 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble and Multimodal Approach for Forecasting Cryptocurrency Price
Feb 12, 2022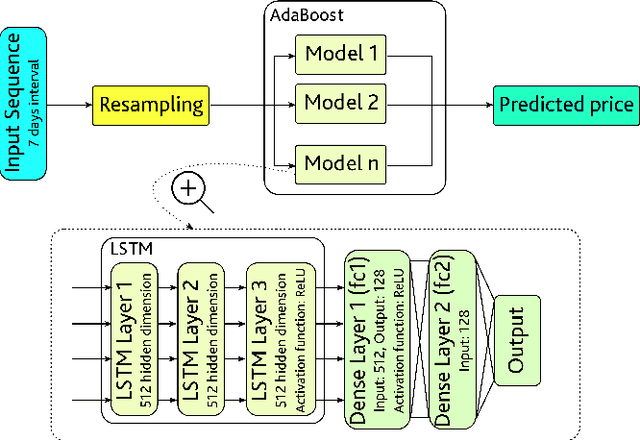
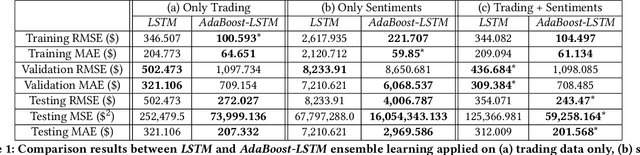
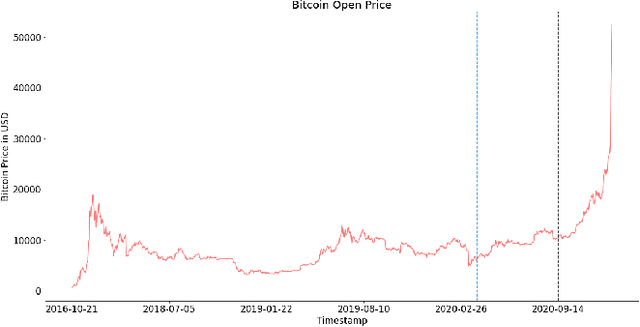
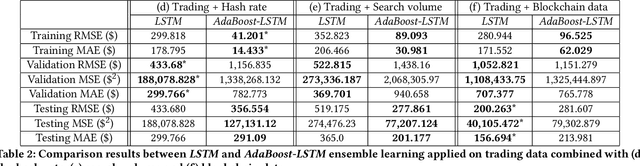
Since the birth of Bitcoin in 2009, cryptocurrencies have emerged to become a global phenomenon and an important decentralized financial asset. Due to this decentralization, the value of these digital currencies against fiat currencies is highly volatile over time. Therefore, forecasting the crypto-fiat currency exchange rate is an extremely challenging task. For reliable forecasting, this paper proposes a multimodal AdaBoost-LSTM ensemble approach that employs all modalities which derive price fluctuation such as social media sentiments, search volumes, blockchain information, and trading data. To better support investment decision making, the approach forecasts also the fluctuation distribution. The conducted extensive experiments demonstrated the effectiveness of relying on multimodalities instead of only trading data. Further experiments demonstrate the outperformance of the proposed approach compared to existing tools and methods with a 19.29% improvement.
COIN: Counterfactual Image Generation for VQA Interpretation
Jan 10, 2022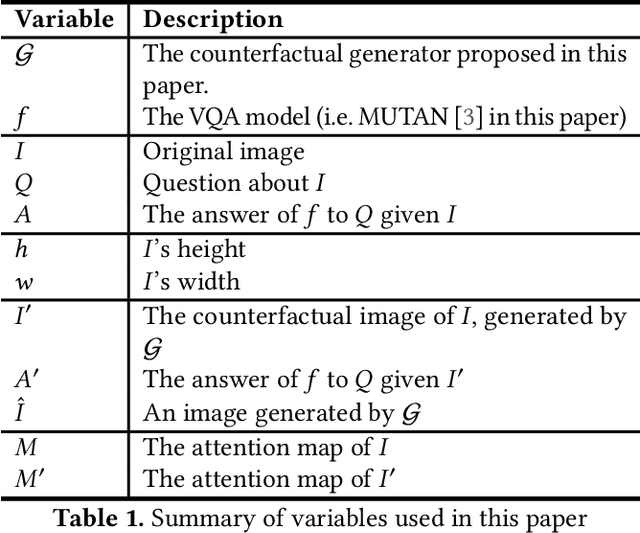
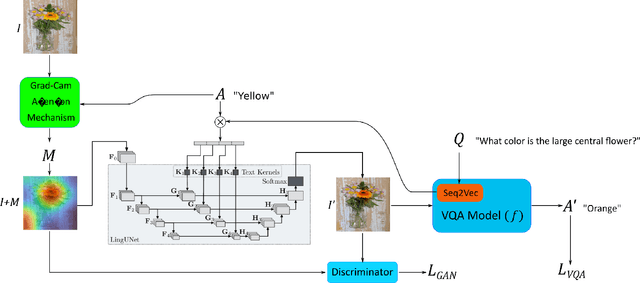

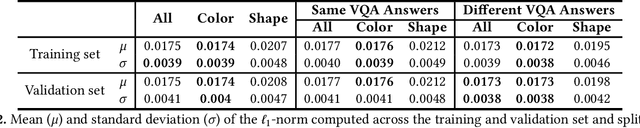
Due to the significant advancement of Natural Language Processing and Computer Vision-based models, Visual Question Answering (VQA) systems are becoming more intelligent and advanced. However, they are still error-prone when dealing with relatively complex questions. Therefore, it is important to understand the behaviour of the VQA models before adopting their results. In this paper, we introduce an interpretability approach for VQA models by generating counterfactual images. Specifically, the generated image is supposed to have the minimal possible change to the original image and leads the VQA model to give a different answer. In addition, our approach ensures that the generated image is realistic. Since quantitative metrics cannot be employed to evaluate the interpretability of the model, we carried out a user study to assess different aspects of our approach. In addition to interpreting the result of VQA models on single images, the obtained results and the discussion provides an extensive explanation of VQA models' behaviour.