 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Language Model Pretraining using Machine-translated Data
Feb 18, 2025High-resource languages such as English, enables the pretraining of high-quality large language models (LLMs). The same can not be said for most other languages as LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated texts from a single high-quality source language can contribute significantly to the pretraining quality of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into nine languages, resulting in a 1.7-trillion-token dataset, which we call TransWebEdu and pretrain a 1.3B-parameter model, TransWebLLM, from scratch on this dataset. Across nine non-English reasoning tasks, we show that TransWebLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2, Qwen2.5, and Gemma, despite using an order of magnitude less data. We demonstrate that adding less than 5% of TransWebEdu as domain-specific pretraining data sets a new state-of-the-art in Arabic, Italian, Indonesian, Swahili, and Welsh understanding and commonsense reasoning tasks. To promote reproducibility, we release our corpus, models, and training pipeline under Open Source Initiative-approved licenses.
The Responsible Foundation Model Development Cheatsheet: A Review of Tools & Resources
Jun 26, 2024


Foundation model development attracts a rapidly expanding body of contributors, scientists, and applications. To help shape responsible development practices, we introduce the Foundation Model Development Cheatsheet: a growing collection of 250+ tools and resources spanning text, vision, and speech modalities. We draw on a large body of prior work to survey resources (e.g. software, documentation, frameworks, guides, and practical tools) that support informed data selection, processing, and understanding, precise and limitation-aware artifact documentation, efficient model training, advance awareness of the environmental impact from training, careful model evaluation of capabilities, risks, and claims, as well as responsible model release, licensing and deployment practices. We hope this curated collection of resources helps guide more responsible development. The process of curating this list, enabled us to review the AI development ecosystem, revealing what tools are critically missing, misused, or over-used in existing practices. We find that (i) tools for data sourcing, model evaluation, and monitoring are critically under-serving ethical and real-world needs, (ii) evaluations for model safety, capabilities, and environmental impact all lack reproducibility and transparency, (iii) text and particularly English-centric analyses continue to dominate over multilingual and multi-modal analyses, and (iv) evaluation of systems, rather than just models, is needed so that capabilities and impact are assessed in context.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023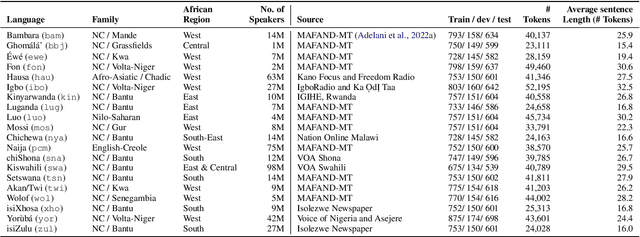
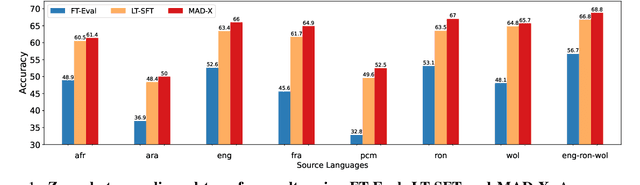
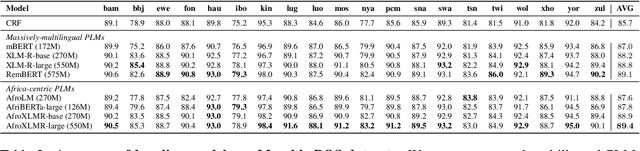
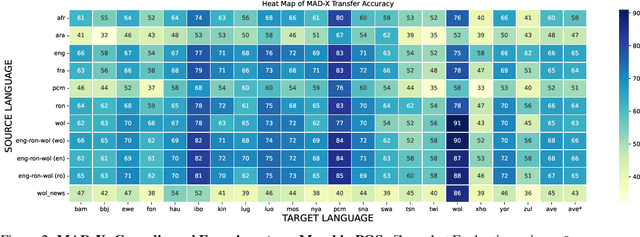
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
$\varepsilon$ KÚ <MASK>: Integrating Yorùbá cultural greetings into machine translation
Apr 24, 2023This paper investigates the performance of massively multilingual neural machine translation (NMT) systems in translating Yor\`ub\'a greetings ($\varepsilon$ k\'u [MASK]), which are a big part of Yor\`ub\'a language and culture, into English. To evaluate these models, we present IkiniYor\`ub\'a, a Yor\`ub\'a-English translation dataset containing some Yor\`ub\'a greetings, and sample use cases. We analysed the performance of different multilingual NMT systems including Google and NLLB and show that these models struggle to accurately translate Yor\`ub\'a greetings into English. In addition, we trained a Yor\`ub\'a-English model by finetuning an existing NMT model on the training split of IkiniYor\`ub\'a and this achieved better performance when compared to the pre-trained multilingual NMT models, although they were trained on a large volume of data.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023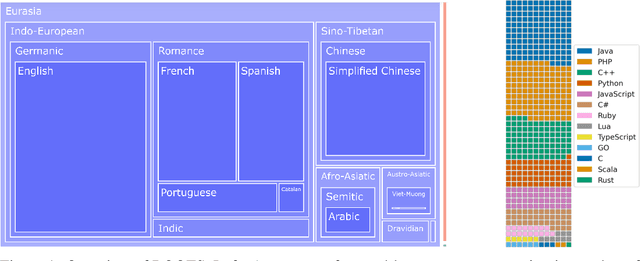


As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
Transfer Learning and Distant Supervision for Multilingual Transformer Models: A Study on African Languages
Oct 07, 2020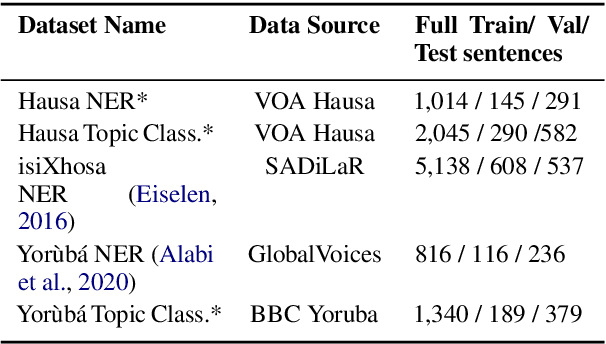
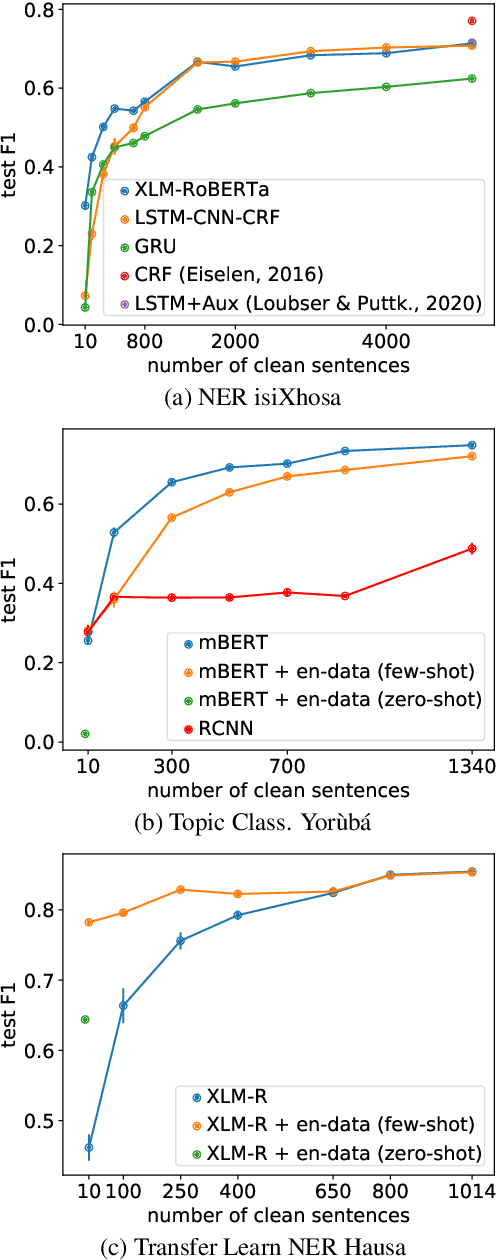
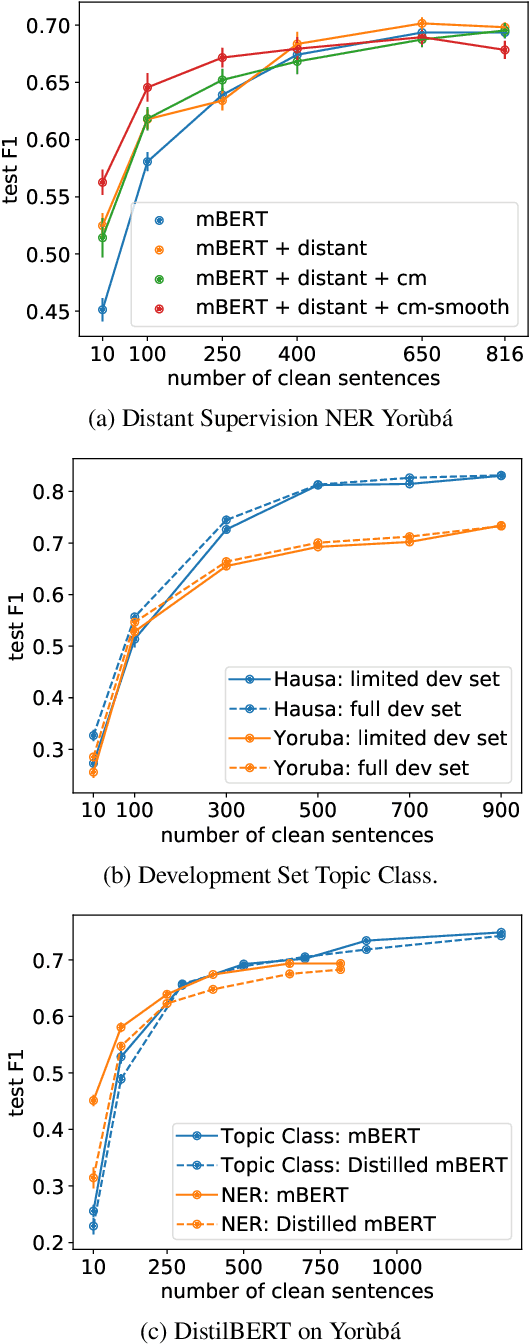
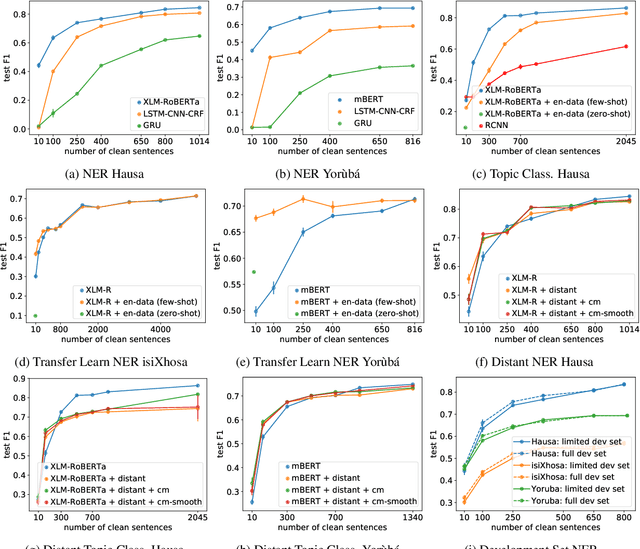
Multilingual transformer models like mBERT and XLM-RoBERTa have obtained great improvements for many NLP tasks on a variety of languages. However, recent works also showed that results from high-resource languages could not be easily transferred to realistic, low-resource scenarios. In this work, we study trends in performance for different amounts of available resources for the three African languages Hausa, isiXhosa and Yor\`ub\'a on both NER and topic classification. We show that in combination with transfer learning or distant supervision, these models can achieve with as little as 10 or 100 labeled sentences the same performance as baselines with much more supervised training data. However, we also find settings where this does not hold. Our discussions and additional experiments on assumptions such as time and hardware restrictions highlight challenges and opportunities in low-resource learning.
Demographic Inference and Representative Population Estimates from Multilingual Social Media Data
May 15, 2019
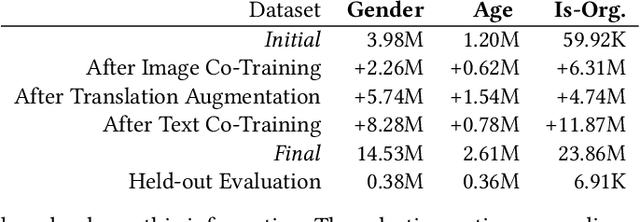
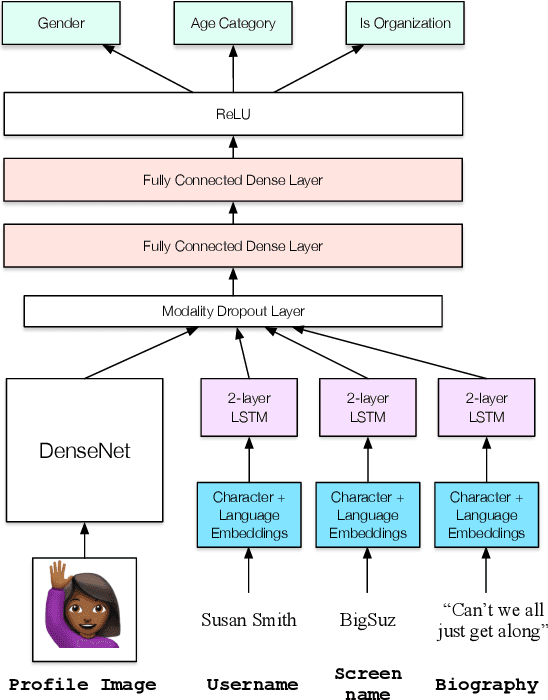

Social media provide access to behavioural data at an unprecedented scale and granularity. However, using these data to understand phenomena in a broader population is difficult due to their non-representativeness and the bias of statistical inference tools towards dominant languages and groups. While demographic attribute inference could be used to mitigate such bias, current techniques are almost entirely monolingual and fail to work in a global environment. We address these challenges by combining multilingual demographic inference with post-stratification to create a more representative population sample. To learn demographic attributes, we create a new multimodal deep neural architecture for joint classification of age, gender, and organization-status of social media users that operates in 32 languages. This method substantially outperforms current state of the art while also reducing algorithmic bias. To correct for sampling biases, we propose fully interpretable multilevel regression methods that estimate inclusion probabilities from inferred joint population counts and ground-truth population counts. In a large experiment over multilingual heterogeneous European regions, we show that our demographic inference and bias correction together allow for more accurate estimates of populations and make a significant step towards representative social sensing in downstream applications with multilingual social media.
* 12 pages, 10 figures, Proceedings of the 2019 World Wide Web Conference (WWW '19)