 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Generalization in Open Domain Question Answering
Paper and Code



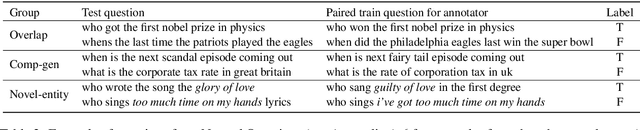
Recent work on Open Domain Question Answering has shown that there is a large discrepancy in model performance between novel test questions and those that largely overlap with training questions. However, it is as of yet unclear which aspects of novel questions that make them challenging. Drawing upon studies on systematic generalization, we introduce and annotate questions according to three categories that measure different levels and kinds of generalization: training set overlap, compositional generalization (comp-gen), and novel entity generalization (novel-entity). When evaluating six popular parametric and non-parametric models, we find that for the established Natural Questions and TriviaQA datasets, even the strongest model performance for comp-gen/novel-entity is 13.1/5.4% and 9.6/1.5% lower compared to that for the full test set -- indicating the challenge posed by these types of questions. Furthermore, we show that whilst non-parametric models can handle questions containing novel entities, they struggle with those requiring compositional generalization. Through thorough analysis we find that key question difficulty factors are: cascading errors from the retrieval component, frequency of question pattern, and frequency of the entity.