 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Reinforcement Learning: An Instrumental Variable Approach
Paper and Code
Mar 06, 2021
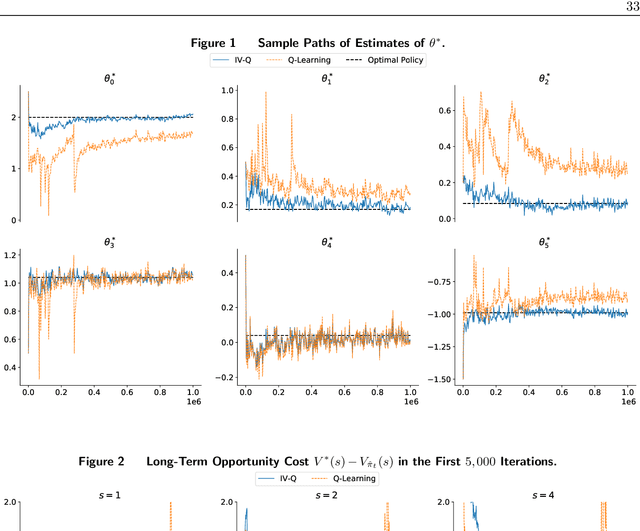

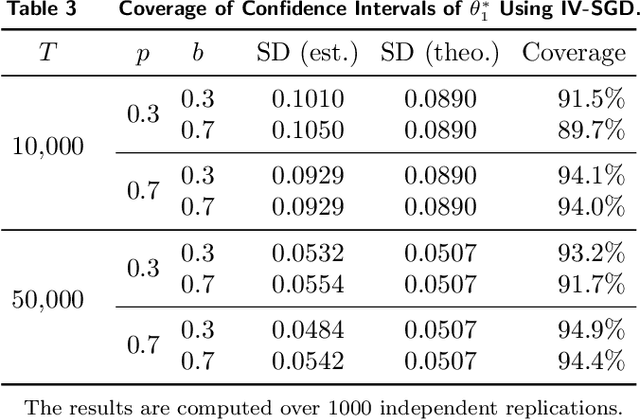
In the standard data analysis framework, data is first collected (once for all), and then data analysis is carried out. With the advancement of digital technology, decisionmakers constantly analyze past data and generate new data through the decisions they make. In this paper, we model this as a Markov decision process and show that the dynamic interaction between data generation and data analysis leads to a new type of bias -- reinforcement bias -- that exacerbates the endogeneity problem in standard data analysis. We propose a class of instrument variable (IV)-based reinforcement learning (RL) algorithms to correct for the bias and establish their asymptotic properties by incorporating them into a two-timescale stochastic approximation framework. A key contribution of the paper is the development of new techniques that allow for the analysis of the algorithms in general settings where noises feature time-dependency. We use the techniques to derive sharper results on finite-time trajectory stability bounds: with a polynomial rate, the entire future trajectory of the iterates from the algorithm fall within a ball that is centered at the true parameter and is shrinking at a (different) polynomial rate. We also use the technique to provide formulas for inferences that are rarely done for RL algorithms. These formulas highlight how the strength of the IV and the degree of the noise's time dependency affect the inference.