 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Plug-and-Play Watermark Framework for Stable Diffusion
Apr 08, 2024



Nowadays, the family of Stable Diffusion (SD) models has gained prominence for its high quality outputs and scalability. This has also raised security concerns on social media, as malicious users can create and disseminate harmful content. Existing approaches involve training components or entire SDs to embed a watermark in generated images for traceability and responsibility attribution. However, in the era of AI-generated content (AIGC), the rapid iteration of SDs renders retraining with watermark models costly. To address this, we propose a training-free plug-and-play watermark framework for SDs. Without modifying any components of SDs, we embed diverse watermarks in the latent space, adapting to the denoising process. Our experimental findings reveal that our method effectively harmonizes image quality and watermark invisibility. Furthermore, it performs robustly under various attacks. We also have validated that our method is generalized to multiple versions of SDs, even without retraining the watermark model.
T2IW: Joint Text to Image & Watermark Generation
Sep 07, 2023



Recent developments in text-conditioned image generative models have revolutionized the production of realistic results. Unfortunately, this has also led to an increase in privacy violations and the spread of false information, which requires the need for traceability, privacy protection, and other security measures. However, existing text-to-image paradigms lack the technical capabilities to link traceable messages with image generation. In this study, we introduce a novel task for the joint generation of text to image and watermark (T2IW). This T2IW scheme ensures minimal damage to image quality when generating a compound image by forcing the semantic feature and the watermark signal to be compatible in pixels. Additionally, by utilizing principles from Shannon information theory and non-cooperative game theory, we are able to separate the revealed image and the revealed watermark from the compound image. Furthermore, we strengthen the watermark robustness of our approach by subjecting the compound image to various post-processing attacks, with minimal pixel distortion observed in the revealed watermark. Extensive experiments have demonstrated remarkable achievements in image quality, watermark invisibility, and watermark robustness, supported by our proposed set of evaluation metrics.
PoissonSeg: Semi-Supervised Few-Shot Medical Image Segmentation via Poisson Learning
Aug 26, 2021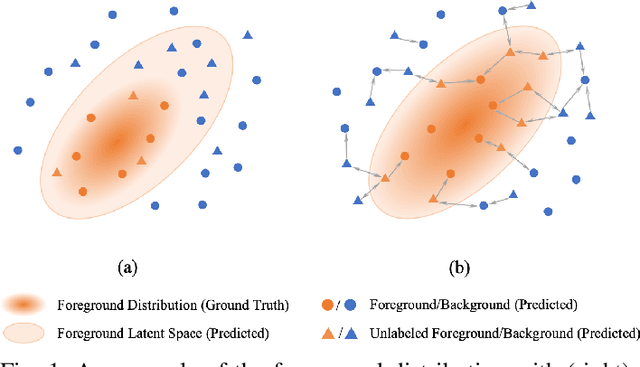
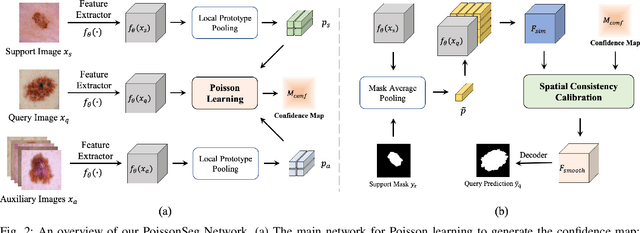
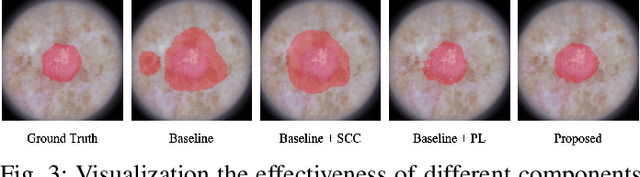
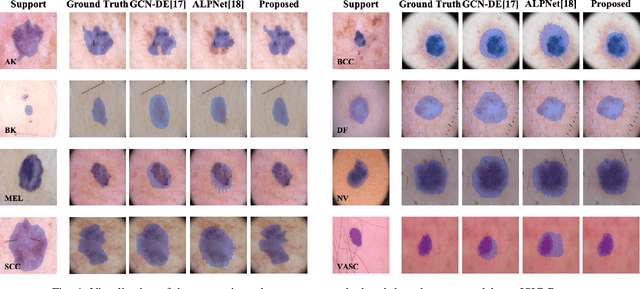
The application of deep learning to medical image segmentation has been hampered due to the lack of abundant pixel-level annotated data. Few-shot Semantic Segmentation (FSS) is a promising strategy for breaking the deadlock. However, a high-performing FSS model still requires sufficient pixel-level annotated classes for training to avoid overfitting, which leads to its performance bottleneck in medical image segmentation due to the unmet need for annotations. Thus, semi-supervised FSS for medical images is accordingly proposed to utilize unlabeled data for further performance improvement. Nevertheless, existing semi-supervised FSS methods has two obvious defects: (1) neglecting the relationship between the labeled and unlabeled data; (2) using unlabeled data directly for end-to-end training leads to degenerated representation learning. To address these problems, we propose a novel semi-supervised FSS framework for medical image segmentation. The proposed framework employs Poisson learning for modeling data relationship and propagating supervision signals, and Spatial Consistency Calibration for encouraging the model to learn more coherent representations. In this process, unlabeled samples do not involve in end-to-end training, but provide supervisory information for query image segmentation through graph-based learning. We conduct extensive experiments on three medical image segmentation datasets (i.e. ISIC skin lesion segmentation, abdominal organs segmentation for MRI and abdominal organs segmentation for CT) to demonstrate the state-of-the-art performance and broad applicability of the proposed framework.
Cross-Modal Self-Attention Distillation for Prostate Cancer Segmentation
Nov 08, 2020



Automatic segmentation of the prostate cancer from the multi-modal magnetic resonance images is of critical importance for the initial staging and prognosis of patients. However, how to use the multi-modal image features more efficiently is still a challenging problem in the field of medical image segmentation. In this paper, we develop a cross-modal self-attention distillation network by fully exploiting the encoded information of the intermediate layers from different modalities, and the extracted attention maps of different modalities enable the model to transfer the significant spatial information with more details. Moreover, a novel spatial correlated feature fusion module is further employed for learning more complementary correlation and non-linear information of different modality images. We evaluate our model in five-fold cross-validation on 358 MRI with biopsy confirmed. Extensive experiment results demonstrate that our proposed network achieves state-of-the-art performance.