independent but are closely connected, forming an omniverse balanced training framework. Specifically, for the data, we grouped instances into new balanced mini-batches within and across devices. For the model, we employed a search-based method to achieve a more balanced partitioning. For memory optimization, we adaptively adjusted the re-computation strategy for each partition to utilize the available memory fully. We conducted extensive experiments to validate the effectiveness of our method. Compared with the open-source training code of InternVL-Chat, we significantly reduced GPU days, achieving about 1.8x speed-up. Our method's efficacy and generalizability were further demonstrated across various models and datasets. Codes will be released at https://github.com/ModelTC/OmniBal.