 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining
Jan 01, 2026Multilingual large language models achieve impressive cross-lingual performance despite largely monolingual pretraining. While bilingual data in pretraining corpora is widely believed to enable these abilities, details of its contributions remain unclear. We investigate this question by pretraining models from scratch under controlled conditions, comparing the standard web corpus with a monolingual-only version that removes all multilingual documents. Despite constituting only 2% of the corpus, removing bilingual data causes translation performance to drop 56% in BLEU, while behaviour on cross-lingual QA and general reasoning tasks remains stable, with training curves largely overlapping the baseline. To understand this asymmetry, we categorize bilingual data into parallel (14%), code-switching (72%), and miscellaneous documents (14%) based on the semantic relevance of content in different languages. We then conduct granular ablations by reintroducing parallel or code-switching data into the monolingual-only corpus. Our experiments reveal that parallel data almost fully restores translation performance (91% of the unfiltered baseline), whereas code-switching contributes minimally. Other cross-lingual tasks remain largely unaffected by either type. These findings reveal that translation critically depends on systematic token-level alignments from parallel data, whereas cross-lingual understanding and reasoning appear to be achievable even without bilingual data.
Drawing Conclusions from Draws: Rethinking Preference Semantics in Arena-Style LLM Evaluation
Oct 02, 2025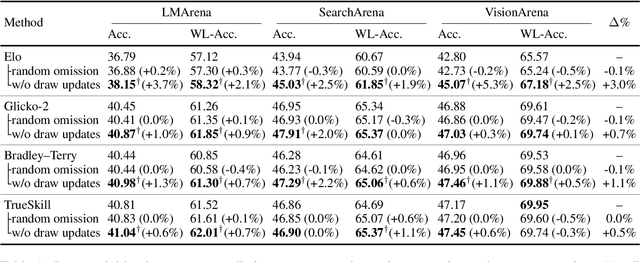
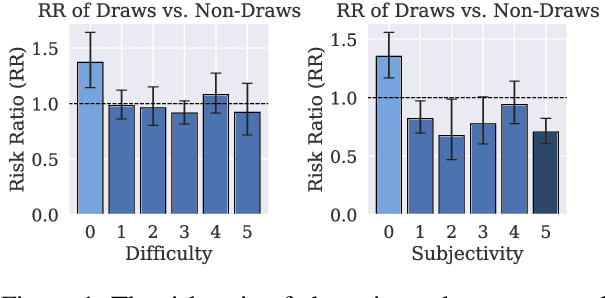
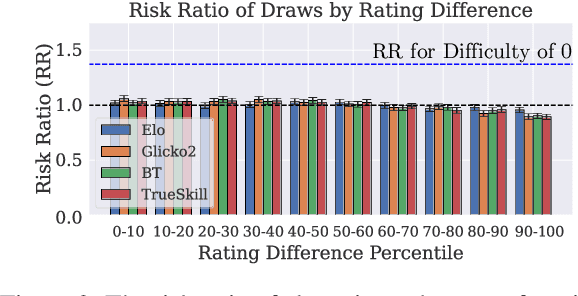
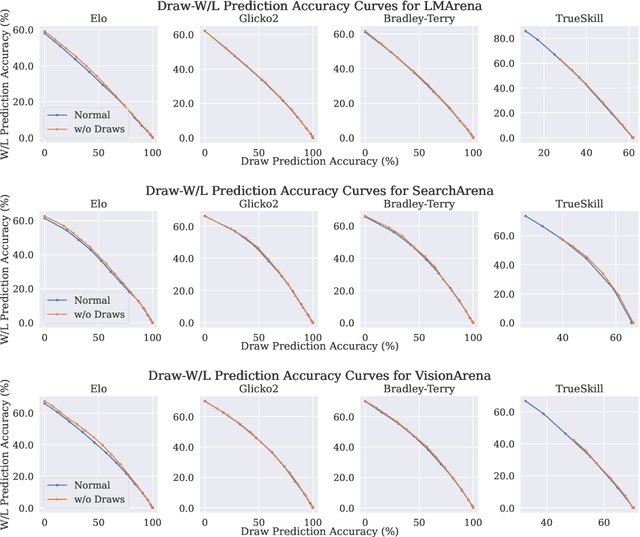
In arena-style evaluation of large language models (LLMs), two LLMs respond to a user query, and the user chooses the winning response or deems the "battle" a draw, resulting in an adjustment to the ratings of both models. The prevailing approach for modeling these rating dynamics is to view battles as two-player game matches, as in chess, and apply the Elo rating system and its derivatives. In this paper, we critically examine this paradigm. Specifically, we question whether a draw genuinely means that the two models are equal and hence whether their ratings should be equalized. Instead, we conjecture that draws are more indicative of query difficulty: if the query is too easy, then both models are more likely to succeed equally. On three real-world arena datasets, we show that ignoring rating updates for draws yields a 1-3% relative increase in battle outcome prediction accuracy (which includes draws) for all four rating systems studied. Further analyses suggest that draws occur more for queries rated as very easy and those as highly objective, with risk ratios of 1.37 and 1.35, respectively. We recommend future rating systems to reconsider existing draw semantics and to account for query properties in rating updates.
Translate, then Detect: Leveraging Machine Translation for Cross-Lingual Toxicity Classification
Sep 17, 2025



Multilingual toxicity detection remains a significant challenge due to the scarcity of training data and resources for many languages. While prior work has leveraged the translate-test paradigm to support cross-lingual transfer across a range of classification tasks, the utility of translation in supporting toxicity detection at scale remains unclear. In this work, we conduct a comprehensive comparison of translation-based and language-specific/multilingual classification pipelines. We find that translation-based pipelines consistently outperform out-of-distribution classifiers in 81.3% of cases (13 of 16 languages), with translation benefits strongly correlated with both the resource level of the target language and the quality of the machine translation (MT) system. Our analysis reveals that traditional classifiers outperform large language model (LLM) judges, with this advantage being particularly pronounced for low-resource languages, where translate-classify methods dominate translate-judge approaches in 6 out of 7 cases. We additionally show that MT-specific fine-tuning on LLMs yields lower refusal rates compared to standard instruction-tuned models, but it can negatively impact toxicity detection accuracy for low-resource languages. These findings offer actionable guidance for practitioners developing scalable multilingual content moderation systems.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
BIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
SSA-COMET: Do LLMs Outperform Learned Metrics in Evaluating MT for Under-Resourced African Languages?
Jun 05, 2025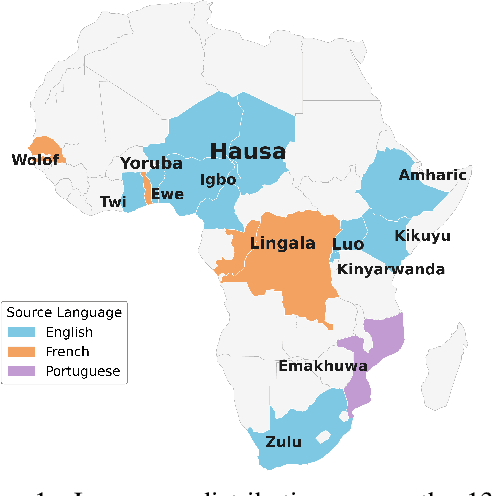
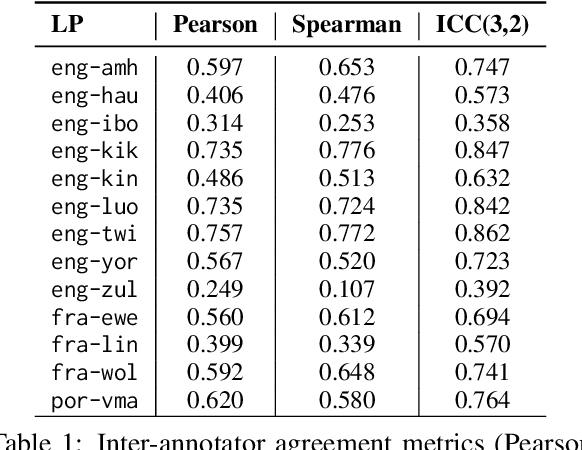
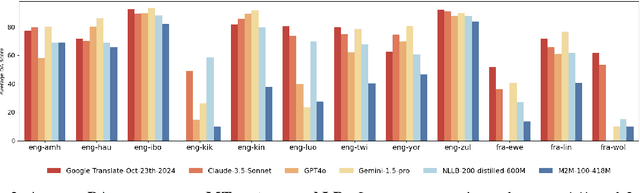
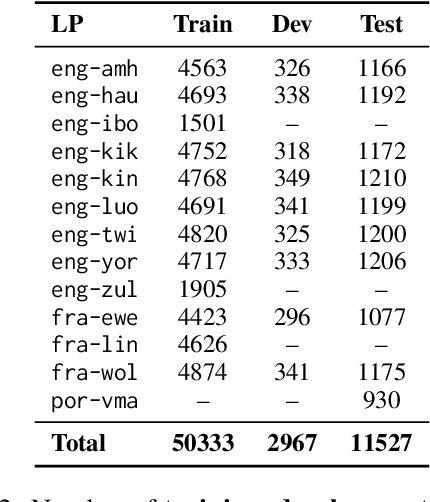
Evaluating machine translation (MT) quality for under-resourced African languages remains a significant challenge, as existing metrics often suffer from limited language coverage and poor performance in low-resource settings. While recent efforts, such as AfriCOMET, have addressed some of the issues, they are still constrained by small evaluation sets, a lack of publicly available training data tailored to African languages, and inconsistent performance in extremely low-resource scenarios. In this work, we introduce SSA-MTE, a large-scale human-annotated MT evaluation (MTE) dataset covering 13 African language pairs from the News domain, with over 63,000 sentence-level annotations from a diverse set of MT systems. Based on this data, we develop SSA-COMET and SSA-COMET-QE, improved reference-based and reference-free evaluation metrics. We also benchmark prompting-based approaches using state-of-the-art LLMs like GPT-4o and Claude. Our experimental results show that SSA-COMET models significantly outperform AfriCOMET and are competitive with the strongest LLM (Gemini 2.5 Pro) evaluated in our study, particularly on low-resource languages such as Twi, Luo, and Yoruba. All resources are released under open licenses to support future research.
Multilingual Language Model Pretraining using Machine-translated Data
Feb 18, 2025High-resource languages such as English, enables the pretraining of high-quality large language models (LLMs). The same can not be said for most other languages as LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated texts from a single high-quality source language can contribute significantly to the pretraining quality of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into nine languages, resulting in a 1.7-trillion-token dataset, which we call TransWebEdu and pretrain a 1.3B-parameter model, TransWebLLM, from scratch on this dataset. Across nine non-English reasoning tasks, we show that TransWebLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2, Qwen2.5, and Gemma, despite using an order of magnitude less data. We demonstrate that adding less than 5% of TransWebEdu as domain-specific pretraining data sets a new state-of-the-art in Arabic, Italian, Indonesian, Swahili, and Welsh understanding and commonsense reasoning tasks. To promote reproducibility, we release our corpus, models, and training pipeline under Open Source Initiative-approved licenses.
Warmup Generations: A Task-Agnostic Approach for Guiding Sequence-to-Sequence Learning with Unsupervised Initial State Generation
Feb 17, 2025



Traditional supervised fine-tuning (SFT) strategies for sequence-to-sequence tasks often train models to directly generate the target output. Recent work has shown that guiding models with intermediate steps, such as keywords, outlines, or reasoning chains, can significantly improve performance, coherence, and interpretability. However, these methods often depend on predefined intermediate formats and annotated data, limiting their scalability and generalizability. In this work, we introduce a task-agnostic framework that enables models to generate intermediate "warmup" sequences. These warmup sequences, serving as an initial state for subsequent generation, are optimized to enhance the probability of generating the target sequence without relying on external supervision or human-designed structures. Drawing inspiration from reinforcement learning principles, our method iteratively refines these intermediate steps to maximize their contribution to the final output, similar to reward-driven optimization in reinforcement learning with human feedback. Experimental results across tasks such as translation, summarization, and multi-choice question answering for logical reasoning show that our approach outperforms traditional SFT methods, and offers a scalable and flexible solution for sequence-to-sequence tasks.
Lost in Inference: Rediscovering the Role of Natural Language Inference for Large Language Models
Nov 21, 2024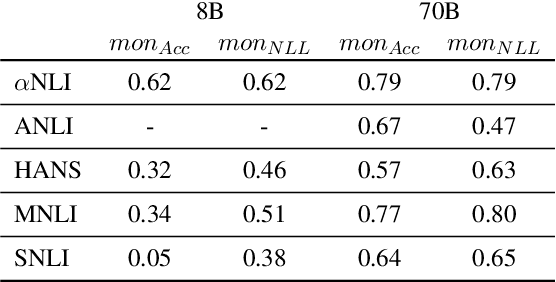
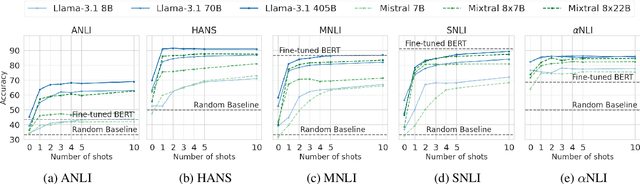
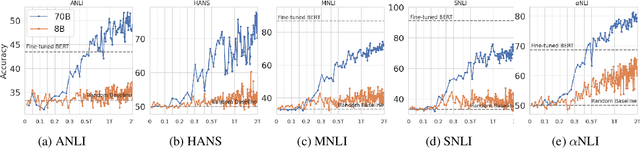

In the recent past, a popular way of evaluating natural language understanding (NLU), was to consider a model's ability to perform natural language inference (NLI) tasks. In this paper, we investigate if NLI tasks, that are rarely used for LLM evaluation, can still be informative for evaluating LLMs. Focusing on five different NLI benchmarks across six models of different scales, we investigate if they are able to discriminate models of different size and quality and how their accuracies develop during training. Furthermore, we investigate the extent to which the softmax distributions of models align with human distributions in cases where statements are ambiguous or vague. Overall, our results paint a positive picture for the NLI tasks: we find that they are able to discriminate well between models at various stages of training, yet are not (all) saturated. Furthermore, we find that while the similarity of model distributions with human label distributions increases with scale, it is still much higher than the similarity between two populations of humans, making it a potentially interesting statistic to consider.
Multilingual Pretraining Using a Large Corpus Machine-Translated from a Single Source Language
Oct 31, 2024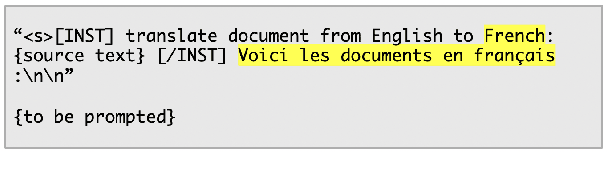
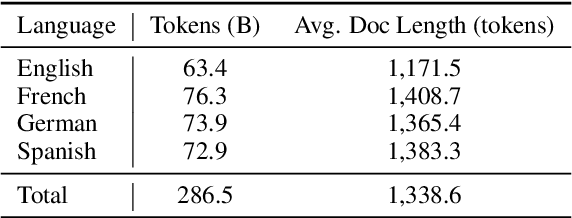
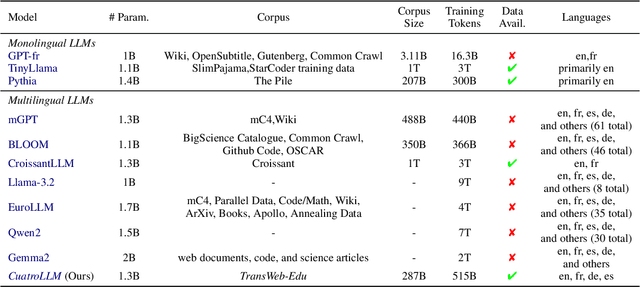
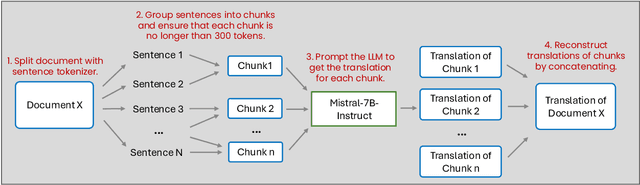
English, as a very high-resource language, enables the pretraining of high-quality large language models (LLMs). The same cannot be said for most other languages, as leading LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated text from a single high-quality source language can contribute significantly to the pretraining of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into French, German, and Spanish, resulting in a final 300B-token dataset, which we call TransWeb-Edu, and pretrain a 1.3B-parameter model, CuatroLLM, from scratch on this dataset. Across five non-English reasoning tasks, we show that CuatroLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2 and Gemma2, despite using an order of magnitude less data, such as about 6% of the tokens used for Llama3.2's training. We further demonstrate that with additional domain-specific pretraining, amounting to less than 1% of TransWeb-Edu, CuatroLLM surpasses the state of the art in multilingual reasoning. To promote reproducibility, we release our corpus, models, and training pipeline under open licenses at hf.co/britllm/CuatroLLM.