 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Expansion Using Contextual Clue Sampling with Language Models
Oct 13, 2022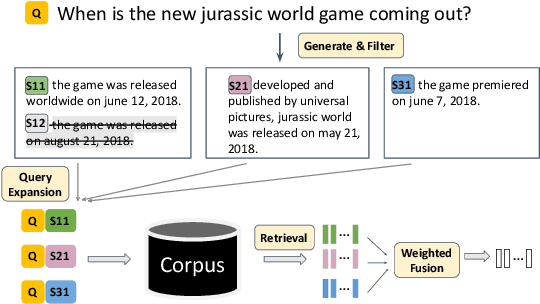
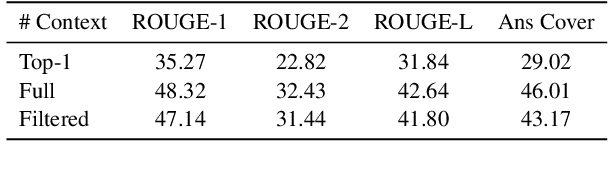
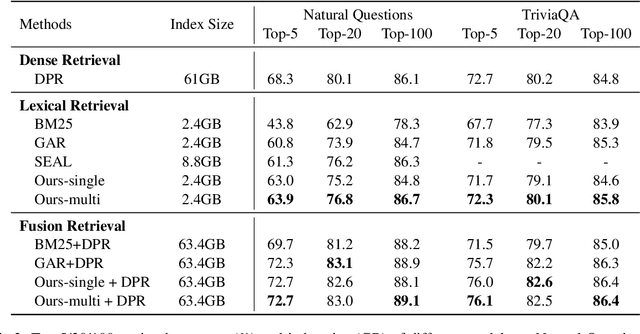
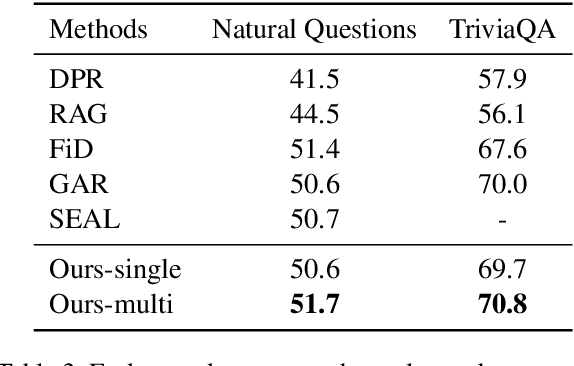
Query expansion is an effective approach for mitigating vocabulary mismatch between queries and documents in information retrieval. One recent line of research uses language models to generate query-related contexts for expansion. Along this line, we argue that expansion terms from these contexts should balance two key aspects: diversity and relevance. The obvious way to increase diversity is to sample multiple contexts from the language model. However, this comes at the cost of relevance, because there is a well-known tendency of models to hallucinate incorrect or irrelevant contexts. To balance these two considerations, we propose a combination of an effective filtering strategy and fusion of the retrieved documents based on the generation probability of each context. Our lexical matching based approach achieves a similar top-5/top-20 retrieval accuracy and higher top-100 accuracy compared with the well-established dense retrieval model DPR, while reducing the index size by more than 96%. For end-to-end QA, the reader model also benefits from our method and achieves the highest Exact-Match score against several competitive baselines.
Questions for Flat-Minima Optimization of Modern Neural Networks
Feb 02, 2022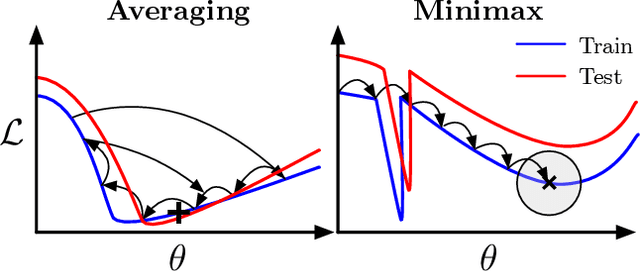
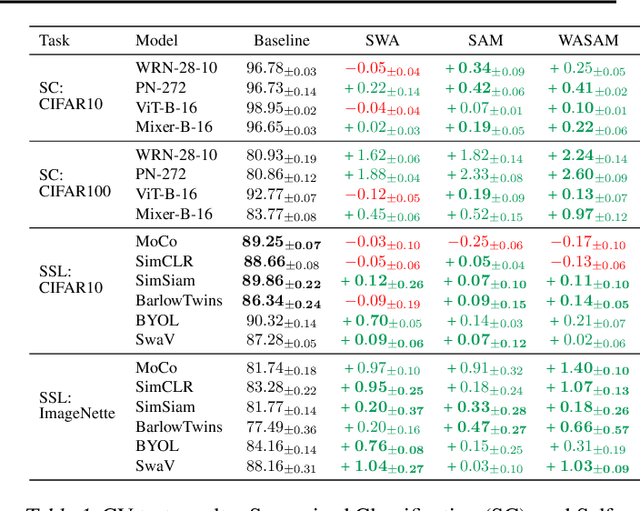
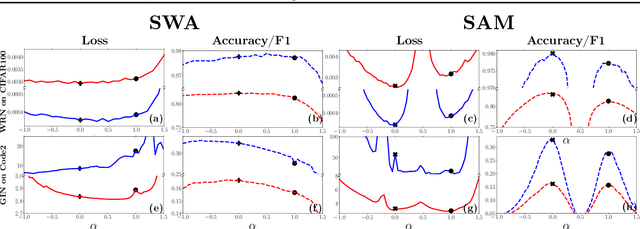
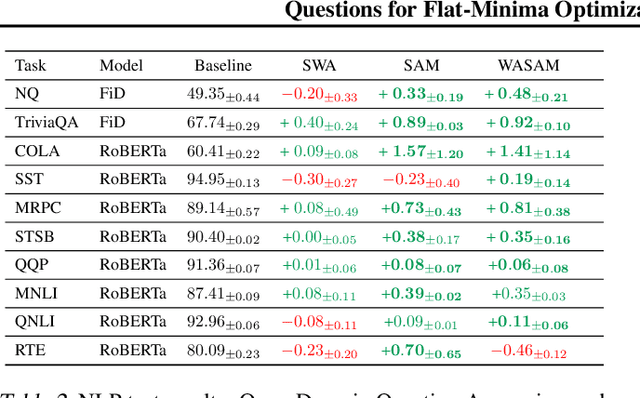
For training neural networks, flat-minima optimizers that seek to find parameters in neighborhoods having uniformly low loss (flat minima) have been shown to improve upon stochastic and adaptive gradient-based methods. Two methods for finding flat minima stand out: 1. Averaging methods (i.e., Stochastic Weight Averaging, SWA), and 2. Minimax methods (i.e., Sharpness Aware Minimization, SAM). However, despite similar motivations, there has been limited investigation into their properties and no comprehensive comparison between them. In this work, we investigate the loss surfaces from a systematic benchmarking of these approaches across computer vision, natural language processing, and graph learning tasks. The results lead to a simple hypothesis: since both approaches find different flat solutions, combining them should improve generalization even further. We verify this improves over either flat-minima approach in 39 out of 42 cases. When it does not, we investigate potential reasons. We hope our results across image, graph, and text data will help researchers to improve deep learning optimizers, and practitioners to pinpoint the optimizer for the problem at hand.
Challenges in Generalization in Open Domain Question Answering
Sep 02, 2021


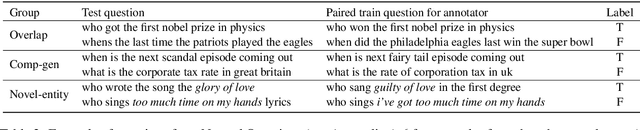
Recent work on Open Domain Question Answering has shown that there is a large discrepancy in model performance between novel test questions and those that largely overlap with training questions. However, it is as of yet unclear which aspects of novel questions that make them challenging. Drawing upon studies on systematic generalization, we introduce and annotate questions according to three categories that measure different levels and kinds of generalization: training set overlap, compositional generalization (comp-gen), and novel entity generalization (novel-entity). When evaluating six popular parametric and non-parametric models, we find that for the established Natural Questions and TriviaQA datasets, even the strongest model performance for comp-gen/novel-entity is 13.1/5.4% and 9.6/1.5% lower compared to that for the full test set -- indicating the challenge posed by these types of questions. Furthermore, we show that whilst non-parametric models can handle questions containing novel entities, they struggle with those requiring compositional generalization. Through thorough analysis we find that key question difficulty factors are: cascading errors from the retrieval component, frequency of question pattern, and frequency of the entity.
Controllable Abstractive Dialogue Summarization with Sketch Supervision
Jun 03, 2021
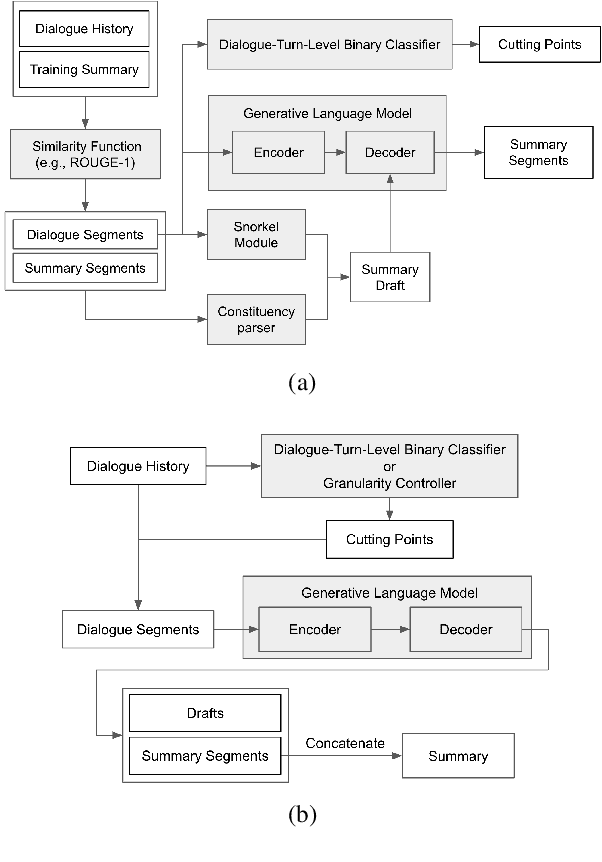

In this paper, we aim to improve abstractive dialogue summarization quality and, at the same time, enable granularity control. Our model has two primary components and stages: 1) a two-stage generation strategy that generates a preliminary summary sketch serving as the basis for the final summary. This summary sketch provides a weakly supervised signal in the form of pseudo-labeled interrogative pronoun categories and key phrases extracted using a constituency parser. 2) A simple strategy to control the granularity of the final summary, in that our model can automatically determine or control the number of generated summary sentences for a given dialogue by predicting and highlighting different text spans from the source text. Our model achieves state-of-the-art performance on the largest dialogue summarization corpus SAMSum, with as high as 50.79 in ROUGE-L score. In addition, we conduct a case study and show competitive human evaluation results and controllability to human-annotated summaries.
PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them
Feb 13, 2021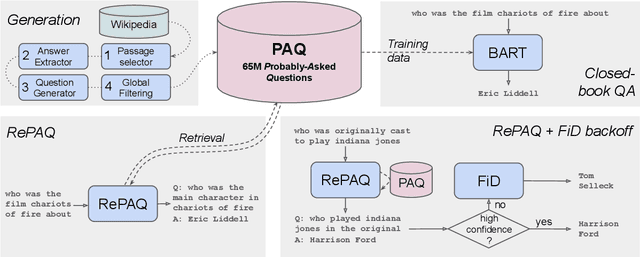
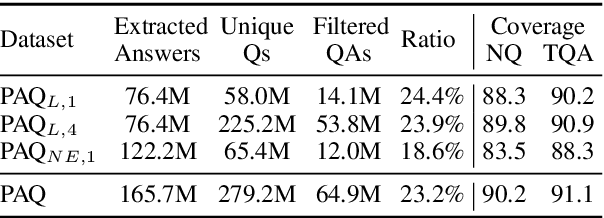

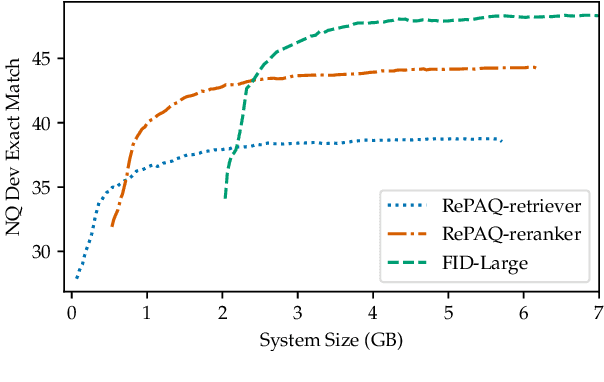
Open-domain Question Answering models which directly leverage question-answer (QA) pairs, such as closed-book QA (CBQA) models and QA-pair retrievers, show promise in terms of speed and memory compared to conventional models which retrieve and read from text corpora. QA-pair retrievers also offer interpretable answers, a high degree of control, and are trivial to update at test time with new knowledge. However, these models lack the accuracy of retrieve-and-read systems, as substantially less knowledge is covered by the available QA-pairs relative to text corpora like Wikipedia. To facilitate improved QA-pair models, we introduce Probably Asked Questions (PAQ), a very large resource of 65M automatically-generated QA-pairs. We introduce a new QA-pair retriever, RePAQ, to complement PAQ. We find that PAQ preempts and caches test questions, enabling RePAQ to match the accuracy of recent retrieve-and-read models, whilst being significantly faster. Using PAQ, we train CBQA models which outperform comparable baselines by 5%, but trail RePAQ by over 15%, indicating the effectiveness of explicit retrieval. RePAQ can be configured for size (under 500MB) or speed (over 1K questions per second) whilst retaining high accuracy. Lastly, we demonstrate RePAQ's strength at selective QA, abstaining from answering when it is likely to be incorrect. This enables RePAQ to ``back-off" to a more expensive state-of-the-art model, leading to a combined system which is both more accurate and 2x faster than the state-of-the-art model alone.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021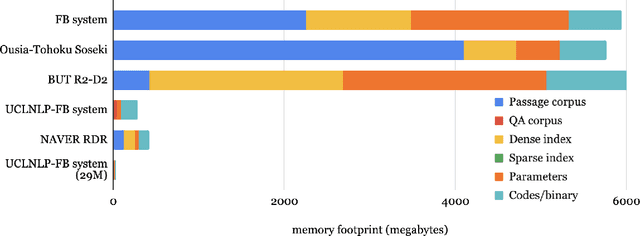
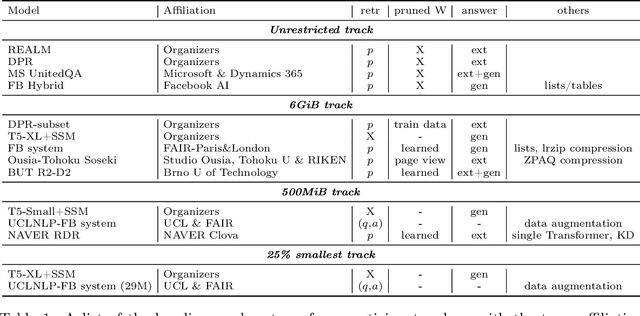
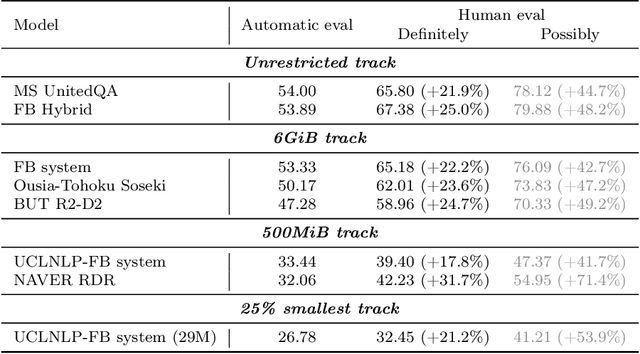
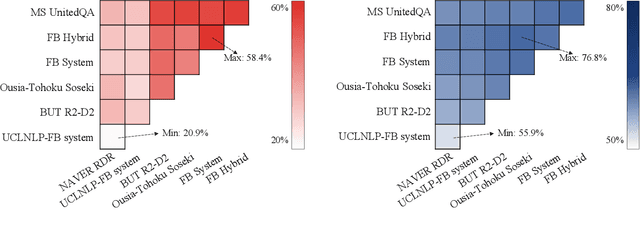
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Attentive Student Meets Multi-Task Teacher: Improved Knowledge Distillation for Pretrained Models
Nov 09, 2019
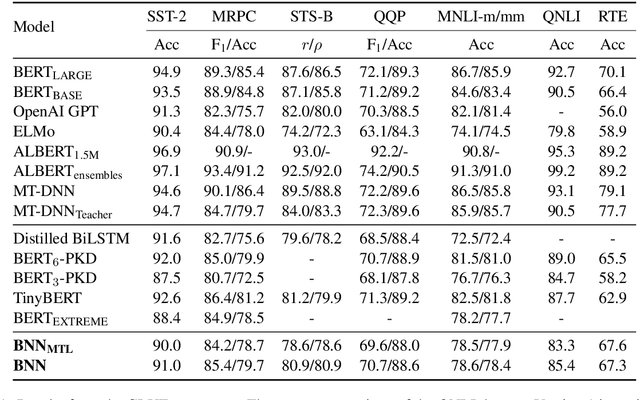
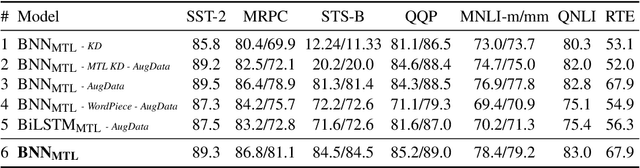
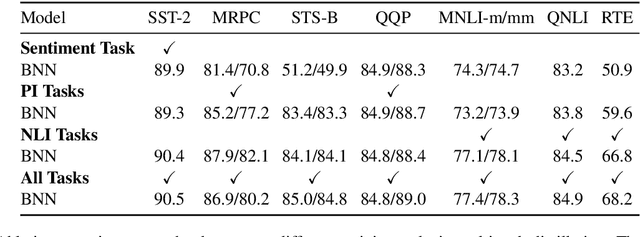
In this paper, we explore the knowledge distillation approach under the multi-task learning setting. We distill the BERT model refined by multi-task learning on seven datasets of the GLUE benchmark into a bidirectional LSTM with attention mechanism. Unlike other BERT distillation methods which specifically designed for Transformer-based architectures, we provide a general learning framework. Our approach is model agnostic and can be easily applied on different future teacher models. Compared to a strong, similarly BiLSTM-based approach, we achieve better quality under the same computational constraints. Compared to the present state of the art, we reach comparable results with much faster inference speed.
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
Mar 28, 2019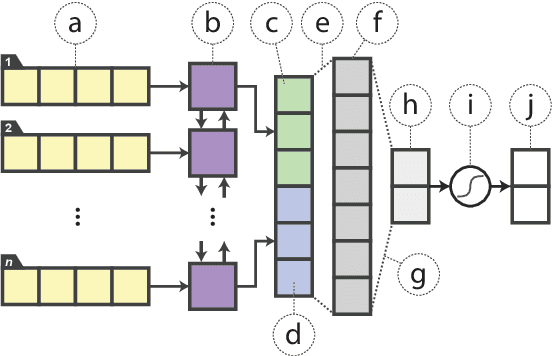

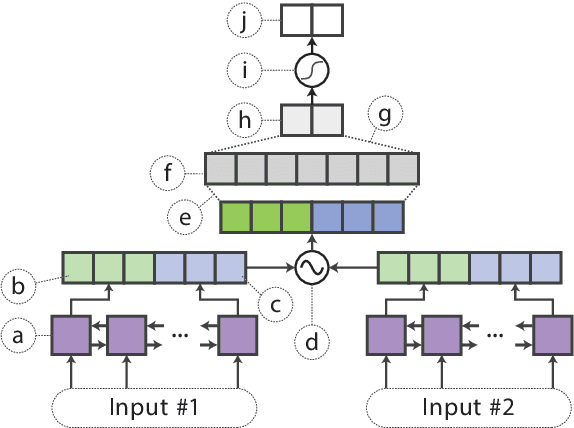
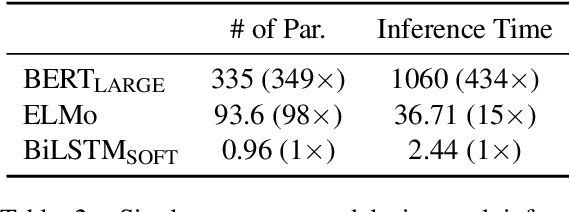
In the natural language processing literature, neural networks are becoming increasingly deeper and complex. The recent poster child of this trend is the deep language representation model, which includes BERT, ELMo, and GPT. These developments have led to the conviction that previous-generation, shallower neural networks for language understanding are obsolete. In this paper, however, we demonstrate that rudimentary, lightweight neural networks can still be made competitive without architecture changes, external training data, or additional input features. We propose to distill knowledge from BERT, a state-of-the-art language representation model, into a single-layer BiLSTM, as well as its siamese counterpart for sentence-pair tasks. Across multiple datasets in paraphrasing, natural language inference, and sentiment classification, we achieve comparable results with ELMo, while using roughly 100 times fewer parameters and 15 times less inference time.
Generative Adversarial Network for Abstractive Text Summarization
Nov 26, 2017
In this paper, we propose an adversarial process for abstractive text summarization, in which we simultaneously train a generative model G and a discriminative model D. In particular, we build the generator G as an agent of reinforcement learning, which takes the raw text as input and predicts the abstractive summarization. We also build a discriminator which attempts to distinguish the generated summary from the ground truth summary. Extensive experiments demonstrate that our model achieves competitive ROUGE scores with the state-of-the-art methods on CNN/Daily Mail dataset. Qualitatively, we show that our model is able to generate more abstractive, readable and diverse summaries.
Detecting "Smart" Spammers On Social Network: A Topic Model Approach
Jun 09, 2016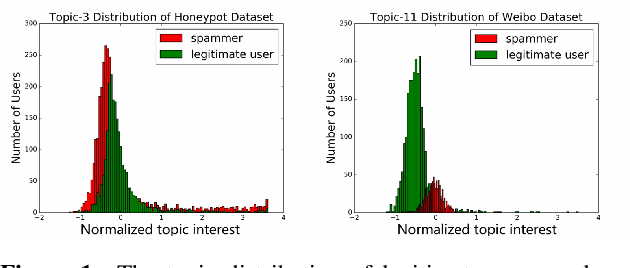
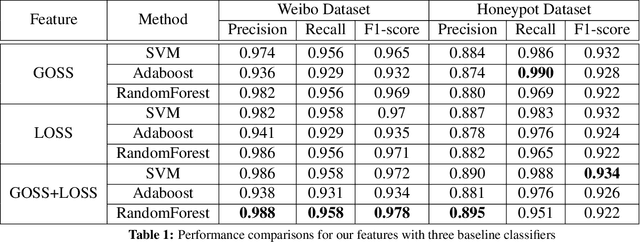
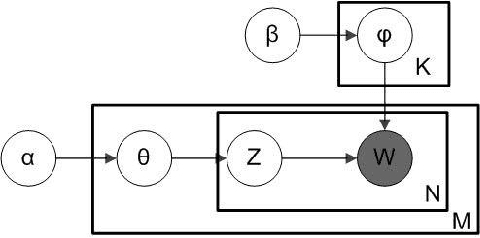
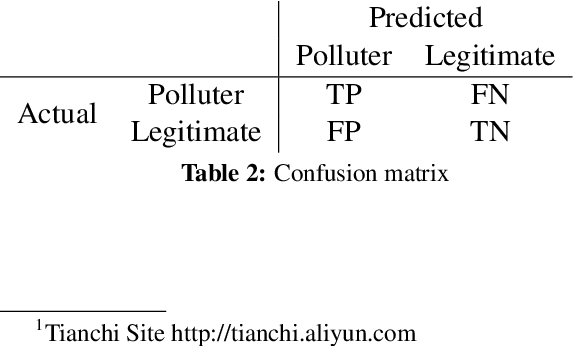
Spammer detection on social network is a challenging problem. The rigid anti-spam rules have resulted in emergence of "smart" spammers. They resemble legitimate users who are difficult to identify. In this paper, we present a novel spammer classification approach based on Latent Dirichlet Allocation(LDA), a topic model. Our approach extracts both the local and the global information of topic distribution patterns, which capture the essence of spamming. Tested on one benchmark dataset and one self-collected dataset, our proposed method outperforms other state-of-the-art methods in terms of averaged F1-score.