 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
daVinci-LLM:Towards the Science of Pretraining
Mar 28, 2026The foundational pretraining phase determines a model's capability ceiling, as post-training struggles to overcome capability foundations established during pretraining, yet it remains critically under-explored. This stems from a structural paradox: organizations with computational resources operate under commercial pressures that inhibit transparent disclosure, while academic institutions possess research freedom but lack pretraining-scale computational resources. daVinci-LLM occupies this unexplored intersection, combining industrial-scale resources with full research freedom to advance the science of pretraining. We adopt a fully-open paradigm that treats openness as scientific methodology, releasing complete data processing pipelines, full training processes, and systematic exploration results. Recognizing that the field lacks systematic methodology for data processing, we employ the Data Darwinism framework, a principled L0-L9 taxonomy from filtering to synthesis. We train a 3B-parameter model from random initialization across 8T tokens using a two-stage adaptive curriculum that progressively shifts from foundational capabilities to reasoning-intensive enhancement. Through 200+ controlled ablations, we establish that: processing depth systematically enhances capabilities, establishing it as a critical dimension alongside volume scaling; different domains exhibit distinct saturation dynamics, necessitating adaptive strategies from proportion adjustments to format shifts; compositional balance enables targeted intensification while preventing performance collapse; how evaluation protocol choices shape our understanding of pretraining progress. By releasing the complete exploration process, we enable the community to build upon our findings and systematic methodologies to form accumulative scientific knowledge in pretraining.
Uncertainty-Adjusted Sorting for Asset Pricing with Machine Learning
Jan 02, 2026Machine learning is central to empirical asset pricing, but portfolio construction still relies on point predictions and largely ignores asset-specific estimation uncertainty. We propose a simple change: sort assets using uncertainty-adjusted prediction bounds instead of point predictions alone. Across a broad set of ML models and a U.S. equity panel, this approach improves portfolio performance relative to point-prediction sorting. These gains persist even when bounds are built from partial or misspecified uncertainty information. They arise mainly from reduced volatility and are strongest for flexible machine learning models. Identification and robustness exercises show that these improvements are driven by asset-level rather than time or aggregate predictive uncertainty.
Compound and Parallel Modes of Tropical Convolutional Neural Networks
Apr 09, 2025Convolutional neural networks have become increasingly deep and complex, leading to higher computational costs. While tropical convolutional neural networks (TCNNs) reduce multiplications, they underperform compared to standard CNNs. To address this, we propose two new variants - compound TCNN (cTCNN) and parallel TCNN (pTCNN)-that use combinations of tropical min-plus and max-plus kernels to replace traditional convolution kernels. This reduces multiplications and balances efficiency with performance. Experiments on various datasets show that cTCNN and pTCNN match or exceed the performance of other CNN methods. Combining these with conventional CNNs in deeper architectures also improves performance. We are further exploring simplified TCNN architectures that reduce parameters and multiplications with minimal accuracy loss, aiming for efficient and effective models.
TrendSim: Simulating Trending Topics in Social Media Under Poisoning Attacks with LLM-based Multi-agent System
Dec 14, 2024



Trending topics have become a significant part of modern social media, attracting users to participate in discussions of breaking events. However, they also bring in a new channel for poisoning attacks, resulting in negative impacts on society. Therefore, it is urgent to study this critical problem and develop effective strategies for defense. In this paper, we propose TrendSim, an LLM-based multi-agent system to simulate trending topics in social media under poisoning attacks. Specifically, we create a simulation environment for trending topics that incorporates a time-aware interaction mechanism, centralized message dissemination, and an interactive system. Moreover, we develop LLM-based human-like agents to simulate users in social media, and propose prototype-based attackers to replicate poisoning attacks. Besides, we evaluate TrendSim from multiple aspects to validate its effectiveness. Based on TrendSim, we conduct simulation experiments to study four critical problems about poisoning attacks on trending topics for social benefit.
OpenAI-o1 AB Testing: Does the o1 model really do good reasoning in math problem solving?
Nov 09, 2024The Orion-1 model by OpenAI is claimed to have more robust logical reasoning capabilities than previous large language models. However, some suggest the excellence might be partially due to the model "memorizing" solutions, resulting in less satisfactory performance when prompted with problems not in the training data. We conduct a comparison experiment using two datasets: one consisting of International Mathematics Olympiad (IMO) problems, which is easily accessible; the other one consisting of Chinese National Team Training camp (CNT) problems, which have similar difficulty but not as publically accessible. We label the response for each problem and compare the performance between the two datasets. We conclude that there is no significant evidence to show that the model relies on memorizing problems and solutions. Also, we perform case studies to analyze some features of the model's response.
A Random-patch based Defense Strategy Against Physical Attacks for Face Recognition Systems
Apr 16, 2023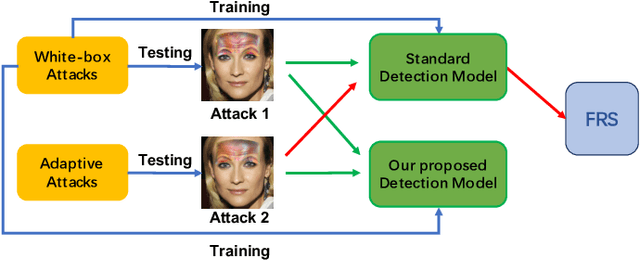
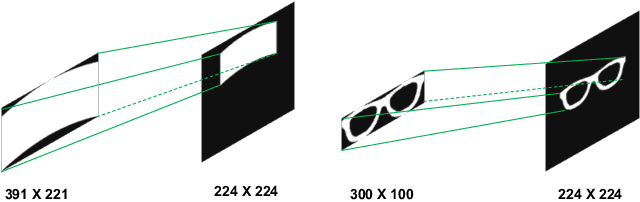
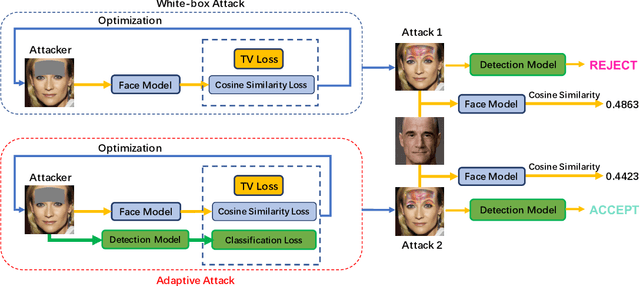
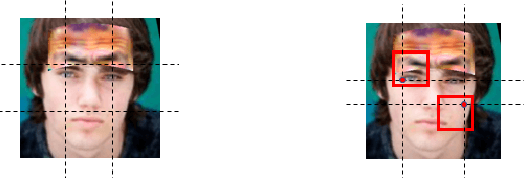
The physical attack has been regarded as a kind of threat against real-world computer vision systems. Still, many existing defense methods are only useful for small perturbations attacks and can't detect physical attacks effectively. In this paper, we propose a random-patch based defense strategy to robustly detect physical attacks for Face Recognition System (FRS). Different from mainstream defense methods which focus on building complex deep neural networks (DNN) to achieve high recognition rate on attacks, we introduce a patch based defense strategy to a standard DNN aiming to obtain robust detection models. Extensive experimental results on the employed datasets show the superiority of the proposed defense method on detecting white-box attacks and adaptive attacks which attack both FRS and the defense method. Additionally, due to the simpleness yet robustness of our method, it can be easily applied to the real world face recognition system and extended to other defense methods to boost the detection performance.
Allegro-Legato: Scalable, Fast, and Robust Neural-Network Quantum Molecular Dynamics via Sharpness-Aware Minimization
Mar 14, 2023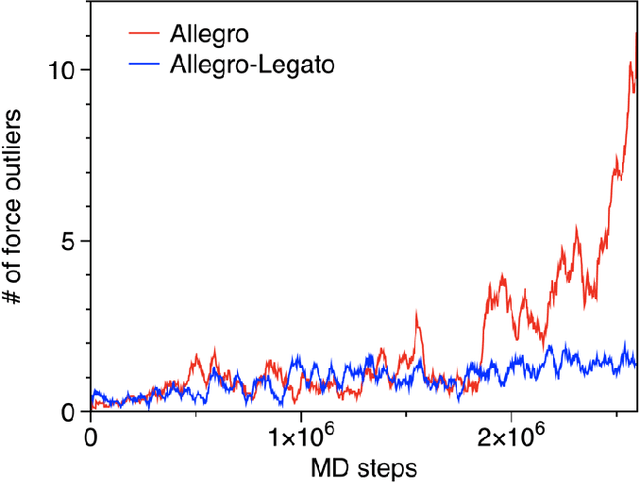

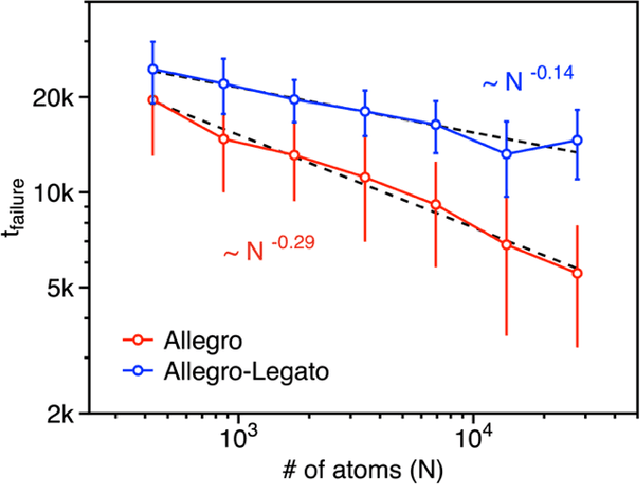

Neural-network quantum molecular dynamics (NNQMD) simulations based on machine learning are revolutionizing atomistic simulations of materials by providing quantum-mechanical accuracy but orders-of-magnitude faster, illustrated by ACM Gordon Bell prize (2020) and finalist (2021). State-of-the-art (SOTA) NNQMD model founded on group theory featuring rotational equivariance and local descriptors has provided much higher accuracy and speed than those models, thus named Allegro (meaning fast). On massively parallel supercomputers, however, it suffers a fidelity-scaling problem, where growing number of unphysical predictions of interatomic forces prohibits simulations involving larger numbers of atoms for longer times. Here, we solve this problem by combining the Allegro model with sharpness aware minimization (SAM) for enhancing the robustness of model through improved smoothness of the loss landscape. The resulting Allegro-Legato (meaning fast and "smooth") model was shown to elongate the time-to-failure $t_\textrm{failure}$, without sacrificing computational speed or accuracy. Specifically, Allegro-Legato exhibits much weaker dependence of timei-to-failure on the problem size, $t_{\textrm{failure}} \propto N^{-0.14}$ ($N$ is the number of atoms) compared to the SOTA Allegro model $\left(t_{\textrm{failure}} \propto N^{-0.29}\right)$, i.e., systematically delayed time-to-failure, thus allowing much larger and longer NNQMD simulations without failure. The model also exhibits excellent computational scalability and GPU acceleration on the Polaris supercomputer at Argonne Leadership Computing Facility. Such scalable, accurate, fast and robust NNQMD models will likely find broad applications in NNQMD simulations on emerging exaflop/s computers, with a specific example of accounting for nuclear quantum effects in the dynamics of ammonia.
Improving Long-tailed Object Detection with Image-Level Supervision by Multi-Task Collaborative Learning
Oct 11, 2022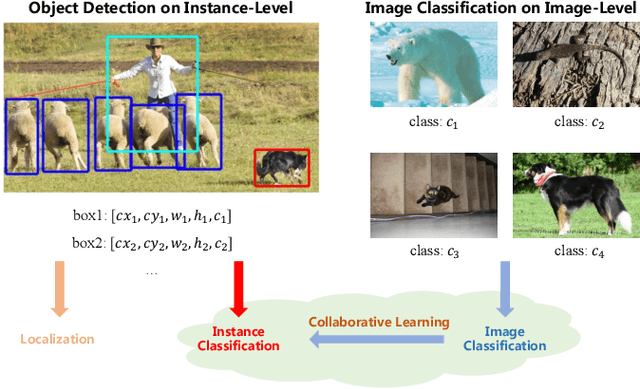
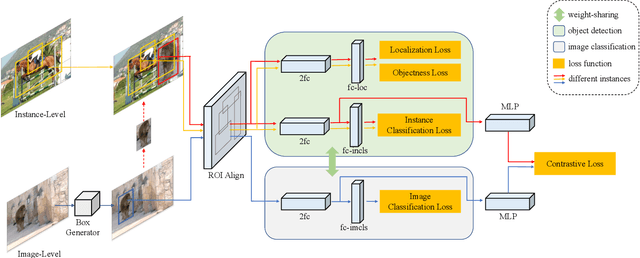
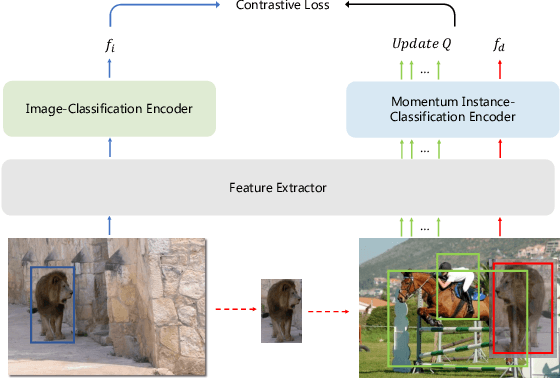

Data in real-world object detection often exhibits the long-tailed distribution. Existing solutions tackle this problem by mitigating the competition between the head and tail categories. However, due to the scarcity of training samples, tail categories are still unable to learn discriminative representations. Bringing more data into the training may alleviate the problem, but collecting instance-level annotations is an excruciating task. In contrast, image-level annotations are easily accessible but not fully exploited. In this paper, we propose a novel framework CLIS (multi-task Collaborative Learning with Image-level Supervision), which leverage image-level supervision to enhance the detection ability in a multi-task collaborative way. Specifically, there are an object detection task (consisting of an instance-classification task and a localization task) and an image-classification task in our framework, responsible for utilizing the two types of supervision. Different tasks are trained collaboratively by three key designs: (1) task-specialized sub-networks that learn specific representations of different tasks without feature entanglement. (2) a siamese sub-network for the image-classification task that shares its knowledge with the instance-classification task, resulting in feature enrichment of detectors. (3) a contrastive learning regularization that maintains representation consistency, bridging feature gaps of different supervision. Extensive experiments are conducted on the challenging LVIS dataset. Without sophisticated loss engineering, CLIS achieves an overall AP of 31.1 with 10.1 point improvement on tail categories, establishing a new state-of-the-art. Code will be at https://github.com/waveboo/CLIS.
Equalized Focal Loss for Dense Long-Tailed Object Detection
Jan 07, 2022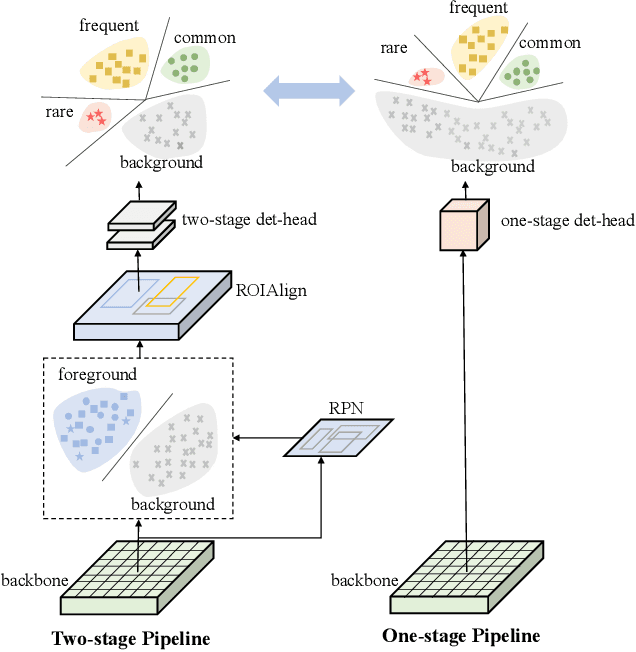
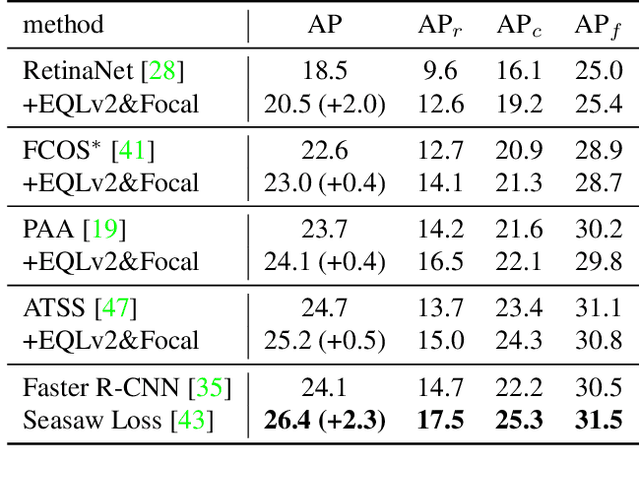
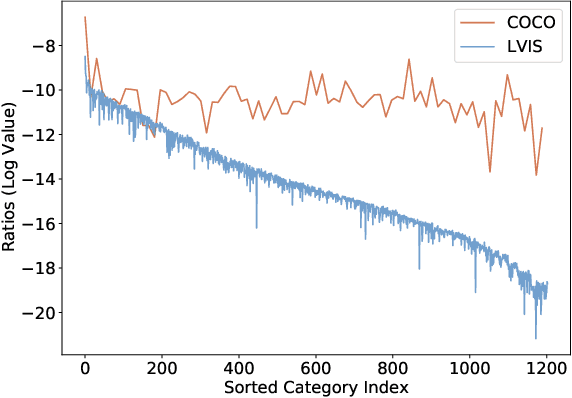
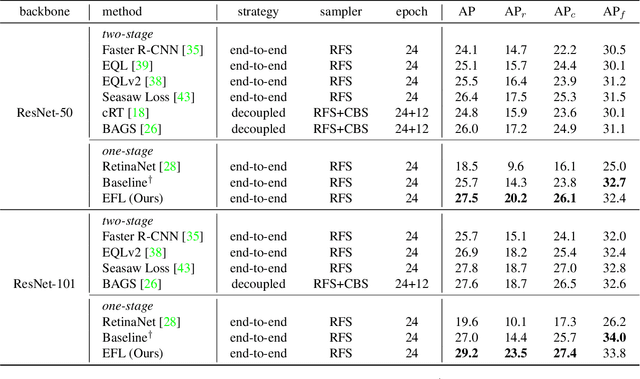
Despite the recent success of long-tailed object detection, almost all long-tailed object detectors are developed based on the two-stage paradigm. In practice, one-stage detectors are more prevalent in the industry because they have a simple and fast pipeline that is easy to deploy. However, in the long-tailed scenario, this line of work has not been explored so far. In this paper, we investigate whether one-stage detectors can perform well in this case. We discover the primary obstacle that prevents one-stage detectors from achieving excellent performance is: categories suffer from different degrees of positive-negative imbalance problems under the long-tailed data distribution. The conventional focal loss balances the training process with the same modulating factor for all categories, thus failing to handle the long-tailed problem. To address this issue, we propose the Equalized Focal Loss (EFL) that rebalances the loss contribution of positive and negative samples of different categories independently according to their imbalance degrees. Specifically, EFL adopts a category-relevant modulating factor which can be adjusted dynamically by the training status of different categories. Extensive experiments conducted on the challenging LVIS v1 benchmark demonstrate the effectiveness of our proposed method. With an end-to-end training pipeline, EFL achieves 29.2% in terms of overall AP and obtains significant performance improvements on rare categories, surpassing all existing state-of-the-art methods. The code is available at https://github.com/ModelTC/EOD.