 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCQA: A Strong Baseline for AIGC Quality Assessment Based on Prompt Condition
Apr 20, 2024



The development of Large Language Models (LLM) and Diffusion Models brings the boom of Artificial Intelligence Generated Content (AIGC). It is essential to build an effective quality assessment framework to provide a quantifiable evaluation of different images or videos based on the AIGC technologies. The content generated by AIGC methods is driven by the crafted prompts. Therefore, it is intuitive that the prompts can also serve as the foundation of the AIGC quality assessment. This study proposes an effective AIGC quality assessment (QA) framework. First, we propose a hybrid prompt encoding method based on a dual-source CLIP (Contrastive Language-Image Pre-Training) text encoder to understand and respond to the prompt conditions. Second, we propose an ensemble-based feature mixer module to effectively blend the adapted prompt and vision features. The empirical study practices in two datasets: AIGIQA-20K (AI-Generated Image Quality Assessment database) and T2VQA-DB (Text-to-Video Quality Assessment DataBase), which validates the effectiveness of our proposed method: Prompt Condition Quality Assessment (PCQA). Our proposed simple and feasible framework may promote research development in the multimodal generation field.
Geometric-Facilitated Denoising Diffusion Model for 3D Molecule Generation
Jan 05, 2024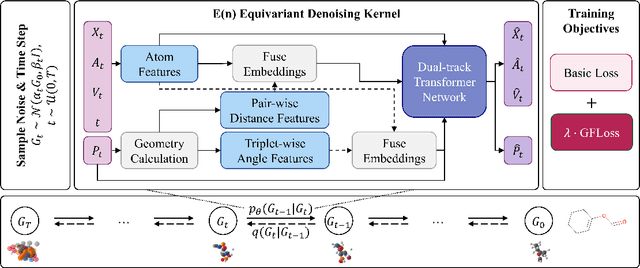
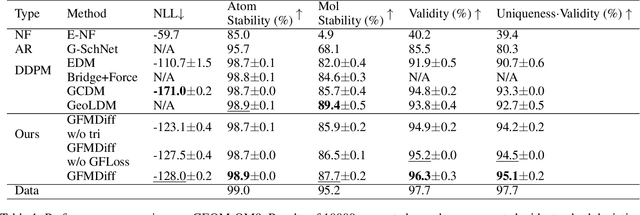
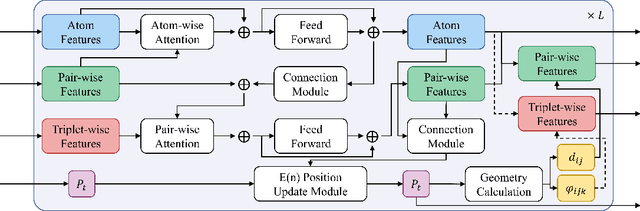
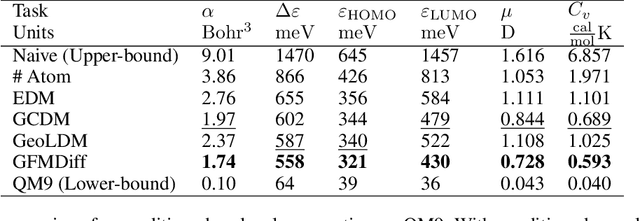
Denoising diffusion models have shown great potential in multiple research areas. Existing diffusion-based generative methods on de novo 3D molecule generation face two major challenges. Since majority heavy atoms in molecules allow connections to multiple atoms through single bonds, solely using pair-wise distance to model molecule geometries is insufficient. Therefore, the first one involves proposing an effective neural network as the denoising kernel that is capable to capture complex multi-body interatomic relationships and learn high-quality features. Due to the discrete nature of graphs, mainstream diffusion-based methods for molecules heavily rely on predefined rules and generate edges in an indirect manner. The second challenge involves accommodating molecule generation to diffusion and accurately predicting the existence of bonds. In our research, we view the iterative way of updating molecule conformations in diffusion process is consistent with molecular dynamics and introduce a novel molecule generation method named Geometric-Facilitated Molecular Diffusion (GFMDiff). For the first challenge, we introduce a Dual-Track Transformer Network (DTN) to fully excevate global spatial relationships and learn high quality representations which contribute to accurate predictions of features and geometries. As for the second challenge, we design Geometric-Facilitated Loss (GFLoss) which intervenes the formation of bonds during the training period, instead of directly embedding edges into the latent space. Comprehensive experiments on current benchmarks demonstrate the superiority of GFMDiff.
Experimental demonstration of magnetic tunnel junction-based computational random-access memory
Dec 21, 2023Conventional computing paradigm struggles to fulfill the rapidly growing demands from emerging applications, especially those for machine intelligence, because much of the power and energy is consumed by constant data transfers between logic and memory modules. A new paradigm, called "computational random-access memory (CRAM)" has emerged to address this fundamental limitation. CRAM performs logic operations directly using the memory cells themselves, without having the data ever leave the memory. The energy and performance benefits of CRAM for both conventional and emerging applications have been well established by prior numerical studies. However, there lacks an experimental demonstration and study of CRAM to evaluate its computation accuracy, which is a realistic and application-critical metrics for its technological feasibility and competitiveness. In this work, a CRAM array based on magnetic tunnel junctions (MTJs) is experimentally demonstrated. First, basic memory operations as well as 2-, 3-, and 5-input logic operations are studied. Then, a 1-bit full adder with two different designs is demonstrated. Based on the experimental results, a suite of modeling has been developed to characterize the accuracy of CRAM computation. Further analysis of scalar addition, multiplication, and matrix multiplication shows promising results. These results are then applied to a complete application: a neural network based handwritten digit classifier, as an example to show the connection between the application performance and further MTJ development. The classifier achieved almost-perfect classification accuracy, with reasonable projections of future MTJ development. With the confirmation of MTJ-based CRAM's accuracy, there is a strong case that this technology will have a significant impact on power- and energy-demanding applications of machine intelligence.
LFGCF: Light Folksonomy Graph Collaborative Filtering for Tag-Aware Recommendation
Aug 06, 2022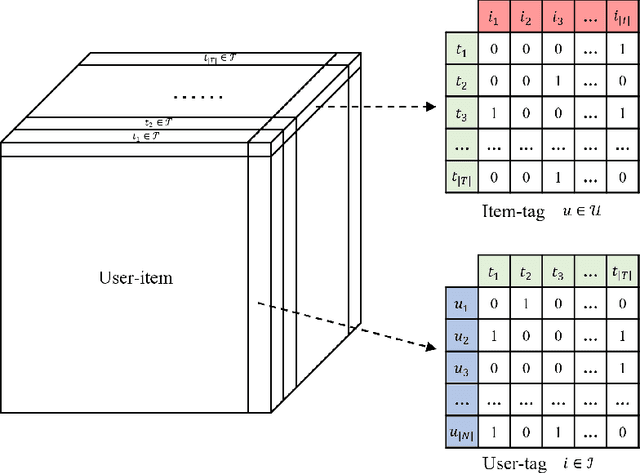
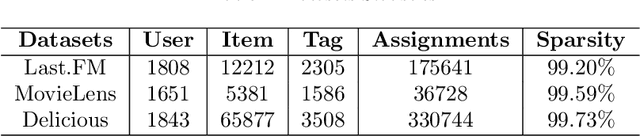
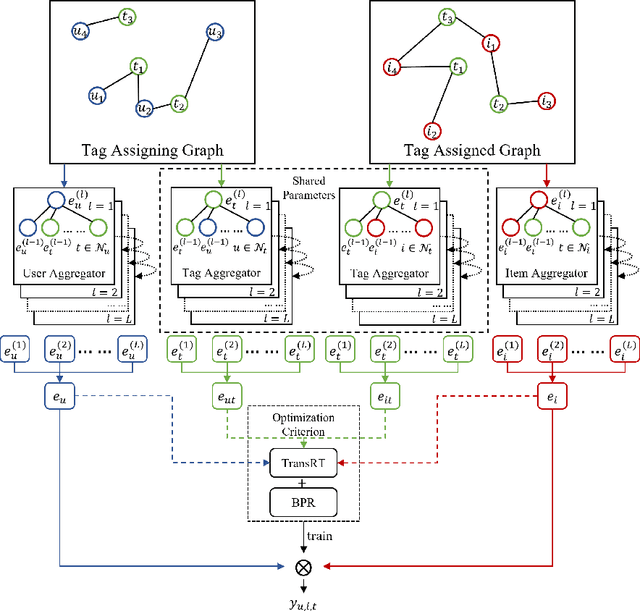
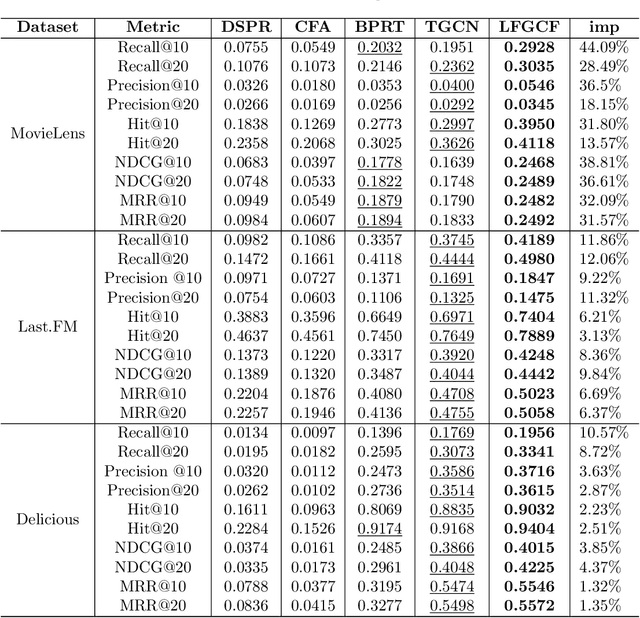
Tag-aware recommendation is a task of predicting a personalized list of items for a user by their tagging behaviors. It is crucial for many applications with tagging capabilities like last.fm or movielens. Recently, many efforts have been devoted to improving Tag-aware recommendation systems (TRS) with Graph Convolutional Networks (GCN), which has become new state-of-the-art for the general recommendation. However, some solutions are directly inherited from GCN without justifications, which is difficult to alleviate the sparsity, ambiguity, and redundancy issues introduced by tags, thus adding to difficulties of training and degrading recommendation performance. In this work, we aim to simplify the design of GCN to make it more concise for TRS. We propose a novel tag-aware recommendation model named Light Folksonomy Graph Collaborative Filtering (LFGCF), which only includes the essential GCN components. Specifically, LFGCF first constructs Folksonomy Graphs from the records of user assigning tags and item getting tagged. Then we leverage the simple design of aggregation to learn the high-order representations on Folksonomy Graphs and use the weighted sum of the embeddings learned at several layers for information updating. We share tags embeddings to bridge the information gap between users and items. Besides, a regularization function named TransRT is proposed to better depict user preferences and item features. Extensive hyperparameters experiments and ablation studies on three real-world datasets show that LFGCF uses fewer parameters and significantly outperforms most baselines for the tag-aware top-N recommendations.
Cross-Modal Self-Attention Distillation for Prostate Cancer Segmentation
Nov 08, 2020



Automatic segmentation of the prostate cancer from the multi-modal magnetic resonance images is of critical importance for the initial staging and prognosis of patients. However, how to use the multi-modal image features more efficiently is still a challenging problem in the field of medical image segmentation. In this paper, we develop a cross-modal self-attention distillation network by fully exploiting the encoded information of the intermediate layers from different modalities, and the extracted attention maps of different modalities enable the model to transfer the significant spatial information with more details. Moreover, a novel spatial correlated feature fusion module is further employed for learning more complementary correlation and non-linear information of different modality images. We evaluate our model in five-fold cross-validation on 358 MRI with biopsy confirmed. Extensive experiment results demonstrate that our proposed network achieves state-of-the-art performance.