 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Decoder Adapter: ID-Preserving Tokenizer Adaption for Autoregressive Text Rendering
Jun 01, 2026Visual Autoregressive (AR) models generate images by predicting discrete tokens that are decoded by a visual tokenizer. Despite demonstrating strong overall image generation ability, they still underperform on text rendering with blur strokes and disrupt letter shapes. In this work, we trace this limitation to the visual tokenizer, which struggles to reconstruct fine-grained detail. Improving the tokenizer is straightforward but expensive, as it necessitates retraining both the tokenizer and the AR model. Can we improve text rendering performance of AR models without retraining the existing tokenizer and AR model? To achieve this, we propose the Residual Decoder Adapter(RDA) that upgrades an existing tokenizer post-hoc without changing its token space. Specifically, it refines the decoder output of the visual tokenizer by introducing two novel components: (i) a paired codebook that shares the token distribution with the original one; (ii) a parallel branch to learn the tiny differences (residual) between the reconstructed image and the ground-truth images in the pixel space. This residual design allows us to enhance the tokenizer non-invasively while preserving compatibility with prior AR models. RDA substantially improves text rendering significantly by a large margin. For instance, we boost finetuned Janus-Pro OCR accuracy rises from 24.52% to 58.26% (TextVisionBlend), from 12.75% to 36.81% (StyledTextSynth) on competitive TextAtlas benchmark. The code is available at https://github.com/CSU-JPG/RDA
Hierarchical Balance Packing: Towards Efficient Supervised Fine-tuning for Long-Context LLM
Mar 10, 2025Training Long-Context Large Language Models (LLMs) is challenging, as hybrid training with long-context and short-context data often leads to workload imbalances. Existing works mainly use data packing to alleviate this issue but fail to consider imbalanced attention computation and wasted communication overhead. This paper proposes Hierarchical Balance Packing (HBP), which designs a novel batch-construction method and training recipe to address those inefficiencies. In particular, the HBP constructs multi-level data packing groups, each optimized with a distinct packing length. It assigns training samples to their optimal groups and configures each group with the most effective settings, including sequential parallelism degree and gradient checkpointing configuration. To effectively utilize multi-level groups of data, we design a dynamic training pipeline specifically tailored to HBP, including curriculum learning, adaptive sequential parallelism, and stable loss. Our extensive experiments demonstrate that our method significantly reduces training time over multiple datasets and open-source models while maintaining strong performance. For the largest DeepSeek-V2 (236B) MOE model, our method speeds up the training by 2.4$\times$ with competitive performance.
OmniBal: Towards Fast Instruct-tuning for Vision-Language Models via Omniverse Computation Balance
Jul 30, 2024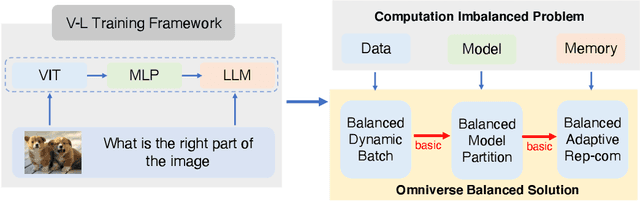

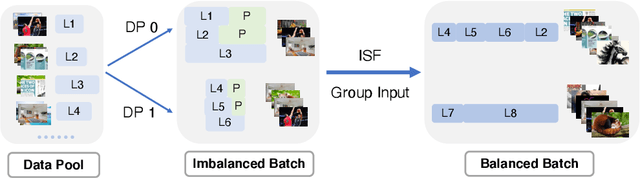

Recently, vision-language instruct-tuning models have made significant progress due to their more comprehensive understanding of the world. In this work, we discovered that large-scale 3D parallel training on those models leads to an imbalanced computation load across different devices. The vision and language parts are inherently heterogeneous: their data distribution and model architecture differ significantly, which affects distributed training efficiency. We rebalanced the computational loads from data, model, and memory perspectives to address this issue, achieving more balanced computation across devices. These three components are not independent but are closely connected, forming an omniverse balanced training framework. Specifically, for the data, we grouped instances into new balanced mini-batches within and across devices. For the model, we employed a search-based method to achieve a more balanced partitioning. For memory optimization, we adaptively adjusted the re-computation strategy for each partition to utilize the available memory fully. We conducted extensive experiments to validate the effectiveness of our method. Compared with the open-source training code of InternVL-Chat, we significantly reduced GPU days, achieving about 1.8x speed-up. Our method's efficacy and generalizability were further demonstrated across various models and datasets. Codes will be released at https://github.com/ModelTC/OmniBal.
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Apr 04, 2023



Action understanding matters and attracts attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a Poincare action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging "isolated islands" into a "Pangea". Accordingly, we propose a bidirectional mapping model between physical and semantic space to fully use Pangea. In extensive experiments, our system shows significant superiority, especially in transfer learning. Code and data will be made publicly available.
The Equalization Losses: Gradient-Driven Training for Long-tailed Object Recognition
Oct 11, 2022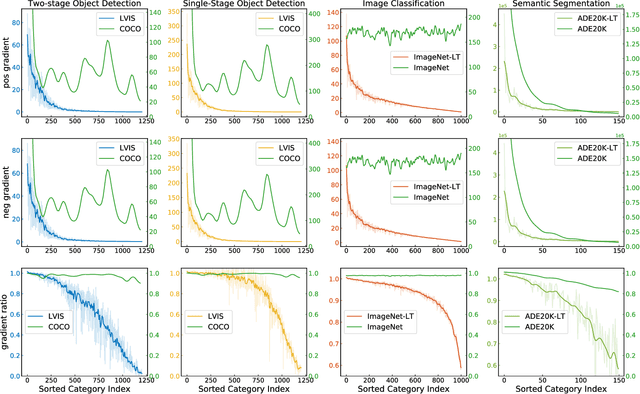
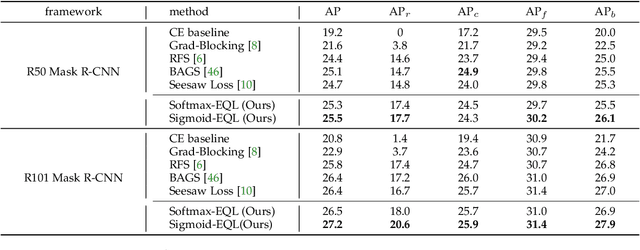

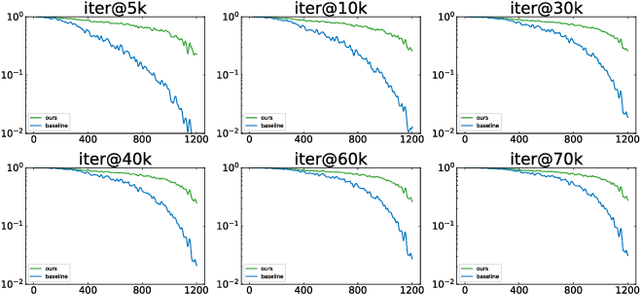
Long-tail distribution is widely spread in real-world applications. Due to the extremely small ratio of instances, tail categories often show inferior accuracy. In this paper, we find such performance bottleneck is mainly caused by the imbalanced gradients, which can be categorized into two parts: (1) positive part, deriving from the samples of the same category, and (2) negative part, contributed by other categories. Based on comprehensive experiments, it is also observed that the gradient ratio of accumulated positives to negatives is a good indicator to measure how balanced a category is trained. Inspired by this, we come up with a gradient-driven training mechanism to tackle the long-tail problem: re-balancing the positive/negative gradients dynamically according to current accumulative gradients, with a unified goal of achieving balance gradient ratios. Taking advantage of the simple and flexible gradient mechanism, we introduce a new family of gradient-driven loss functions, namely equalization losses. We conduct extensive experiments on a wide spectrum of visual tasks, including two-stage/single-stage long-tailed object detection (LVIS), long-tailed image classification (ImageNet-LT, Places-LT, iNaturalist), and long-tailed semantic segmentation (ADE20K). Our method consistently outperforms the baseline models, demonstrating the effectiveness and generalization ability of the proposed equalization losses. Codes will be released at https://github.com/ModelTC/United-Perception.
Improving Long-tailed Object Detection with Image-Level Supervision by Multi-Task Collaborative Learning
Oct 11, 2022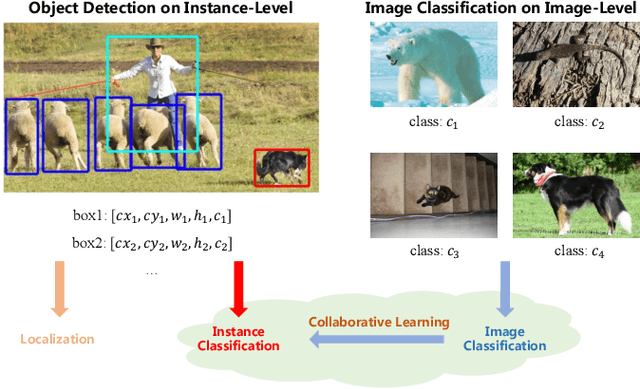
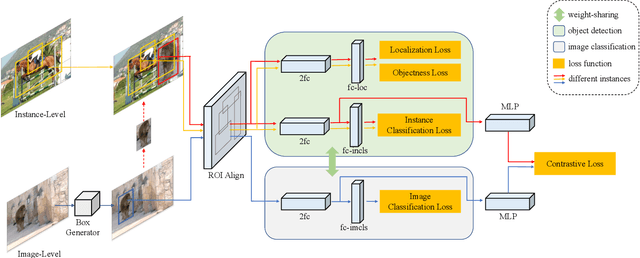
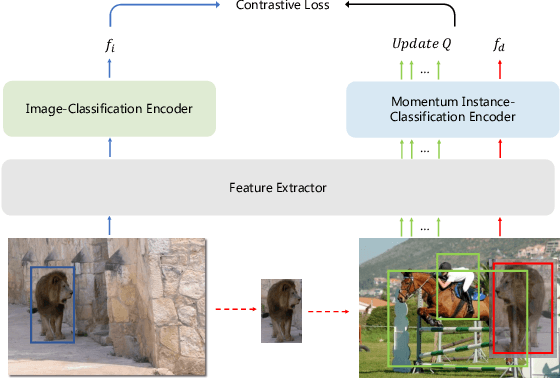

Data in real-world object detection often exhibits the long-tailed distribution. Existing solutions tackle this problem by mitigating the competition between the head and tail categories. However, due to the scarcity of training samples, tail categories are still unable to learn discriminative representations. Bringing more data into the training may alleviate the problem, but collecting instance-level annotations is an excruciating task. In contrast, image-level annotations are easily accessible but not fully exploited. In this paper, we propose a novel framework CLIS (multi-task Collaborative Learning with Image-level Supervision), which leverage image-level supervision to enhance the detection ability in a multi-task collaborative way. Specifically, there are an object detection task (consisting of an instance-classification task and a localization task) and an image-classification task in our framework, responsible for utilizing the two types of supervision. Different tasks are trained collaboratively by three key designs: (1) task-specialized sub-networks that learn specific representations of different tasks without feature entanglement. (2) a siamese sub-network for the image-classification task that shares its knowledge with the instance-classification task, resulting in feature enrichment of detectors. (3) a contrastive learning regularization that maintains representation consistency, bridging feature gaps of different supervision. Extensive experiments are conducted on the challenging LVIS dataset. Without sophisticated loss engineering, CLIS achieves an overall AP of 31.1 with 10.1 point improvement on tail categories, establishing a new state-of-the-art. Code will be at https://github.com/waveboo/CLIS.
Equalized Focal Loss for Dense Long-Tailed Object Detection
Jan 07, 2022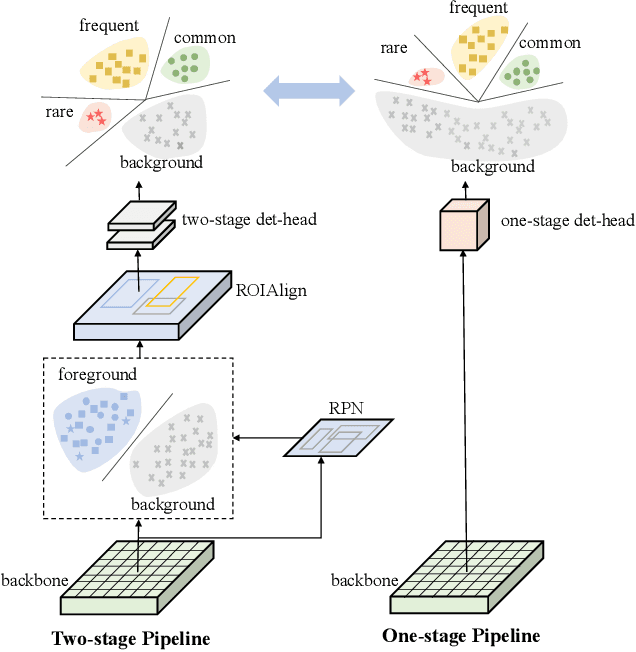
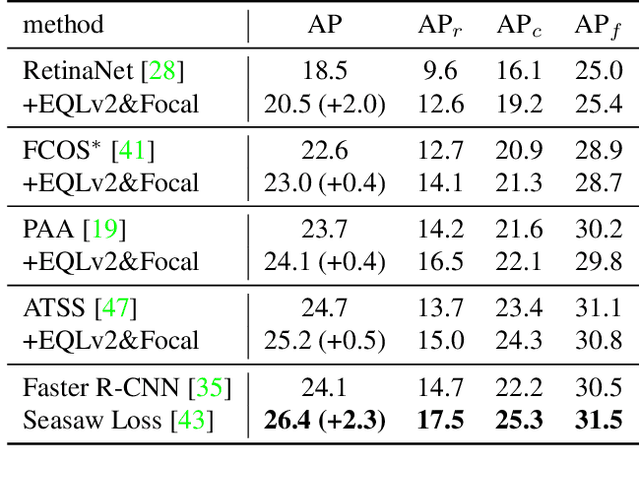
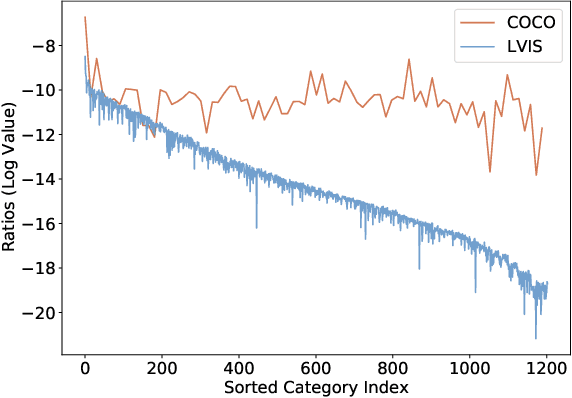
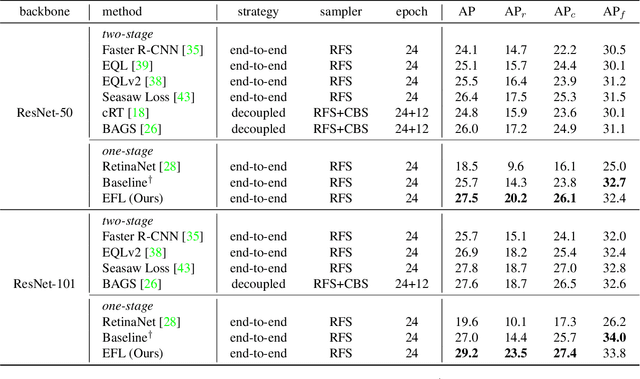
Despite the recent success of long-tailed object detection, almost all long-tailed object detectors are developed based on the two-stage paradigm. In practice, one-stage detectors are more prevalent in the industry because they have a simple and fast pipeline that is easy to deploy. However, in the long-tailed scenario, this line of work has not been explored so far. In this paper, we investigate whether one-stage detectors can perform well in this case. We discover the primary obstacle that prevents one-stage detectors from achieving excellent performance is: categories suffer from different degrees of positive-negative imbalance problems under the long-tailed data distribution. The conventional focal loss balances the training process with the same modulating factor for all categories, thus failing to handle the long-tailed problem. To address this issue, we propose the Equalized Focal Loss (EFL) that rebalances the loss contribution of positive and negative samples of different categories independently according to their imbalance degrees. Specifically, EFL adopts a category-relevant modulating factor which can be adjusted dynamically by the training status of different categories. Extensive experiments conducted on the challenging LVIS v1 benchmark demonstrate the effectiveness of our proposed method. With an end-to-end training pipeline, EFL achieves 29.2% in terms of overall AP and obtains significant performance improvements on rare categories, surpassing all existing state-of-the-art methods. The code is available at https://github.com/ModelTC/EOD.
RefineMask: Towards High-Quality Instance Segmentation with Fine-Grained Features
Apr 17, 2021
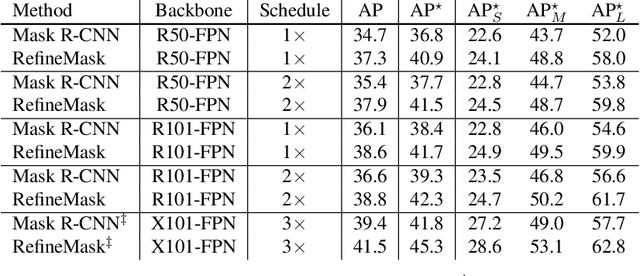
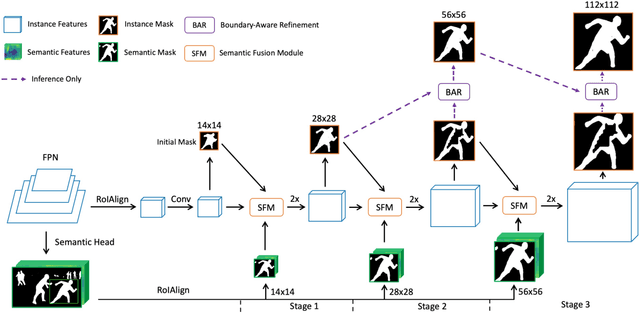
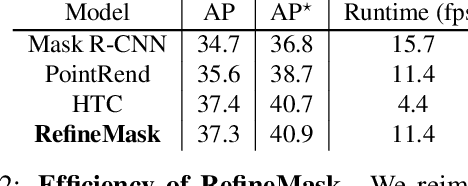
The two-stage methods for instance segmentation, e.g. Mask R-CNN, have achieved excellent performance recently. However, the segmented masks are still very coarse due to the downsampling operations in both the feature pyramid and the instance-wise pooling process, especially for large objects. In this work, we propose a new method called RefineMask for high-quality instance segmentation of objects and scenes, which incorporates fine-grained features during the instance-wise segmenting process in a multi-stage manner. Through fusing more detailed information stage by stage, RefineMask is able to refine high-quality masks consistently. RefineMask succeeds in segmenting hard cases such as bent parts of objects that are over-smoothed by most previous methods and outputs accurate boundaries. Without bells and whistles, RefineMask yields significant gains of 2.6, 3.4, 3.8 AP over Mask R-CNN on COCO, LVIS, and Cityscapes benchmarks respectively at a small amount of additional computational cost. Furthermore, our single-model result outperforms the winner of the LVIS Challenge 2020 by 1.3 points on the LVIS test-dev set and establishes a new state-of-the-art. Code will be available at https://github.com/zhanggang001/RefineMask.
Equalization Loss v2: A New Gradient Balance Approach for Long-tailed Object Detection
Dec 15, 2020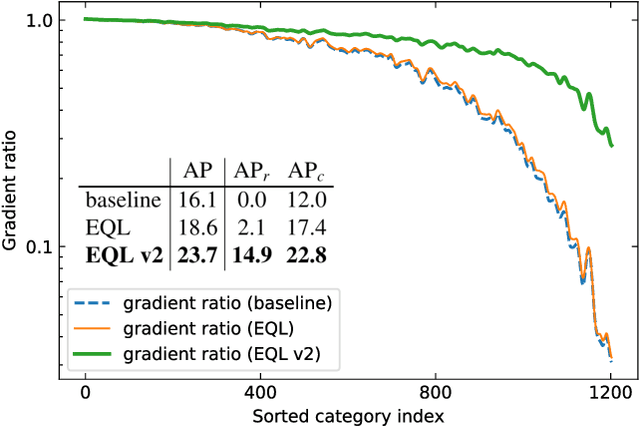

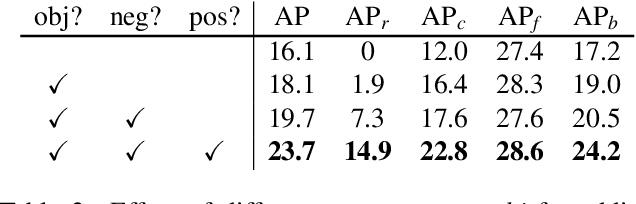
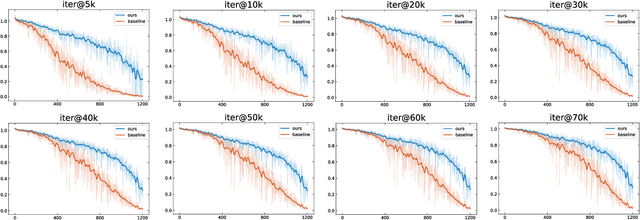
Recently proposed decoupled training methods emerge as a dominant paradigm for long-tailed object detection. But they require an extra fine-tuning stage, and the disjointed optimization of representation and classifier might lead to suboptimal results. However, end-to-end training methods, like equalization loss (EQL), still perform worse than decoupled training methods. In this paper, we reveal the main issue in long-tailed object detection is the imbalanced gradients between positives and negatives, and find that EQL does not solve it well. To address the problem of imbalanced gradients, we introduce a new version of equalization loss, called equalization loss v2 (EQL v2), a novel gradient guided reweighing mechanism that re-balances the training process for each category independently and equally. Extensive experiments are performed on the challenging LVIS benchmark. EQL v2 outperforms origin EQL by about 4 points overall AP with 14-18 points improvements on the rare categories. More importantly, It also surpasses decoupled training methods. Without further tuning for the Open Images dataset, EQL v2 improves EQL by 6.3 points AP, showing strong generalization ability. Codes will be released at https://github.com/tztztztztz/eqlv2
1st Place Solution of LVIS Challenge 2020: A Good Box is not a Guarantee of a Good Mask
Sep 03, 2020This article introduces the solutions of the team lvisTraveler for LVIS Challenge 2020. In this work, two characteristics of LVIS dataset are mainly considered: the long-tailed distribution and high quality instance segmentation mask. We adopt a two-stage training pipeline. In the first stage, we incorporate EQL and self-training to learn generalized representation. In the second stage, we utilize Balanced GroupSoftmax to promote the classifier, and propose a novel proposal assignment strategy and a new balanced mask loss for mask head to get more precise mask predictions. Finally, we achieve 41.5 and 41.2 AP on LVIS v1.0 val and test-dev splits respectively, outperforming the baseline based on X101-FPN-MaskRCNN by a large margin.