 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Computational Reproducibility in Social Science: Comparing Prompt-Based and Agent-Based Approaches
Feb 09, 2026Reproducing computational research is often assumed to be as simple as rerunning the original code with provided data. In practice, missing packages, fragile file paths, version conflicts, or incomplete logic frequently cause analyses to fail, even when materials are shared. This study investigates whether large language models and AI agents can automate the diagnosis and repair of such failures, making computational results easier to reproduce and verify. We evaluate this using a controlled reproducibility testbed built from five fully reproducible R-based social science studies. Realistic failures were injected, ranging from simple issues to complex missing logic, and two automated repair workflows were tested in clean Docker environments. The first workflow is prompt-based, repeatedly querying language models with structured prompts of varying context, while the second uses agent-based systems that inspect files, modify code, and rerun analyses autonomously. Across prompt-based runs, reproduction success ranged from 31-79 percent, with performance strongly influenced by prompt context and error complexity. Complex cases benefited most from additional context. Agent-based workflows performed substantially better, with success rates of 69-96 percent across all complexity levels. These results suggest that automated workflows, especially agent-based systems, can significantly reduce manual effort and improve reproduction success across diverse error types. Unlike prior benchmarks, our testbed isolates post-publication repair under controlled failure modes, allowing direct comparison of prompt-based and agent-based approaches.
PADME-SoSci: A Platform for Analytics and Distributed Machine Learning for the Social Sciences
Apr 03, 2023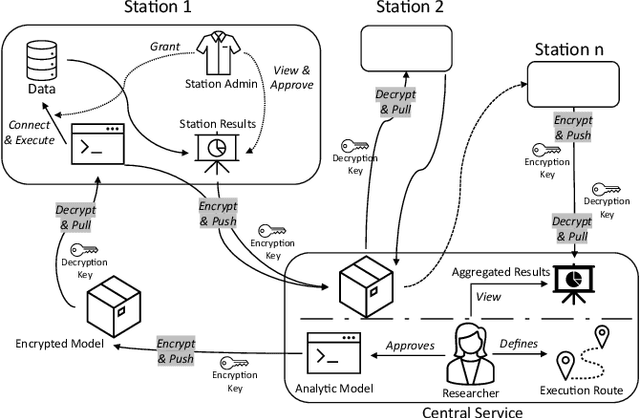
Data privacy and ownership are significant in social data science, raising legal and ethical concerns. Sharing and analyzing data is difficult when different parties own different parts of it. An approach to this challenge is to apply de-identification or anonymization techniques to the data before collecting it for analysis. However, this can reduce data utility and increase the risk of re-identification. To address these limitations, we present PADME, a distributed analytics tool that federates model implementation and training. PADME uses a federated approach where the model is implemented and deployed by all parties and visits each data location incrementally for training. This enables the analysis of data across locations while still allowing the model to be trained as if all data were in a single location. Training the model on data in its original location preserves data ownership. Furthermore, the results are not provided until the analysis is completed on all data locations to ensure privacy and avoid bias in the results.
iLCM - A Virtual Research Infrastructure for Large-Scale Qualitative Data
May 11, 2018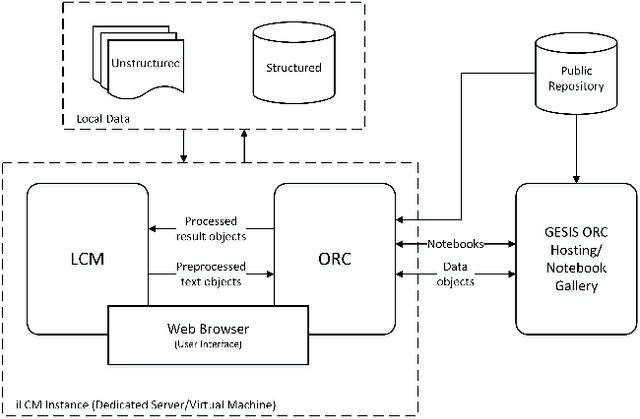
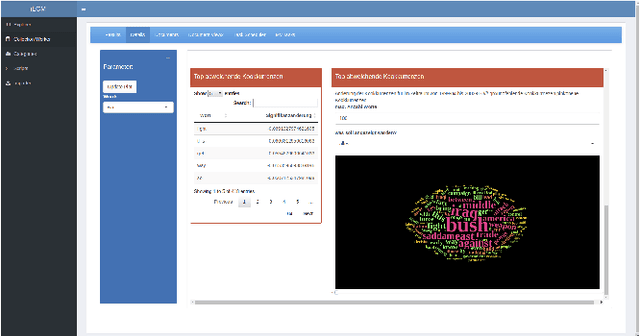
The iLCM project pursues the development of an integrated research environment for the analysis of structured and unstructured data in a "Software as a Service" architecture (SaaS). The research environment addresses requirements for the quantitative evaluation of large amounts of qualitative data with text mining methods as well as requirements for the reproducibility of data-driven research designs in the social sciences. For this, the iLCM research environment comprises two central components. First, the Leipzig Corpus Miner (LCM), a decentralized SaaS application for the analysis of large amounts of news texts developed in a previous Digital Humanities project. Second, the text mining tools implemented in the LCM are extended by an "Open Research Computing" (ORC) environment for executable script documents, so-called "notebooks". This novel integration allows to combine generic, high-performance methods to process large amounts of unstructured text data and with individual program scripts to address specific research requirements in computational social science and digital humanities.
Truncation-free Hybrid Inference for DPMM
Jan 13, 2017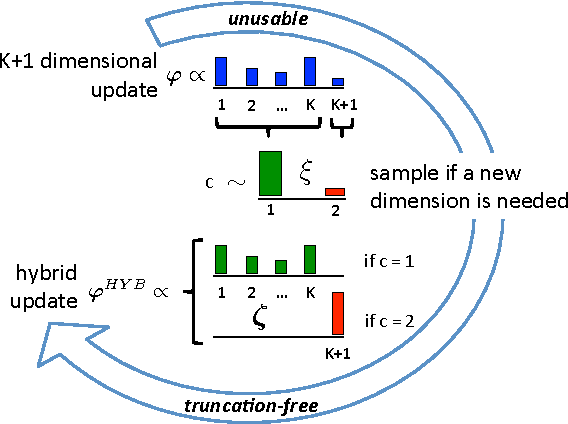
Dirichlet process mixture models (DPMM) are a cornerstone of Bayesian non-parametrics. While these models free from choosing the number of components a-priori, computationally attractive variational inference often reintroduces the need to do so, via a truncation on the variational distribution. In this paper we present a truncation-free hybrid inference for DPMM, combining the advantages of sampling-based MCMC and variational methods. The proposed hybridization enables more efficient variational updates, while increasing model complexity only if needed. We evaluate the properties of the hybrid updates and their empirical performance in single- as well as mixed-membership models. Our method is easy to implement and performs favorably compared to existing schemas.
A System for Probabilistic Linking of Thesauri and Classification Systems
Mar 21, 2016
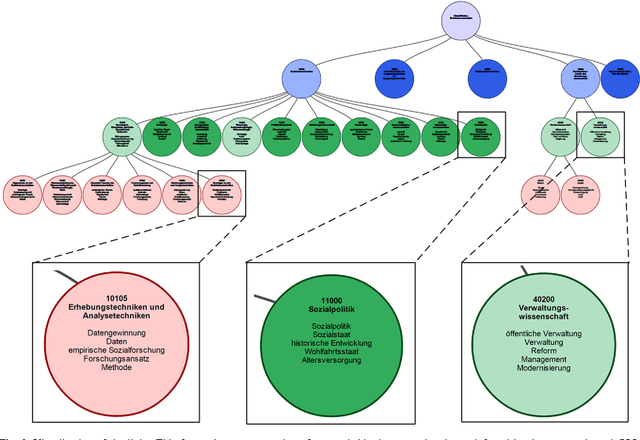
This paper presents a system which creates and visualizes probabilistic semantic links between concepts in a thesaurus and classes in a classification system. For creating the links, we build on the Polylingual Labeled Topic Model (PLL-TM). PLL-TM identifies probable thesaurus descriptors for each class in the classification system by using information from the natural language text of documents, their assigned thesaurus descriptors and their designated classes. The links are then presented to users of the system in an interactive visualization, providing them with an automatically generated overview of the relations between the thesaurus and the classification system.
The Polylingual Labeled Topic Model
Jul 24, 2015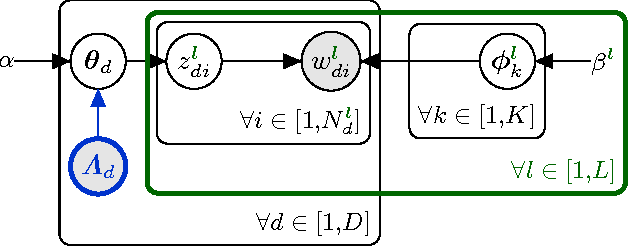
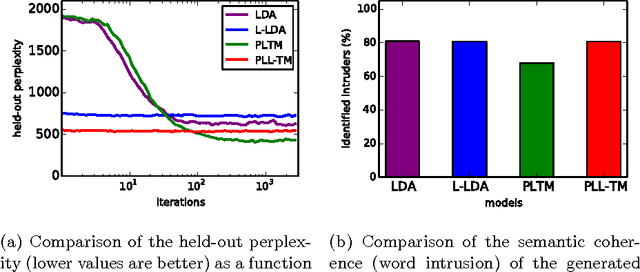
In this paper, we present the Polylingual Labeled Topic Model, a model which combines the characteristics of the existing Polylingual Topic Model and Labeled LDA. The model accounts for multiple languages with separate topic distributions for each language while restricting the permitted topics of a document to a set of predefined labels. We explore the properties of the model in a two-language setting on a dataset from the social science domain. Our experiments show that our model outperforms LDA and Labeled LDA in terms of their held-out perplexity and that it produces semantically coherent topics which are well interpretable by human subjects.
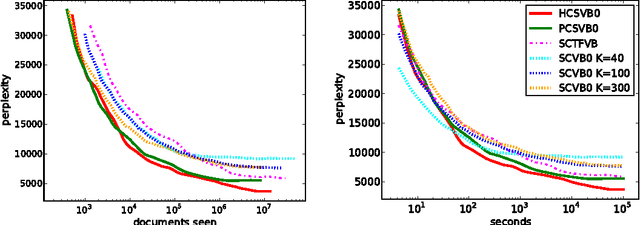
Practical Collapsed Stochastic Variational Inference for the HDP
Dec 02, 2013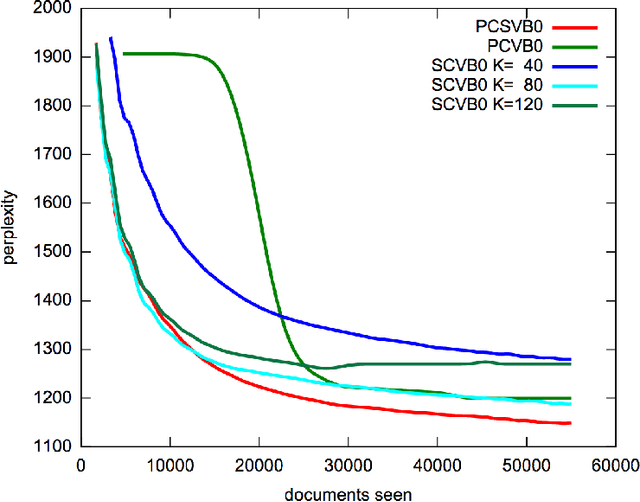
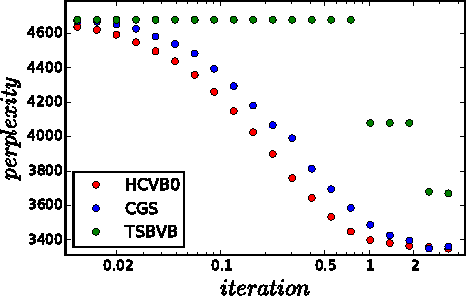
Recent advances have made it feasible to apply the stochastic variational paradigm to a collapsed representation of latent Dirichlet allocation (LDA). While the stochastic variational paradigm has successfully been applied to an uncollapsed representation of the hierarchical Dirichlet process (HDP), no attempts to apply this type of inference in a collapsed setting of non-parametric topic modeling have been put forward so far. In this paper we explore such a collapsed stochastic variational Bayes inference for the HDP. The proposed online algorithm is easy to implement and accounts for the inference of hyper-parameters. First experiments show a promising improvement in predictive performance.
Towards an Author-Topic-Term-Model Visualization of 100 Years of German Sociological Society Proceedings
May 06, 2013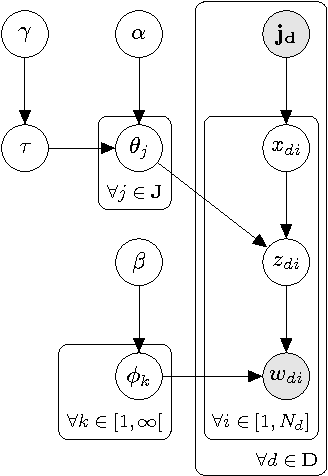

Author co-citation studies employ factor analysis to reduce high-dimensional co-citation matrices to low-dimensional and possibly interpretable factors, but these studies do not use any information from the text bodies of publications. We hypothesise that term frequencies may yield useful information for scientometric analysis. In our work we ask if word features in combination with Bayesian analysis allow well-founded science mapping studies. This work goes back to the roots of Mosteller and Wallace's (1964) statistical text analysis using word frequency features and a Bayesian inference approach, tough with different goals. To answer our research question we (i) introduce a new data set on which the experiments are carried out, (ii) describe the Bayesian model employed for inference and (iii) present first results of the analysis.
A simple non-parametric Topic Mixture for Authors and Documents
Dec 04, 2012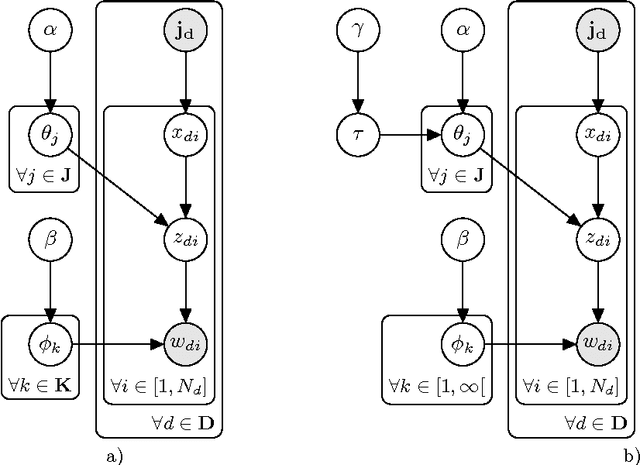
This article reviews the Author-Topic Model and presents a new non-parametric extension based on the Hierarchical Dirichlet Process. The extension is especially suitable when no prior information about the number of components necessary is available. A blocked Gibbs sampler is described and focus put on staying as close as possible to the original model with only the minimum of theoretical and implementation overhead necessary.