 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Investigating Global News Coverage of Critical Events Such as Disasters and Terrorist Attacks
Jun 15, 2025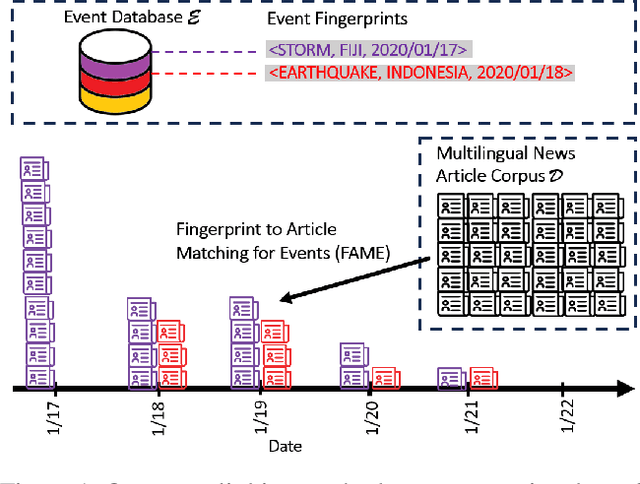

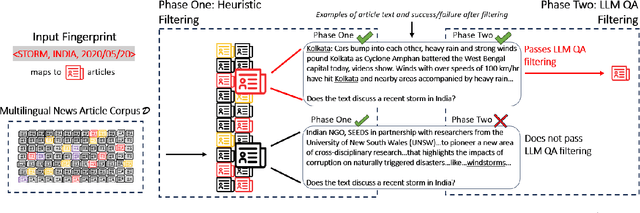
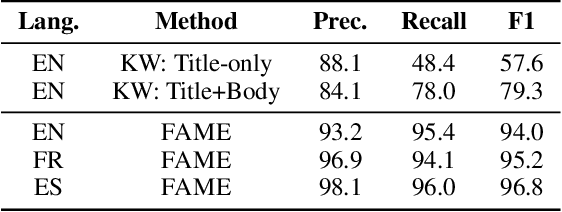
Comparative studies of news coverage are challenging to conduct because methods to identify news articles about the same event in different languages require expertise that is difficult to scale. We introduce an AI-powered method for identifying news articles based on an event FINGERPRINT, which is a minimal set of metadata required to identify critical events. Our event coverage identification method, FINGERPRINT TO ARTICLE MATCHING FOR EVENTS (FAME), efficiently identifies news articles about critical world events, specifically terrorist attacks and several types of natural disasters. FAME does not require training data and is able to automatically and efficiently identify news articles that discuss an event given its fingerprint: time, location, and class (such as storm or flood). The method achieves state-of-the-art performance and scales to massive databases of tens of millions of news articles and hundreds of events happening globally. We use FAME to identify 27,441 articles that cover 470 natural disaster and terrorist attack events that happened in 2020. To this end, we use a massive database of news articles in three languages from MediaCloud, and three widely used, expert-curated databases of critical events: EM-DAT, USGS, and GTD. Our case study reveals patterns consistent with prior literature: coverage of disasters and terrorist attacks correlates to death counts, to the GDP of a country where the event occurs, and to trade volume between the reporting country and the country where the event occurred. We share our NLP annotations and cross-country media attention data to support the efforts of researchers and media monitoring organizations.
A Multilingual Similarity Dataset for News Article Frame
May 22, 2024Understanding the writing frame of news articles is vital for addressing social issues, and thus has attracted notable attention in the fields of communication studies. Yet, assessing such news article frames remains a challenge due to the absence of a concrete and unified standard dataset that considers the comprehensive nuances within news content. To address this gap, we introduce an extended version of a large labeled news article dataset with 16,687 new labeled pairs. Leveraging the pairwise comparison of news articles, our method frees the work of manual identification of frame classes in traditional news frame analysis studies. Overall we introduce the most extensive cross-lingual news article similarity dataset available to date with 26,555 labeled news article pairs across 10 languages. Each data point has been meticulously annotated according to a codebook detailing eight critical aspects of news content, under a human-in-the-loop framework. Application examples demonstrate its potential in unearthing country communities within global news coverage, exposing media bias among news outlets, and quantifying the factors related to news creation. We envision that this news similarity dataset will broaden our understanding of the media ecosystem in terms of news coverage of events and perspectives across countries, locations, languages, and other social constructs. By doing so, it can catalyze advancements in social science research and applied methodologies, thereby exerting a profound impact on our society.
Global News Synchrony and Diversity During the Start of the COVID-19 Pandemic
May 01, 2024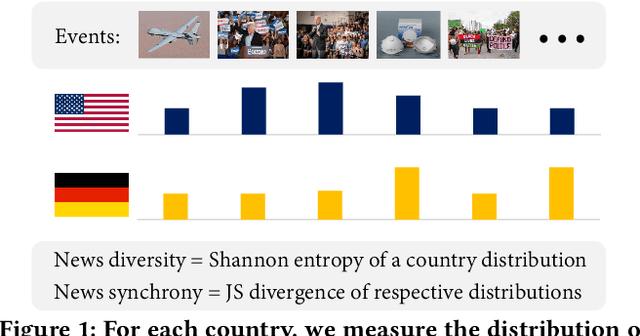
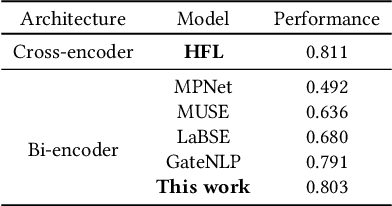
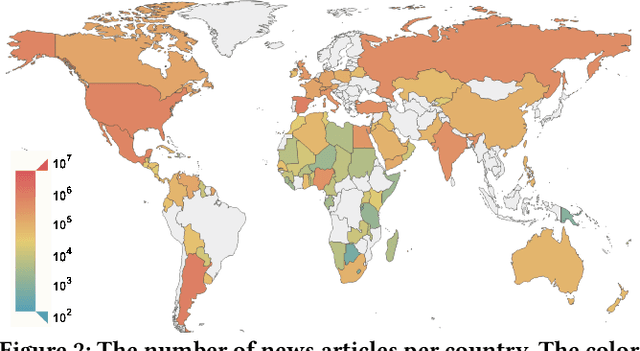

News coverage profoundly affects how countries and individuals behave in international relations. Yet, we have little empirical evidence of how news coverage varies across countries. To enable studies of global news coverage, we develop an efficient computational methodology that comprises three components: (i) a transformer model to estimate multilingual news similarity; (ii) a global event identification system that clusters news based on a similarity network of news articles; and (iii) measures of news synchrony across countries and news diversity within a country, based on country-specific distributions of news coverage of the global events. Each component achieves state-of-the art performance, scaling seamlessly to massive datasets of millions of news articles. We apply the methodology to 60 million news articles published globally between January 1 and June 30, 2020, across 124 countries and 10 languages, detecting 4357 news events. We identify the factors explaining diversity and synchrony of news coverage across countries. Our study reveals that news media tend to cover a more diverse set of events in countries with larger Internet penetration, more official languages, larger religious diversity, higher economic inequality, and larger populations. Coverage of news events is more synchronized between countries that not only actively participate in commercial and political relations -- such as, pairs of countries with high bilateral trade volume, and countries that belong to the NATO military alliance or BRICS group of major emerging economies -- but also countries that share certain traits: an official language, high GDP, and high democracy indices.
Automated Model Selection for Tabular Data
Jan 01, 2024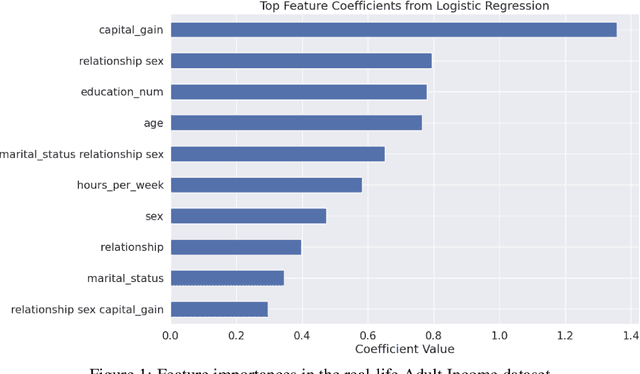

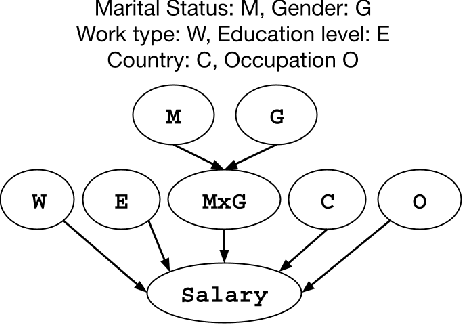
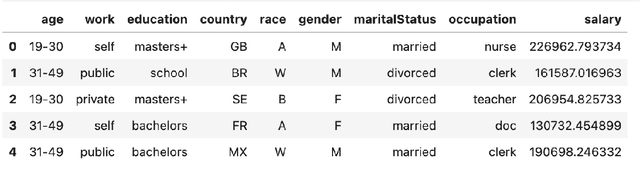
Structured data in the form of tabular datasets contain features that are distinct and discrete, with varying individual and relative importances to the target. Combinations of one or more features may be more predictive and meaningful than simple individual feature contributions. R's mixed effect linear models library allows users to provide such interactive feature combinations in the model design. However, given many features and possible interactions to select from, model selection becomes an exponentially difficult task. We aim to automate the model selection process for predictions on tabular datasets incorporating feature interactions while keeping computational costs small. The framework includes two distinct approaches for feature selection: a Priority-based Random Grid Search and a Greedy Search method. The Priority-based approach efficiently explores feature combinations using prior probabilities to guide the search. The Greedy method builds the solution iteratively by adding or removing features based on their impact. Experiments on synthetic demonstrate the ability to effectively capture predictive feature combinations.
Supervised learning algorithms resilient to discriminatory data perturbations
Dec 17, 2019
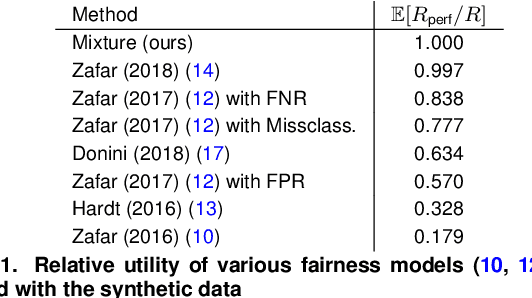
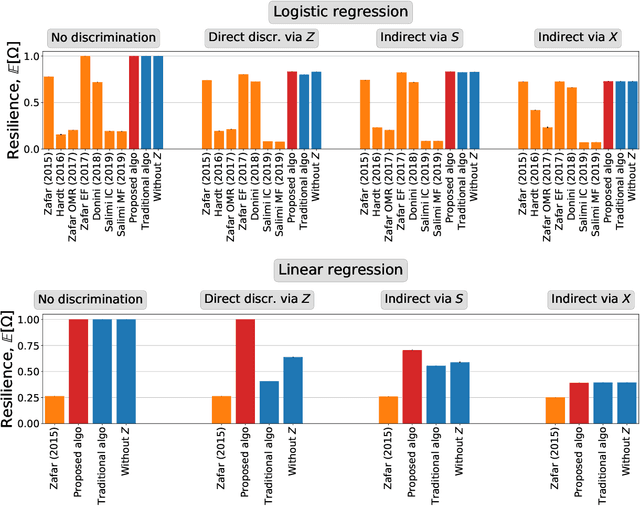

The actions of individuals can be discriminatory with respect to certain protected attributes, such as race or sex. Recently, discrimination has become a focal concern in supervised learning algorithms augmenting human decision-making. These systems are trained using historical data, which may have been tainted by discrimination, and may learn biases against the protected groups. An important question is how to train models without propagating discrimination. Such discrimination can be either direct, when one or more of protected attributes are used in the decision-making directly, or indirect, when other attributes correlated with the protected attributes are used in an unjustified manner. In this work, we i) model discrimination as a perturbation of data-generating process; ii) introduce a measure of resilience of a supervised learning algorithm to potentially discriminatory data perturbations; and iii) propose a novel supervised learning method that is more resilient to such discriminatory perturbations than state-of-the-art learning algorithms addressing discrimination. The proposed method can be used with general supervised learning algorithms, prevents direct discrimination and avoids inducement of indirect discrimination, while maximizing model accuracy.
Demographic Inference and Representative Population Estimates from Multilingual Social Media Data
May 15, 2019
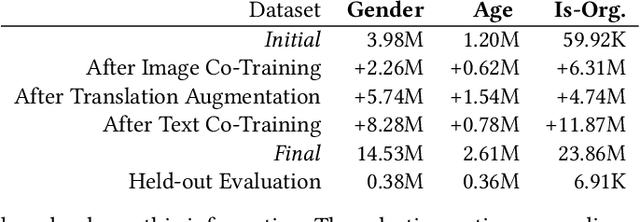
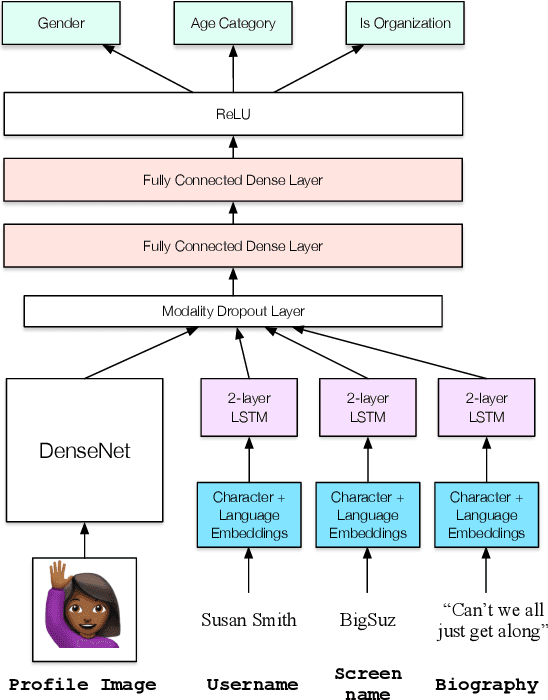

Social media provide access to behavioural data at an unprecedented scale and granularity. However, using these data to understand phenomena in a broader population is difficult due to their non-representativeness and the bias of statistical inference tools towards dominant languages and groups. While demographic attribute inference could be used to mitigate such bias, current techniques are almost entirely monolingual and fail to work in a global environment. We address these challenges by combining multilingual demographic inference with post-stratification to create a more representative population sample. To learn demographic attributes, we create a new multimodal deep neural architecture for joint classification of age, gender, and organization-status of social media users that operates in 32 languages. This method substantially outperforms current state of the art while also reducing algorithmic bias. To correct for sampling biases, we propose fully interpretable multilevel regression methods that estimate inclusion probabilities from inferred joint population counts and ground-truth population counts. In a large experiment over multilingual heterogeneous European regions, we show that our demographic inference and bias correction together allow for more accurate estimates of populations and make a significant step towards representative social sensing in downstream applications with multilingual social media.
* 12 pages, 10 figures, Proceedings of the 2019 World Wide Web Conference (WWW '19)