 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training for Sample-Efficient Active Learning for Text Classification with Pre-Trained Language Models
Jun 13, 2024Active learning is an iterative labeling process that is used to obtain a small labeled subset, despite the absence of labeled data, thereby enabling to train a model for supervised tasks such as text classification. While active learning has made considerable progress in recent years due to improvements provided by pre-trained language models, there is untapped potential in the often neglected unlabeled portion of the data, although it is available in considerably larger quantities than the usually small set of labeled data. Here we investigate how self-training, a semi-supervised approach where a model is used to obtain pseudo-labels from the unlabeled data, can be used to improve the efficiency of active learning for text classification. Starting with an extensive reproduction of four previous self-training approaches, some of which are evaluated for the first time in the context of active learning or natural language processing, we devise HAST, a new and effective self-training strategy, which is evaluated on four text classification benchmarks, on which it outperforms the reproduced self-training approaches and reaches classification results comparable to previous experiments for three out of four datasets, using only 25% of the data.
Mining Legacy Issues in Open Pit Mining Sites: Innovation & Support of Renaturalization and Land Utilization
May 13, 2021
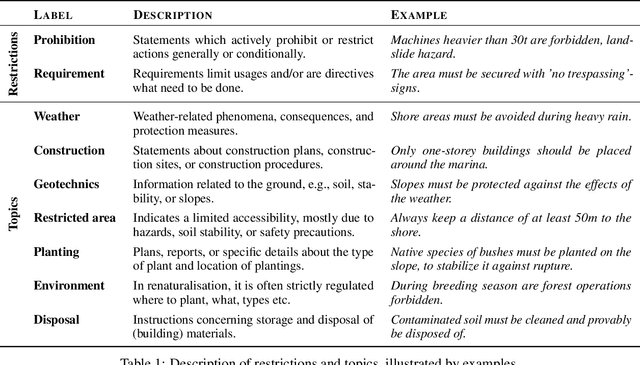
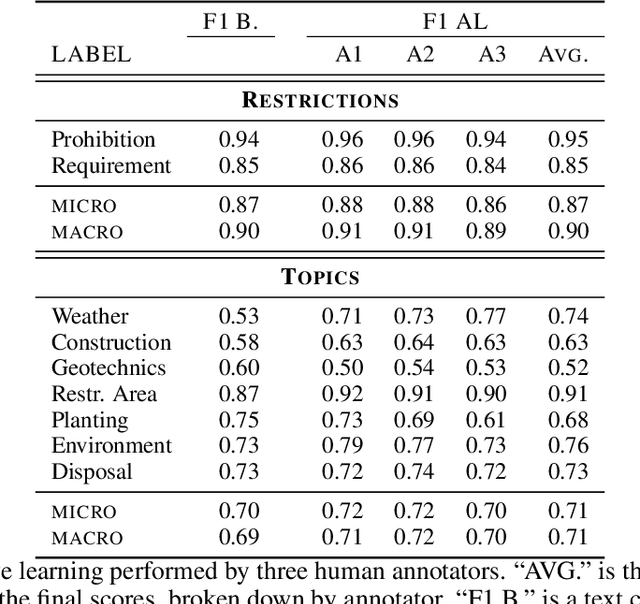
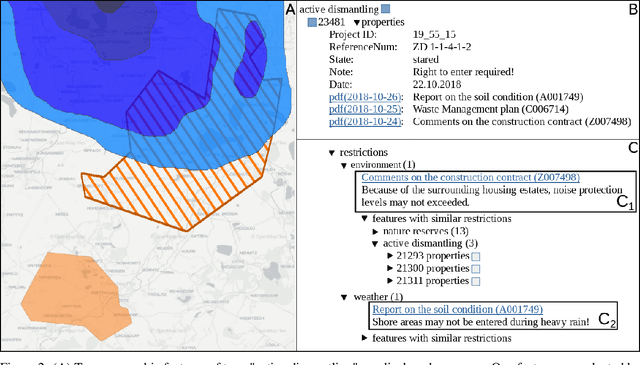
Open pit mines left many regions worldwide inhospitable or uninhabitable. To put these regions back into use, entire stretches of land must be renaturalized. For the sustainable subsequent use or transfer to a new primary use, many contaminated sites and soil information have to be permanently managed. In most cases, this information is available in the form of expert reports in unstructured data collections or file folders, which in the best case are digitized. Due to size and complexity of the data, it is difficult for a single person to have an overview of this data in order to be able to make reliable statements. This is one of the most important obstacles to the rapid transfer of these areas to after-use. An information-based approach to this issue supports fulfilling several Sustainable Development Goals regarding environment issues, health and climate action. We use a stack of Optical Character Recognition, Text Classification, Active Learning and Geographic Information System Visualization to effectively mine and visualize this information. Subsequently, we link the extracted information to geographic coordinates and visualize them using a Geographic Information System. Active Learning plays a vital role because our dataset provides no training data. In total, we process nine categories and actively learn their representation in our dataset. We evaluate the OCR, Active Learning and Text Classification separately to report the performance of the system. Active Learning and text classification results are twofold: Whereas our categories about restrictions work sufficient ($>$.85 F1), the seven topic-oriented categories were complicated for human coders and hence the results achieved mediocre evaluation scores ($<$.70 F1).
iLCM - A Virtual Research Infrastructure for Large-Scale Qualitative Data
May 11, 2018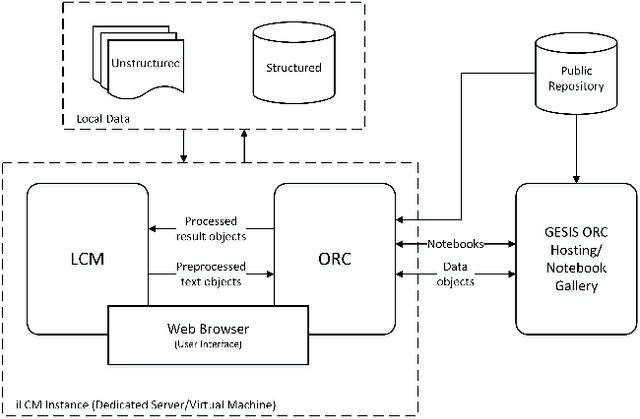
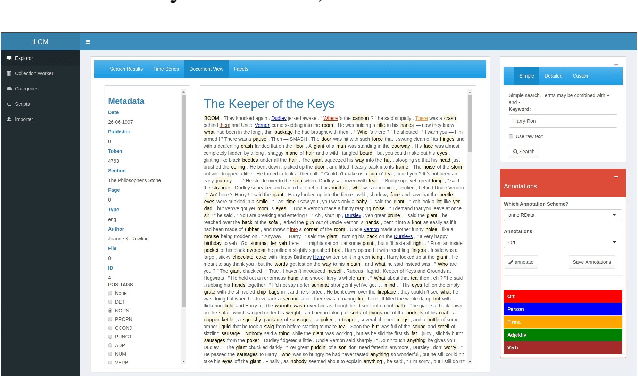
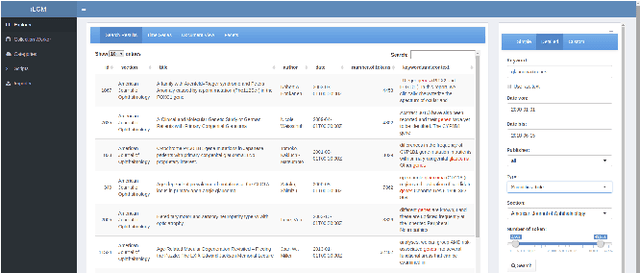
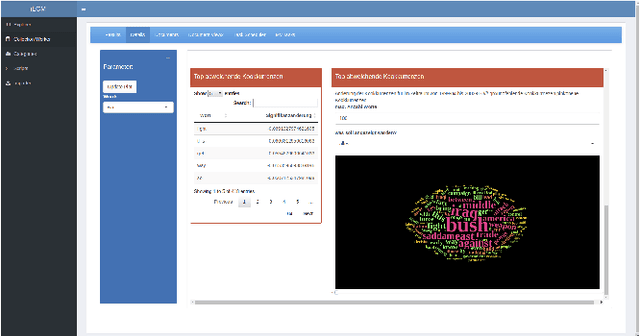
The iLCM project pursues the development of an integrated research environment for the analysis of structured and unstructured data in a "Software as a Service" architecture (SaaS). The research environment addresses requirements for the quantitative evaluation of large amounts of qualitative data with text mining methods as well as requirements for the reproducibility of data-driven research designs in the social sciences. For this, the iLCM research environment comprises two central components. First, the Leipzig Corpus Miner (LCM), a decentralized SaaS application for the analysis of large amounts of news texts developed in a previous Digital Humanities project. Second, the text mining tools implemented in the LCM are extended by an "Open Research Computing" (ORC) environment for executable script documents, so-called "notebooks". This novel integration allows to combine generic, high-performance methods to process large amounts of unstructured text data and with individual program scripts to address specific research requirements in computational social science and digital humanities.
Page Stream Segmentation with Convolutional Neural Nets Combining Textual and Visual Features
Feb 08, 2018


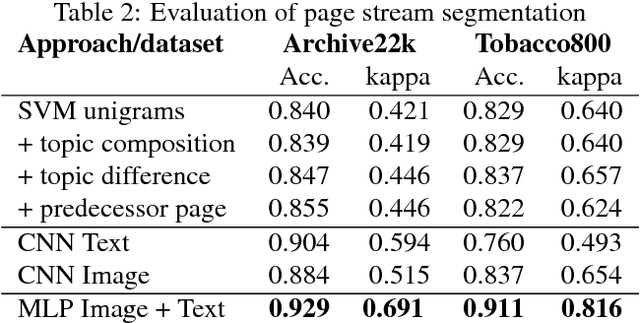
In recent years, (retro-)digitizing paper-based files became a major undertaking for private and public archives as well as an important task in electronic mailroom applications. As a first step, the workflow involves scanning and Optical Character Recognition (OCR) of documents. Preservation of document contexts of single page scans is a major requirement in this context. To facilitate workflows involving very large amounts of paper scans, page stream segmentation (PSS) is the task to automatically separate a stream of scanned images into multi-page documents. In a digitization project together with a German federal archive, we developed a novel approach based on convolutional neural networks (CNN) combining image and text features to achieve optimal document separation results. Evaluation shows that our PSS architecture achieves an accuracy up to 93 % which can be regarded as a new state-of-the-art for this task.
Detecting and assessing contextual change in diachronic text documents using context volatility
Nov 15, 2017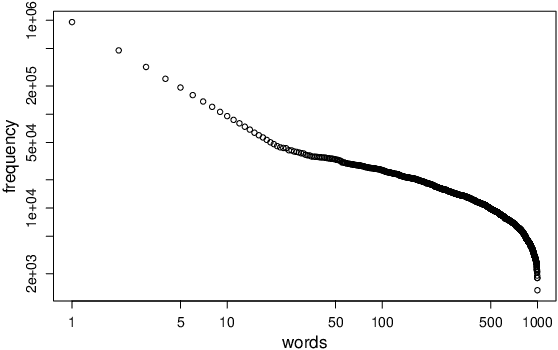
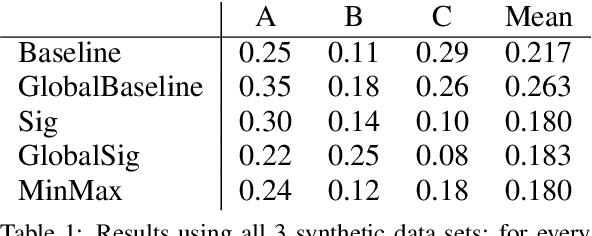
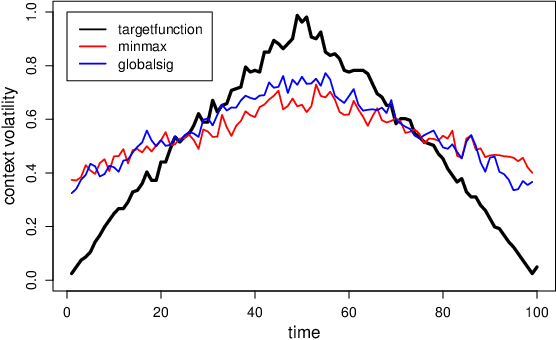
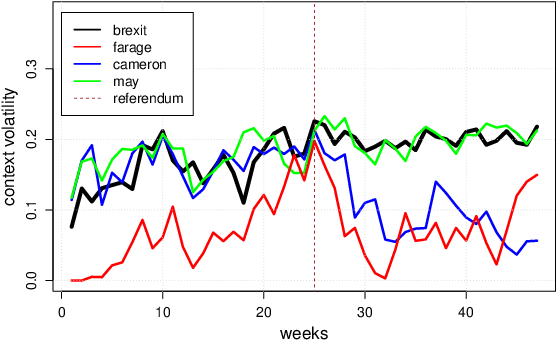
Terms in diachronic text corpora may exhibit a high degree of semantic dynamics that is only partially captured by the common notion of semantic change. The new measure of context volatility that we propose models the degree by which terms change context in a text collection over time. The computation of context volatility for a word relies on the significance-values of its co-occurrent terms and the corresponding co-occurrence ranks in sequential time spans. We define a baseline and present an efficient computational approach in order to overcome problems related to computational issues in the data structure. Results are evaluated both, on synthetic documents that are used to simulate contextual changes, and a real example based on British newspaper texts.
Modeling the dynamics of domain specific terminology in diachronic corpora
Jul 11, 2017
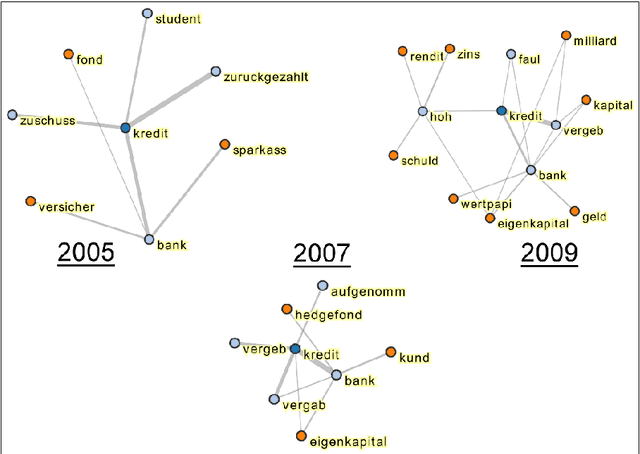
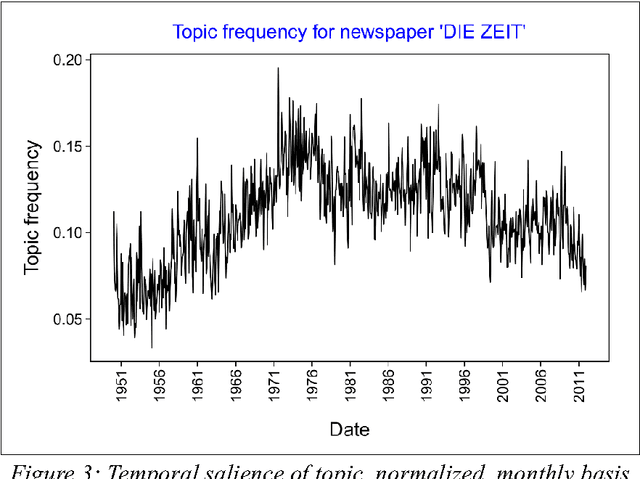
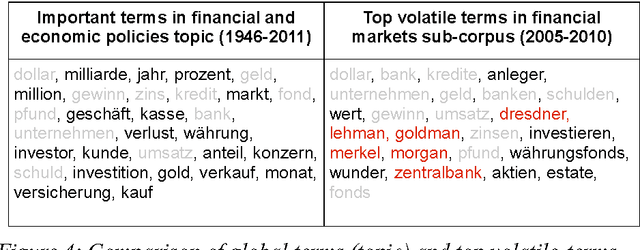
In terminology work, natural language processing, and digital humanities, several studies address the analysis of variations in context and meaning of terms in order to detect semantic change and the evolution of terms. We distinguish three different approaches to describe contextual variations: methods based on the analysis of patterns and linguistic clues, methods exploring the latent semantic space of single words, and methods for the analysis of topic membership. The paper presents the notion of context volatility as a new measure for detecting semantic change and applies it to key term extraction in a political science case study. The measure quantifies the dynamics of a term's contextual variation within a diachronic corpus to identify periods of time that are characterised by intense controversial debates or substantial semantic transformations.
Leipzig Corpus Miner - A Text Mining Infrastructure for Qualitative Data Analysis
Jul 11, 2017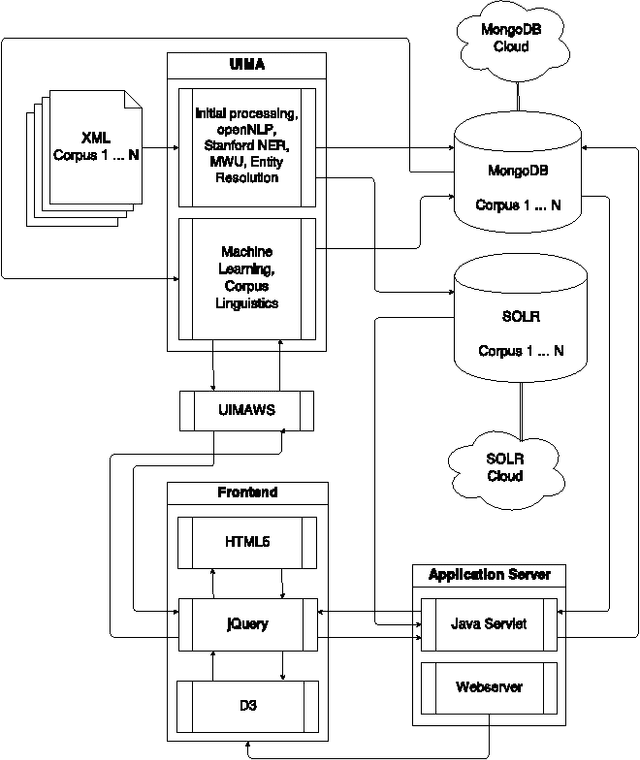
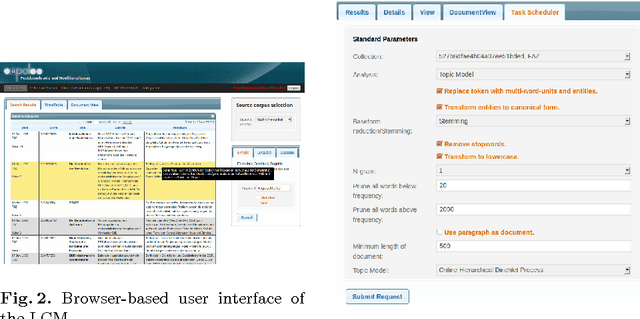
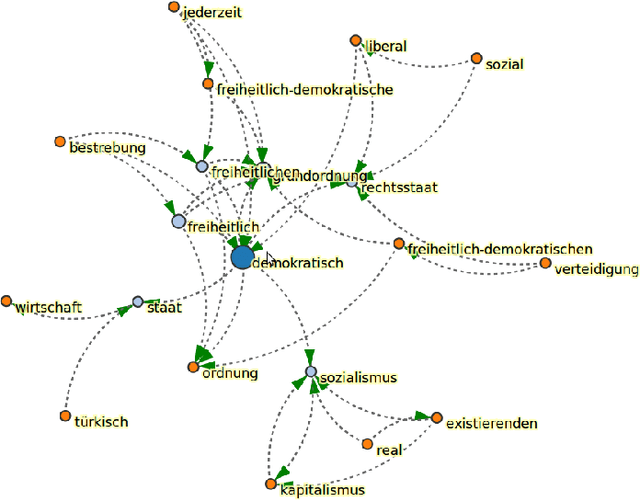
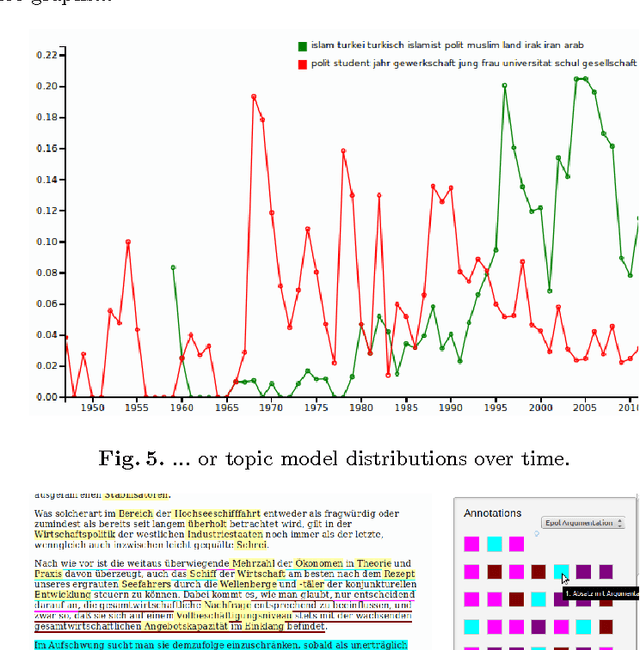
This paper presents the "Leipzig Corpus Miner", a technical infrastructure for supporting qualitative and quantitative content analysis. The infrastructure aims at the integration of 'close reading' procedures on individual documents with procedures of 'distant reading', e.g. lexical characteristics of large document collections. Therefore information retrieval systems, lexicometric statistics and machine learning procedures are combined in a coherent framework which enables qualitative data analysts to make use of state-of-the-art Natural Language Processing techniques on very large document collections. Applicability of the framework ranges from social sciences to media studies and market research. As an example we introduce the usage of the framework in a political science study on post-democracy and neoliberalism.