 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating lookahead planning using site appearance and space utilization
Nov 30, 2023



This study proposes a method to automate the development of lookahead planning. The proposed method uses construction material conditions (i.e., appearances) and site space utilization to predict task completion rates. A Gated Recurrent Unit (GRU) based Recurrent Neural Network (RNN) model was trained using a segment of a construction project timeline to estimate completion rates of tasks and propose data-aware lookahead plans. The proposed method was evaluated in a sample construction project involving finishing works such as plastering, painting, and installing electrical fixtures. The results show that the proposed method can assist with developing automated lookahead plans. In doing so, this study links construction planning with actual events at the construction site. It extends the traditional scheduling techniques and integrates a broader spectrum of site spatial constraints into lookahead planning.
COIN: Counterfactual Image Generation for VQA Interpretation
Jan 10, 2022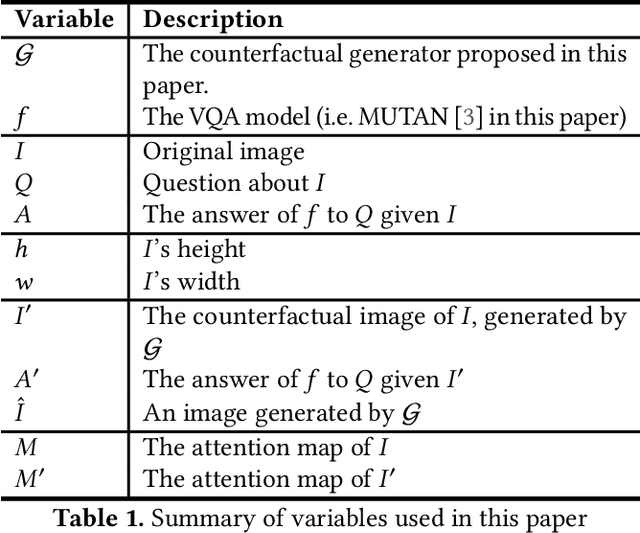

Due to the significant advancement of Natural Language Processing and Computer Vision-based models, Visual Question Answering (VQA) systems are becoming more intelligent and advanced. However, they are still error-prone when dealing with relatively complex questions. Therefore, it is important to understand the behaviour of the VQA models before adopting their results. In this paper, we introduce an interpretability approach for VQA models by generating counterfactual images. Specifically, the generated image is supposed to have the minimal possible change to the original image and leads the VQA model to give a different answer. In addition, our approach ensures that the generated image is realistic. Since quantitative metrics cannot be employed to evaluate the interpretability of the model, we carried out a user study to assess different aspects of our approach. In addition to interpreting the result of VQA models on single images, the obtained results and the discussion provides an extensive explanation of VQA models' behaviour.
MexPub: Deep Transfer Learning for Metadata Extraction from German Publications
Jun 04, 2021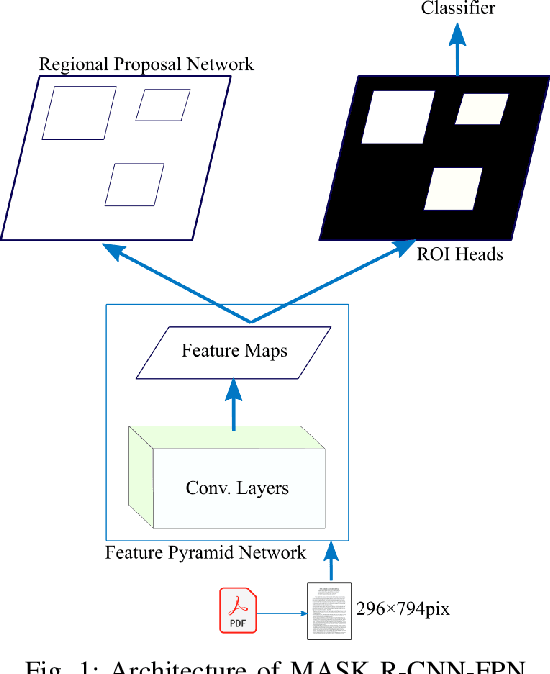


Extracting metadata from scientific papers can be considered a solved problem in NLP due to the high accuracy of state-of-the-art methods. However, this does not apply to German scientific publications, which have a variety of styles and layouts. In contrast to most of the English scientific publications that follow standard and simple layouts, the order, content, position and size of metadata in German publications vary greatly among publications. This variety makes traditional NLP methods fail to accurately extract metadata from these publications. In this paper, we present a method that extracts metadata from PDF documents with different layouts and styles by viewing the document as an image. We used Mask R-CNN that is trained on COCO dataset and finetuned with PubLayNet dataset that consists of ~200K PDF snapshots with five basic classes (e.g. text, figure, etc). We refine-tuned the model on our proposed synthetic dataset consisting of ~30K article snapshots to extract nine patterns (i.e. author, title, etc). Our synthetic dataset is generated using contents in both languages German and English and a finite set of challenging templates obtained from German publications. Our method achieved an average accuracy of around $90\%$ which validates its capability to accurately extract metadata from a variety of PDF documents with challenging templates.
Demographic Inference and Representative Population Estimates from Multilingual Social Media Data
May 15, 2019
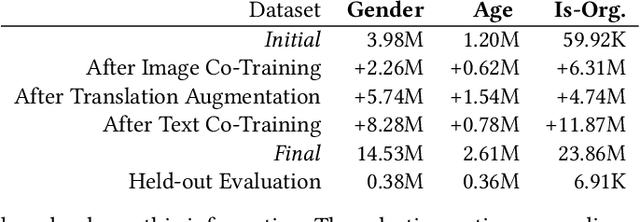
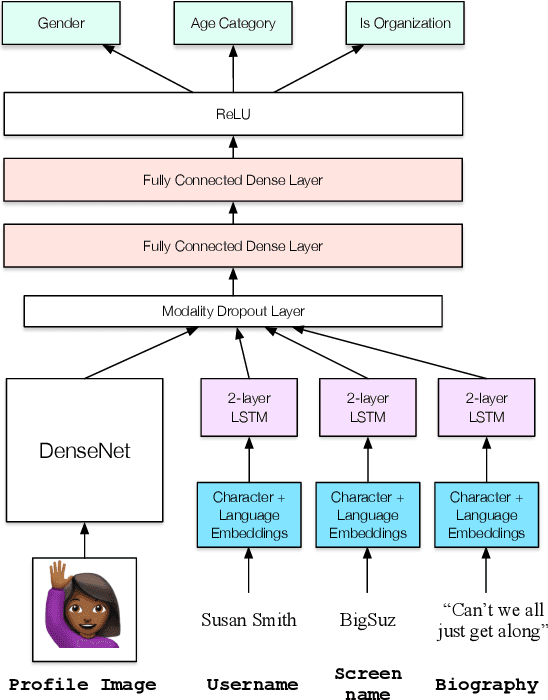

Social media provide access to behavioural data at an unprecedented scale and granularity. However, using these data to understand phenomena in a broader population is difficult due to their non-representativeness and the bias of statistical inference tools towards dominant languages and groups. While demographic attribute inference could be used to mitigate such bias, current techniques are almost entirely monolingual and fail to work in a global environment. We address these challenges by combining multilingual demographic inference with post-stratification to create a more representative population sample. To learn demographic attributes, we create a new multimodal deep neural architecture for joint classification of age, gender, and organization-status of social media users that operates in 32 languages. This method substantially outperforms current state of the art while also reducing algorithmic bias. To correct for sampling biases, we propose fully interpretable multilevel regression methods that estimate inclusion probabilities from inferred joint population counts and ground-truth population counts. In a large experiment over multilingual heterogeneous European regions, we show that our demographic inference and bias correction together allow for more accurate estimates of populations and make a significant step towards representative social sensing in downstream applications with multilingual social media.
* 12 pages, 10 figures, Proceedings of the 2019 World Wide Web Conference (WWW '19)