 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Random-patch based Defense Strategy Against Physical Attacks for Face Recognition Systems
Apr 16, 2023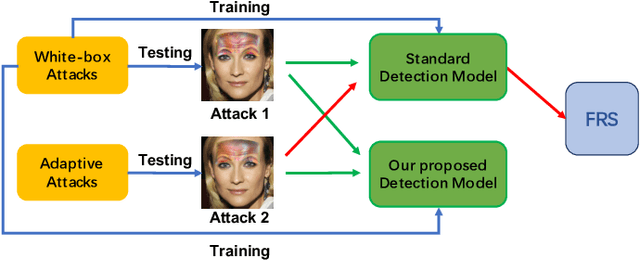
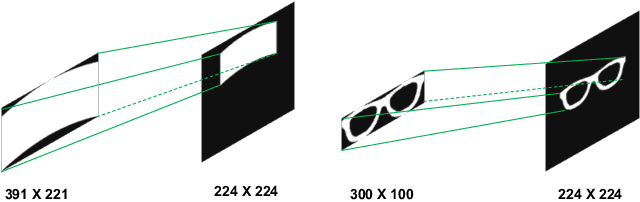
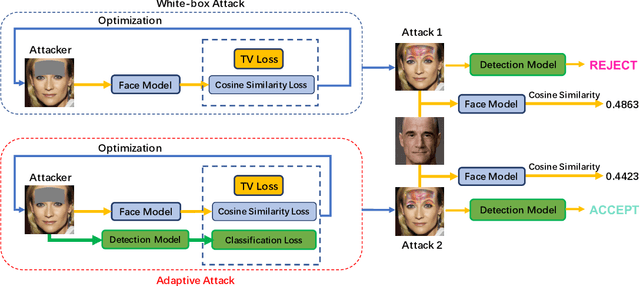
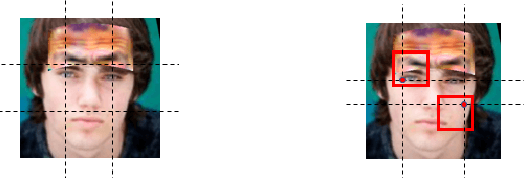
The physical attack has been regarded as a kind of threat against real-world computer vision systems. Still, many existing defense methods are only useful for small perturbations attacks and can't detect physical attacks effectively. In this paper, we propose a random-patch based defense strategy to robustly detect physical attacks for Face Recognition System (FRS). Different from mainstream defense methods which focus on building complex deep neural networks (DNN) to achieve high recognition rate on attacks, we introduce a patch based defense strategy to a standard DNN aiming to obtain robust detection models. Extensive experimental results on the employed datasets show the superiority of the proposed defense method on detecting white-box attacks and adaptive attacks which attack both FRS and the defense method. Additionally, due to the simpleness yet robustness of our method, it can be easily applied to the real world face recognition system and extended to other defense methods to boost the detection performance.
Improving Long-tailed Object Detection with Image-Level Supervision by Multi-Task Collaborative Learning
Oct 11, 2022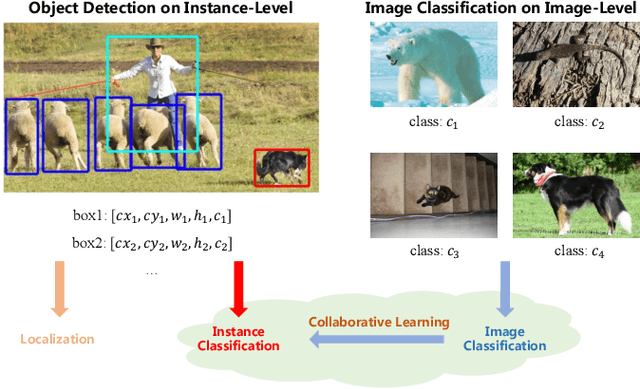
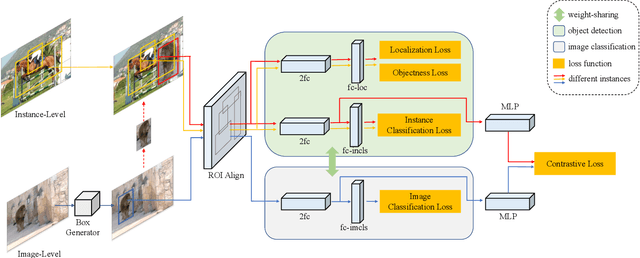
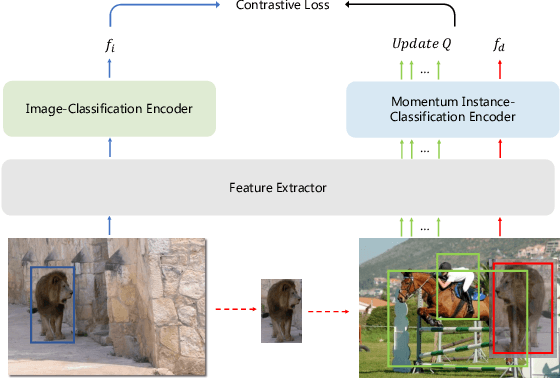

Data in real-world object detection often exhibits the long-tailed distribution. Existing solutions tackle this problem by mitigating the competition between the head and tail categories. However, due to the scarcity of training samples, tail categories are still unable to learn discriminative representations. Bringing more data into the training may alleviate the problem, but collecting instance-level annotations is an excruciating task. In contrast, image-level annotations are easily accessible but not fully exploited. In this paper, we propose a novel framework CLIS (multi-task Collaborative Learning with Image-level Supervision), which leverage image-level supervision to enhance the detection ability in a multi-task collaborative way. Specifically, there are an object detection task (consisting of an instance-classification task and a localization task) and an image-classification task in our framework, responsible for utilizing the two types of supervision. Different tasks are trained collaboratively by three key designs: (1) task-specialized sub-networks that learn specific representations of different tasks without feature entanglement. (2) a siamese sub-network for the image-classification task that shares its knowledge with the instance-classification task, resulting in feature enrichment of detectors. (3) a contrastive learning regularization that maintains representation consistency, bridging feature gaps of different supervision. Extensive experiments are conducted on the challenging LVIS dataset. Without sophisticated loss engineering, CLIS achieves an overall AP of 31.1 with 10.1 point improvement on tail categories, establishing a new state-of-the-art. Code will be at https://github.com/waveboo/CLIS.
Equalized Focal Loss for Dense Long-Tailed Object Detection
Jan 07, 2022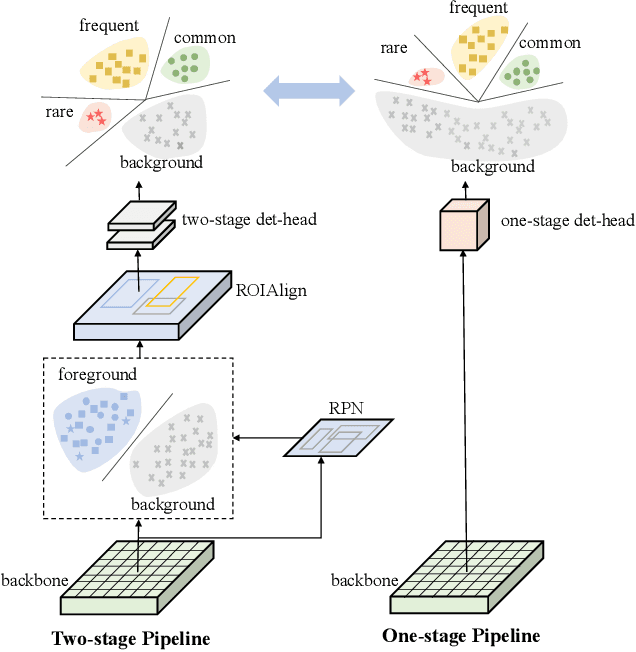
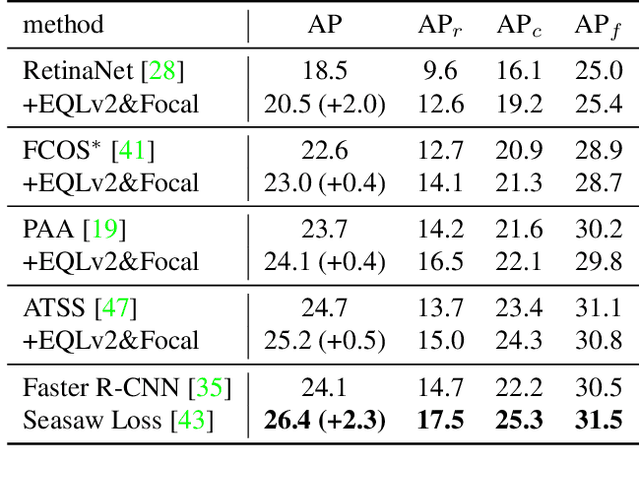
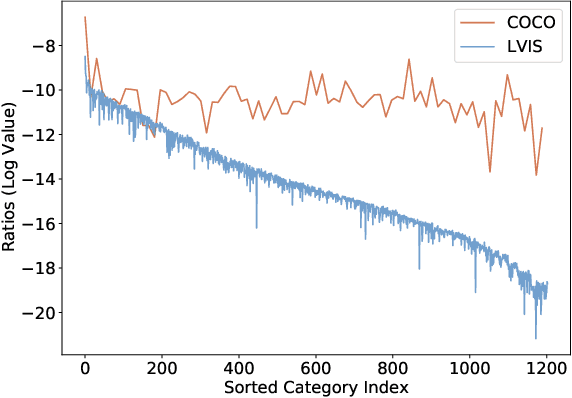
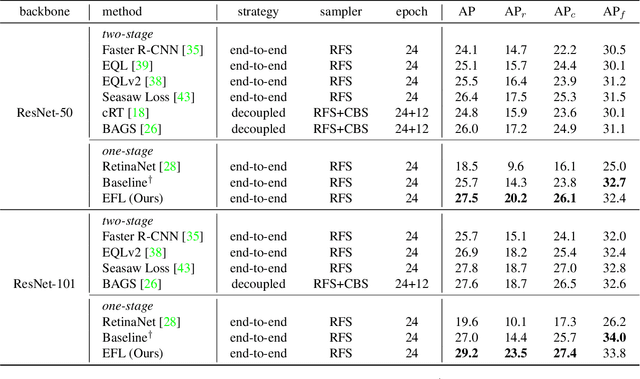
Despite the recent success of long-tailed object detection, almost all long-tailed object detectors are developed based on the two-stage paradigm. In practice, one-stage detectors are more prevalent in the industry because they have a simple and fast pipeline that is easy to deploy. However, in the long-tailed scenario, this line of work has not been explored so far. In this paper, we investigate whether one-stage detectors can perform well in this case. We discover the primary obstacle that prevents one-stage detectors from achieving excellent performance is: categories suffer from different degrees of positive-negative imbalance problems under the long-tailed data distribution. The conventional focal loss balances the training process with the same modulating factor for all categories, thus failing to handle the long-tailed problem. To address this issue, we propose the Equalized Focal Loss (EFL) that rebalances the loss contribution of positive and negative samples of different categories independently according to their imbalance degrees. Specifically, EFL adopts a category-relevant modulating factor which can be adjusted dynamically by the training status of different categories. Extensive experiments conducted on the challenging LVIS v1 benchmark demonstrate the effectiveness of our proposed method. With an end-to-end training pipeline, EFL achieves 29.2% in terms of overall AP and obtains significant performance improvements on rare categories, surpassing all existing state-of-the-art methods. The code is available at https://github.com/ModelTC/EOD.
PoissonSeg: Semi-Supervised Few-Shot Medical Image Segmentation via Poisson Learning
Aug 26, 2021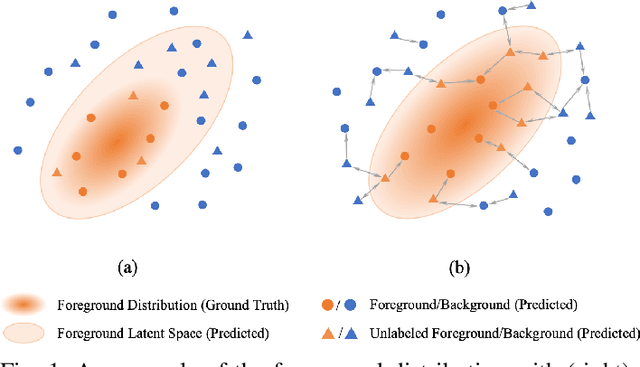
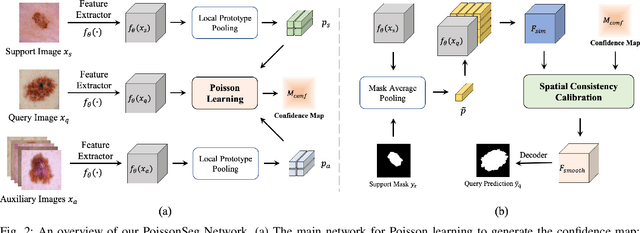
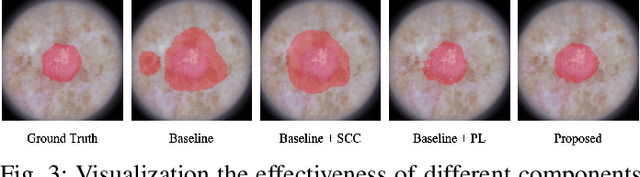
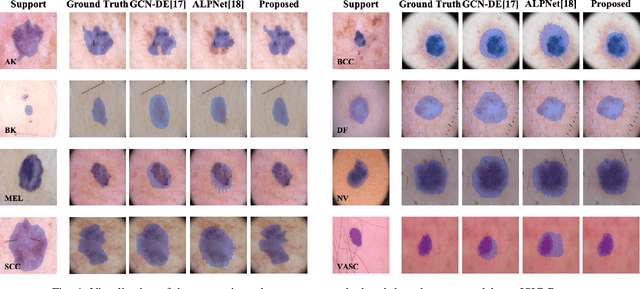
The application of deep learning to medical image segmentation has been hampered due to the lack of abundant pixel-level annotated data. Few-shot Semantic Segmentation (FSS) is a promising strategy for breaking the deadlock. However, a high-performing FSS model still requires sufficient pixel-level annotated classes for training to avoid overfitting, which leads to its performance bottleneck in medical image segmentation due to the unmet need for annotations. Thus, semi-supervised FSS for medical images is accordingly proposed to utilize unlabeled data for further performance improvement. Nevertheless, existing semi-supervised FSS methods has two obvious defects: (1) neglecting the relationship between the labeled and unlabeled data; (2) using unlabeled data directly for end-to-end training leads to degenerated representation learning. To address these problems, we propose a novel semi-supervised FSS framework for medical image segmentation. The proposed framework employs Poisson learning for modeling data relationship and propagating supervision signals, and Spatial Consistency Calibration for encouraging the model to learn more coherent representations. In this process, unlabeled samples do not involve in end-to-end training, but provide supervisory information for query image segmentation through graph-based learning. We conduct extensive experiments on three medical image segmentation datasets (i.e. ISIC skin lesion segmentation, abdominal organs segmentation for MRI and abdominal organs segmentation for CT) to demonstrate the state-of-the-art performance and broad applicability of the proposed framework.
L-SNet: from Region Localization to Scale Invariant Medical Image Segmentation
Feb 11, 2021
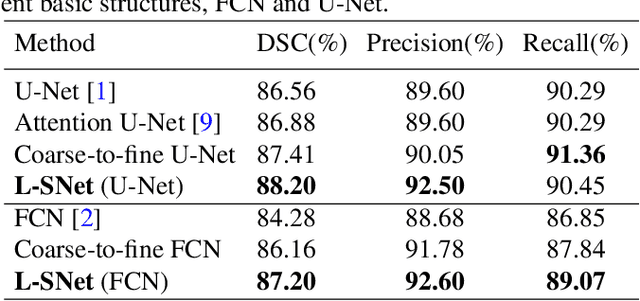
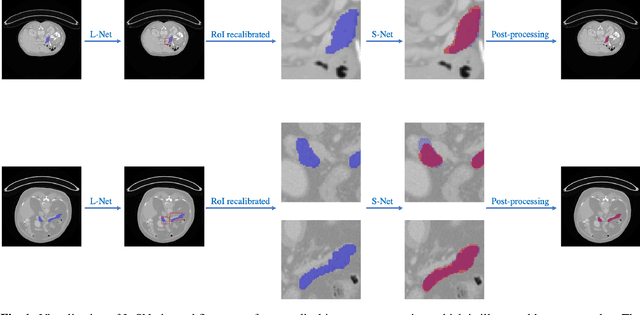

Coarse-to-fine models and cascade segmentation architectures are widely adopted to solve the problem of large scale variations in medical image segmentation. However, those methods have two primary limitations: the first-stage segmentation becomes a performance bottleneck; the lack of overall differentiability makes the training process of two stages asynchronous and inconsistent. In this paper, we propose a differentiable two-stage network architecture to tackle these problems. In the first stage, a localization network (L-Net) locates Regions of Interest (RoIs) in a detection fashion; in the second stage, a segmentation network (S-Net) performs fine segmentation on the recalibrated RoIs; a RoI recalibration module between L-Net and S-Net eliminating the inconsistencies. Experimental results on the public dataset show that our method outperforms state-of-the-art coarse-to-fine models with negligible computation overheads.
Cross-Modal Self-Attention Distillation for Prostate Cancer Segmentation
Nov 08, 2020



Automatic segmentation of the prostate cancer from the multi-modal magnetic resonance images is of critical importance for the initial staging and prognosis of patients. However, how to use the multi-modal image features more efficiently is still a challenging problem in the field of medical image segmentation. In this paper, we develop a cross-modal self-attention distillation network by fully exploiting the encoded information of the intermediate layers from different modalities, and the extracted attention maps of different modalities enable the model to transfer the significant spatial information with more details. Moreover, a novel spatial correlated feature fusion module is further employed for learning more complementary correlation and non-linear information of different modality images. We evaluate our model in five-fold cross-validation on 358 MRI with biopsy confirmed. Extensive experiment results demonstrate that our proposed network achieves state-of-the-art performance.
Detecting "Smart" Spammers On Social Network: A Topic Model Approach
Jun 09, 2016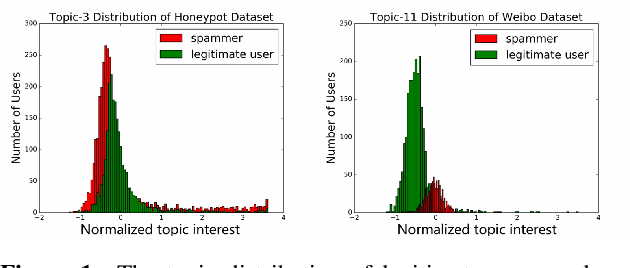
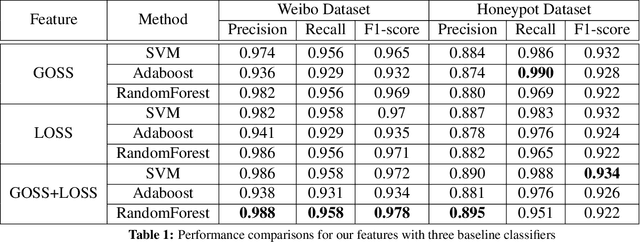
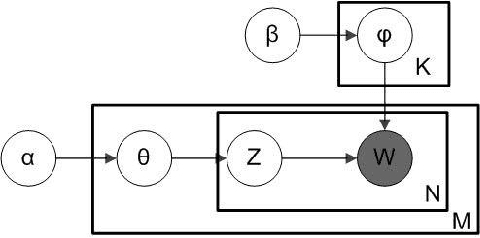
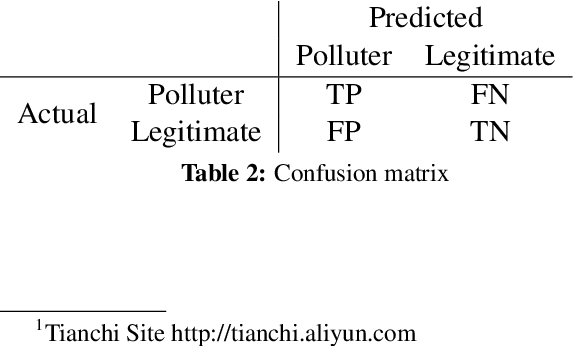
Spammer detection on social network is a challenging problem. The rigid anti-spam rules have resulted in emergence of "smart" spammers. They resemble legitimate users who are difficult to identify. In this paper, we present a novel spammer classification approach based on Latent Dirichlet Allocation(LDA), a topic model. Our approach extracts both the local and the global information of topic distribution patterns, which capture the essence of spamming. Tested on one benchmark dataset and one self-collected dataset, our proposed method outperforms other state-of-the-art methods in terms of averaged F1-score.