 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSGen: Enhancing Layout-Driven Remote Sensing Image Generation with Diverse Edge Guidance
Mar 17, 2026Diffusion models have significantly mitigated the impact of annotated data scarcity in remote sensing (RS). Although recent approaches have successfully harnessed these models to enable diverse and controllable Layout-to-Image (L2I) synthesis, they still suffer from limited fine-grained control and fail to strictly adhere to bounding box constraints. To address these limitations, we propose RSGen, a plug-and-play framework that leverages diverse edge guidance to enhance layout-driven RS image generation. Specifically, RSGen employs a progressive enhancement strategy: 1) it first enriches the diversity of edge maps composited from retrieved training instances via Image-to-Image generation; and 2) subsequently utilizes these diverse edge maps as conditioning for existing L2I models to enforce pixel-level control within bounding boxes, ensuring the generated instances strictly adhere to the layout. Extensive experiments across three baseline models demonstrate that RSGen significantly boosts the capabilities of existing L2I models. For instance, with CC-Diff on the DOTA dataset for oriented object detection, we achieve remarkable gains of +9.8/+12.0 in YOLOScore mAP50/mAP50-95 and +1.6 in mAP on the downstream detection task. Our code will be publicly available: https://github.com/D-Robotics-AI-Lab/RSGen
Exploring the Limits of Model Compression in LLMs: A Knowledge Distillation Study on QA Tasks
Jul 10, 2025



Large Language Models (LLMs) have demonstrated outstanding performance across a range of NLP tasks, however, their computational demands hinder their deployment in real-world, resource-constrained environments. This work investigates the extent to which LLMs can be compressed using Knowledge Distillation (KD) while maintaining strong performance on Question Answering (QA) tasks. We evaluate student models distilled from the Pythia and Qwen2.5 families on two QA benchmarks, SQuAD and MLQA, under zero-shot and one-shot prompting conditions. Results show that student models retain over 90% of their teacher models' performance while reducing parameter counts by up to 57.1%. Furthermore, one-shot prompting yields additional performance gains over zero-shot setups for both model families. These findings underscore the trade-off between model efficiency and task performance, demonstrating that KD, combined with minimal prompting, can yield compact yet capable QA systems suitable for resource-constrained applications.
EMORL: Ensemble Multi-Objective Reinforcement Learning for Efficient and Flexible LLM Fine-Tuning
May 05, 2025Recent advances in reinforcement learning (RL) for large language model (LLM) fine-tuning show promise in addressing multi-objective tasks but still face significant challenges, including complex objective balancing, low training efficiency, poor scalability, and limited explainability. Leveraging ensemble learning principles, we introduce an Ensemble Multi-Objective RL (EMORL) framework that fine-tunes multiple models with individual objectives while optimizing their aggregation after the training to improve efficiency and flexibility. Our method is the first to aggregate the last hidden states of individual models, incorporating contextual information from multiple objectives. This approach is supported by a hierarchical grid search algorithm that identifies optimal weighted combinations. We evaluate EMORL on counselor reflection generation tasks, using text-scoring LLMs to evaluate the generations and provide rewards during RL fine-tuning. Through comprehensive experiments on the PAIR and Psych8k datasets, we demonstrate the advantages of EMORL against existing baselines: significantly lower and more stable training consumption ($17,529\pm 1,650$ data points and $6,573\pm 147.43$ seconds), improved scalability and explainability, and comparable performance across multiple objectives.
ELMTEX: Fine-Tuning Large Language Models for Structured Clinical Information Extraction. A Case Study on Clinical Reports
Feb 08, 2025Europe's healthcare systems require enhanced interoperability and digitalization, driving a demand for innovative solutions to process legacy clinical data. This paper presents the results of our project, which aims to leverage Large Language Models (LLMs) to extract structured information from unstructured clinical reports, focusing on patient history, diagnoses, treatments, and other predefined categories. We developed a workflow with a user interface and evaluated LLMs of varying sizes through prompting strategies and fine-tuning. Our results show that fine-tuned smaller models match or surpass larger counterparts in performance, offering efficiency for resource-limited settings. A new dataset of 60,000 annotated English clinical summaries and 24,000 German translations was validated with automated and manual checks. The evaluations used ROUGE, BERTScore, and entity-level metrics. The work highlights the approach's viability and outlines future improvements.
Comparison of Feature Learning Methods for Metadata Extraction from PDF Scholarly Documents
Jan 09, 2025



The availability of metadata for scientific documents is pivotal in propelling scientific knowledge forward and for adhering to the FAIR principles (i.e. Findability, Accessibility, Interoperability, and Reusability) of research findings. However, the lack of sufficient metadata in published documents, particularly those from smaller and mid-sized publishers, hinders their accessibility. This issue is widespread in some disciplines, such as the German Social Sciences, where publications often employ diverse templates. To address this challenge, our study evaluates various feature learning and prediction methods, including natural language processing (NLP), computer vision (CV), and multimodal approaches, for extracting metadata from documents with high template variance. We aim to improve the accessibility of scientific documents and facilitate their wider use. To support our comparison of these methods, we provide comprehensive experimental results, analyzing their accuracy and efficiency in extracting metadata. Additionally, we provide valuable insights into the strengths and weaknesses of various feature learning and prediction methods, which can guide future research in this field.
Large Language Model in Medical Informatics: Direct Classification and Enhanced Text Representations for Automatic ICD Coding
Nov 11, 2024

Addressing the complexity of accurately classifying International Classification of Diseases (ICD) codes from medical discharge summaries is challenging due to the intricate nature of medical documentation. This paper explores the use of Large Language Models (LLM), specifically the LLAMA architecture, to enhance ICD code classification through two methodologies: direct application as a classifier and as a generator of enriched text representations within a Multi-Filter Residual Convolutional Neural Network (MultiResCNN) framework. We evaluate these methods by comparing them against state-of-the-art approaches, revealing LLAMA's potential to significantly improve classification outcomes by providing deep contextual insights into medical texts.
Falcon 7b for Software Mention Detection in Scholarly Documents
May 14, 2024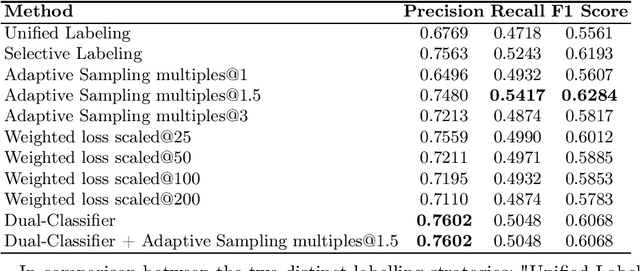
This paper aims to tackle the challenge posed by the increasing integration of software tools in research across various disciplines by investigating the application of Falcon-7b for the detection and classification of software mentions within scholarly texts. Specifically, the study focuses on solving Subtask I of the Software Mention Detection in Scholarly Publications (SOMD), which entails identifying and categorizing software mentions from academic literature. Through comprehensive experimentation, the paper explores different training strategies, including a dual-classifier approach, adaptive sampling, and weighted loss scaling, to enhance detection accuracy while overcoming the complexities of class imbalance and the nuanced syntax of scholarly writing. The findings highlight the benefits of selective labelling and adaptive sampling in improving the model's performance. However, they also indicate that integrating multiple strategies does not necessarily result in cumulative improvements. This research offers insights into the effective application of large language models for specific tasks such as SOMD, underlining the importance of tailored approaches to address the unique challenges presented by academic text analysis.
Gyroscope-Assisted Motion Deblurring Network
Feb 10, 2024



Image research has shown substantial attention in deblurring networks in recent years. Yet, their practical usage in real-world deblurring, especially motion blur, remains limited due to the lack of pixel-aligned training triplets (background, blurred image, and blur heat map) and restricted information inherent in blurred images. This paper presents a simple yet efficient framework to synthetic and restore motion blur images using Inertial Measurement Unit (IMU) data. Notably, the framework includes a strategy for training triplet generation, and a Gyroscope-Aided Motion Deblurring (GAMD) network for blurred image restoration. The rationale is that through harnessing IMU data, we can determine the transformation of the camera pose during the image exposure phase, facilitating the deduction of the motion trajectory (aka. blur trajectory) for each point inside the three-dimensional space. Thus, the synthetic triplets using our strategy are inherently close to natural motion blur, strictly pixel-aligned, and mass-producible. Through comprehensive experiments, we demonstrate the advantages of the proposed framework: only two-pixel errors between our synthetic and real-world blur trajectories, a marked improvement (around 33.17%) of the state-of-the-art deblurring method MIMO on Peak Signal-to-Noise Ratio (PSNR).
Skeleton Ground Truth Extraction: Methodology, Annotation Tool and Benchmarks
Oct 10, 2023Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN) but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target's context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
PADME-SoSci: A Platform for Analytics and Distributed Machine Learning for the Social Sciences
Apr 03, 2023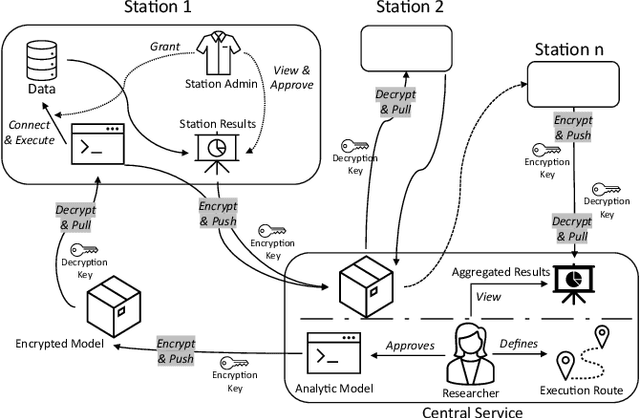
Data privacy and ownership are significant in social data science, raising legal and ethical concerns. Sharing and analyzing data is difficult when different parties own different parts of it. An approach to this challenge is to apply de-identification or anonymization techniques to the data before collecting it for analysis. However, this can reduce data utility and increase the risk of re-identification. To address these limitations, we present PADME, a distributed analytics tool that federates model implementation and training. PADME uses a federated approach where the model is implemented and deployed by all parties and visits each data location incrementally for training. This enables the analysis of data across locations while still allowing the model to be trained as if all data were in a single location. Training the model on data in its original location preserves data ownership. Furthermore, the results are not provided until the analysis is completed on all data locations to ensure privacy and avoid bias in the results.