 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHave LLMs Made Active Learning Obsolete? Surveying the NLP Community
Mar 12, 2025



Supervised learning relies on annotated data, which is expensive to obtain. A longstanding strategy to reduce annotation costs is active learning, an iterative process, in which a human annotates only data instances deemed informative by a model. Large language models (LLMs) have pushed the effectiveness of active learning, but have also improved methods such as few- or zero-shot learning, and text synthesis - thereby introducing potential alternatives. This raises the question: has active learning become obsolete? To answer this fully, we must look beyond literature to practical experiences. We conduct an online survey in the NLP community to collect previously intangible insights on the perceived relevance of data annotation, particularly focusing on active learning, including best practices, obstacles and expected future developments. Our findings show that annotated data remains a key factor, and active learning continues to be relevant. While the majority of active learning users find it effective, a comparison with a community survey from over a decade ago reveals persistent challenges: setup complexity, estimation of cost reduction, and tooling. We publish an anonymized version of the collected dataset
Self-Training for Sample-Efficient Active Learning for Text Classification with Pre-Trained Language Models
Jun 13, 2024Active learning is an iterative labeling process that is used to obtain a small labeled subset, despite the absence of labeled data, thereby enabling to train a model for supervised tasks such as text classification. While active learning has made considerable progress in recent years due to improvements provided by pre-trained language models, there is untapped potential in the often neglected unlabeled portion of the data, although it is available in considerably larger quantities than the usually small set of labeled data. Here we investigate how self-training, a semi-supervised approach where a model is used to obtain pseudo-labels from the unlabeled data, can be used to improve the efficiency of active learning for text classification. Starting with an extensive reproduction of four previous self-training approaches, some of which are evaluated for the first time in the context of active learning or natural language processing, we devise HAST, a new and effective self-training strategy, which is evaluated on four text classification benchmarks, on which it outperforms the reproduced self-training approaches and reaches classification results comparable to previous experiments for three out of four datasets, using only 25% of the data.
The Infinite Index: Information Retrieval on Generative Text-To-Image Models
Dec 14, 2022The text-to-image model Stable Diffusion has recently become very popular. Only weeks after its open source release, millions are experimenting with image generation. This is due to its ease of use, since all it takes is a brief description of the desired image to "prompt" the generative model. Rarely do the images generated for a new prompt immediately meet the user's expectations. Usually, an iterative refinement of the prompt ("prompt engineering") is necessary for satisfying images. As a new perspective, we recast image prompt engineering as interactive image retrieval - on an "infinite index". Thereby, a prompt corresponds to a query and prompt engineering to query refinement. Selected image-prompt pairs allow direct relevance feedback, as the model can modify an image for the refined prompt. This is a form of one-sided interactive retrieval, where the initiative is on the user side, whereas the server side remains stateless. In light of an extensive literature review, we develop these parallels in detail and apply the findings to a case study of a creative search task on such a model. We note that the uncertainty in searching an infinite index is virtually never-ending. We also discuss future research opportunities related to retrieval models specialized for generative models and interactive generative image retrieval. The application of IR technology, such as query reformulation and relevance feedback, will contribute to improved workflows when using generative models, while the notion of an infinite index raises new challenges in IR research.
Trigger Warnings: Bootstrapping a Violence Detector for FanFiction
Sep 09, 2022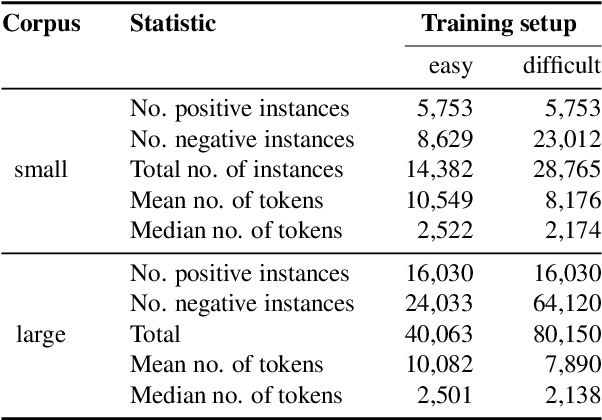

We present the first dataset and evaluation results on a newly defined computational task of trigger warning assignment. Labeled corpus data has been compiled from narrative works hosted on Archive of Our Own (AO3), a well-known fanfiction site. In this paper, we focus on the most frequently assigned trigger type--violence--and define a document-level binary classification task of whether or not to assign a violence trigger warning to a fanfiction, exploiting warning labels provided by AO3 authors. SVM and BERT models trained in four evaluation setups on the corpora we compiled yield $F_1$ results ranging from 0.585 to 0.798, proving the violence trigger warning assignment to be a doable, however, non-trivial task.
The Impact of Main Content Extraction on Near-Duplicate Detection
Nov 21, 2021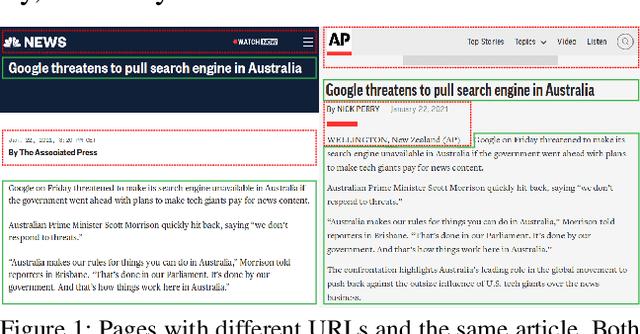

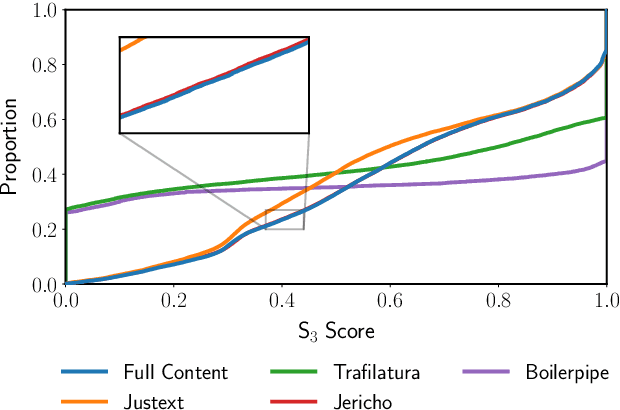
Commercial web search engines employ near-duplicate detection to ensure that users see each relevant result only once, albeit the underlying web crawls typically include (near-)duplicates of many web pages. We revisit the risks and potential of near-duplicates with an information retrieval focus, motivating that current efforts toward an open and independent European web search infrastructure should maintain metadata on duplicate and near-duplicate documents in its index. Near-duplicate detection implemented in an open web search infrastructure should provide a suitable similarity threshold, a difficult choice since identical pages may substantially differ in parts of a page that are irrelevant to searchers (templates, advertisements, etc.). We study this problem by comparing the similarity of pages for five (main) content extraction methods in two studies on the ClueWeb crawls. We find that the full content of pages serves precision-oriented near-duplicate-detection, while main content extraction is more recall-oriented.
Small-text: Active Learning for Text Classification in Python
Jul 21, 2021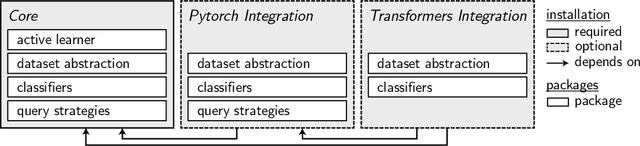

We present small-text, a simple modular active learning library, which offers pool-based active learning for text classification in Python. It comes with various pre-implemented state-of-the-art query strategies, including some which can leverage the GPU. Clearly defined interfaces allow to combine a multitude of such query strategies with different classifiers, thereby facilitating a quick mix and match, and enabling a rapid development of both active learning experiments and applications. To make various classifiers accessible in a consistent way, it integrates several well-known machine learning libraries, namely, scikit-learn, PyTorch, and huggingface transformers -- for which the latter integrations are available as optionally installable extensions. The library is available under the MIT License at https://github.com/webis-de/small-text.
Uncertainty-based Query Strategies for Active Learning with Transformers
Jul 12, 2021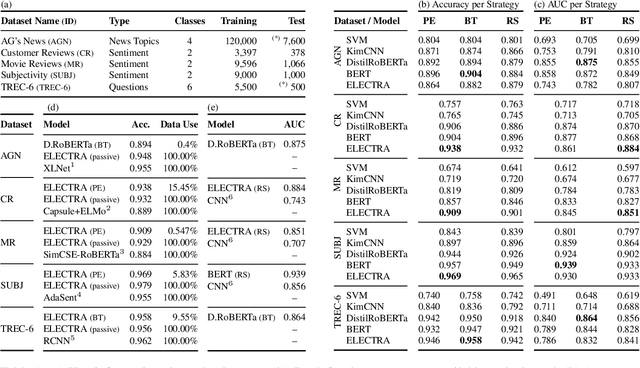


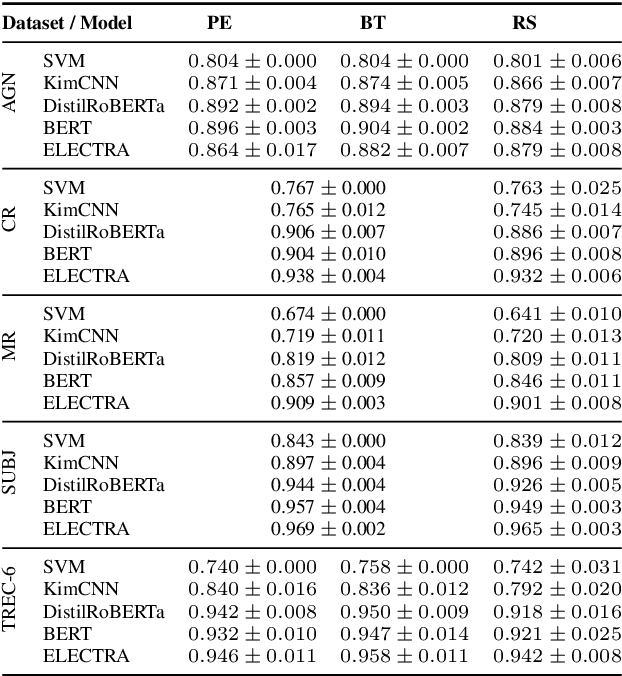
Active learning is the iterative construction of a classification model through targeted labeling, enabling significant labeling cost savings. As most research on active learning has been carried out before transformer-based language models ("transformers") became popular, despite its practical importance, comparably few papers have investigated how transformers can be combined with active learning to date. This can be attributed to the fact that using state-of-the-art query strategies for transformers induces a prohibitive runtime overhead, which effectively cancels out, or even outweighs aforementioned cost savings. In this paper, we revisit uncertainty-based query strategies, which had been largely outperformed before, but are particularly suited in the context of fine-tuning transformers. In an extensive evaluation on five widely used text classification benchmarks, we show that considerable improvements of up to 14.4 percentage points in area under the learning curve are achieved, as well as a final accuracy close to the state of the art for all but one benchmark, using only between 0.4% and 15% of the training data.
Mining Legacy Issues in Open Pit Mining Sites: Innovation & Support of Renaturalization and Land Utilization
May 13, 2021
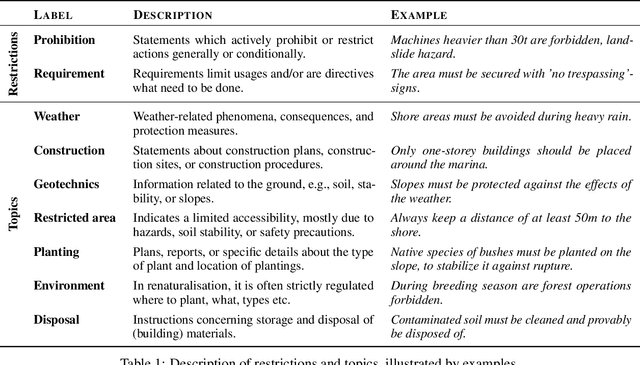
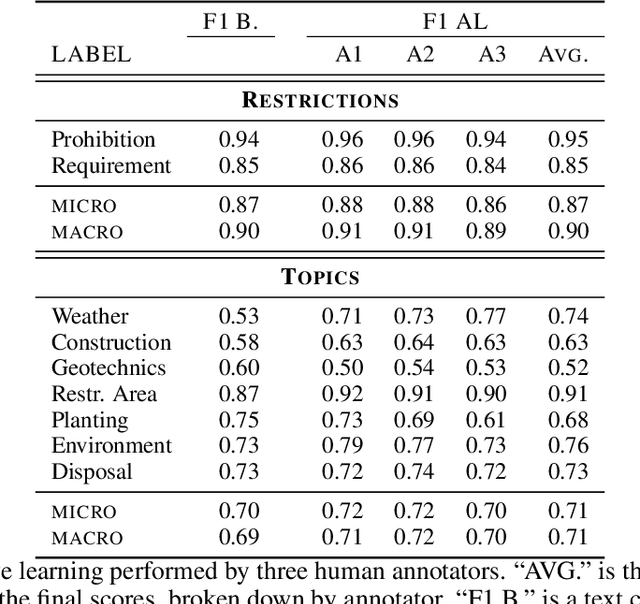
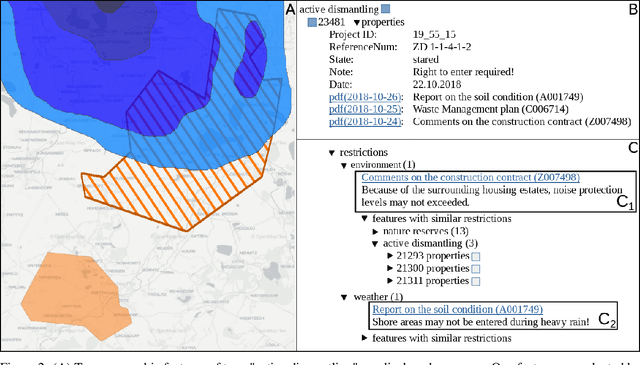
Open pit mines left many regions worldwide inhospitable or uninhabitable. To put these regions back into use, entire stretches of land must be renaturalized. For the sustainable subsequent use or transfer to a new primary use, many contaminated sites and soil information have to be permanently managed. In most cases, this information is available in the form of expert reports in unstructured data collections or file folders, which in the best case are digitized. Due to size and complexity of the data, it is difficult for a single person to have an overview of this data in order to be able to make reliable statements. This is one of the most important obstacles to the rapid transfer of these areas to after-use. An information-based approach to this issue supports fulfilling several Sustainable Development Goals regarding environment issues, health and climate action. We use a stack of Optical Character Recognition, Text Classification, Active Learning and Geographic Information System Visualization to effectively mine and visualize this information. Subsequently, we link the extracted information to geographic coordinates and visualize them using a Geographic Information System. Active Learning plays a vital role because our dataset provides no training data. In total, we process nine categories and actively learn their representation in our dataset. We evaluate the OCR, Active Learning and Text Classification separately to report the performance of the system. Active Learning and text classification results are twofold: Whereas our categories about restrictions work sufficient ($>$.85 F1), the seven topic-oriented categories were complicated for human coders and hence the results achieved mediocre evaluation scores ($<$.70 F1).
A Survey of Active Learning for Text Classification using Deep Neural Networks
Aug 17, 2020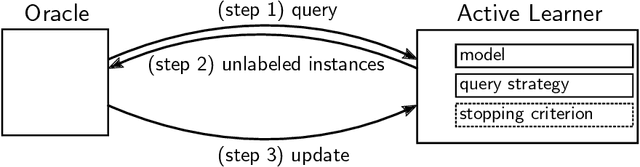
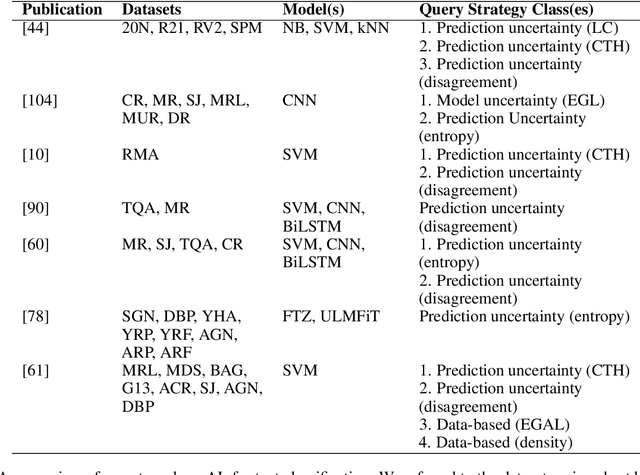
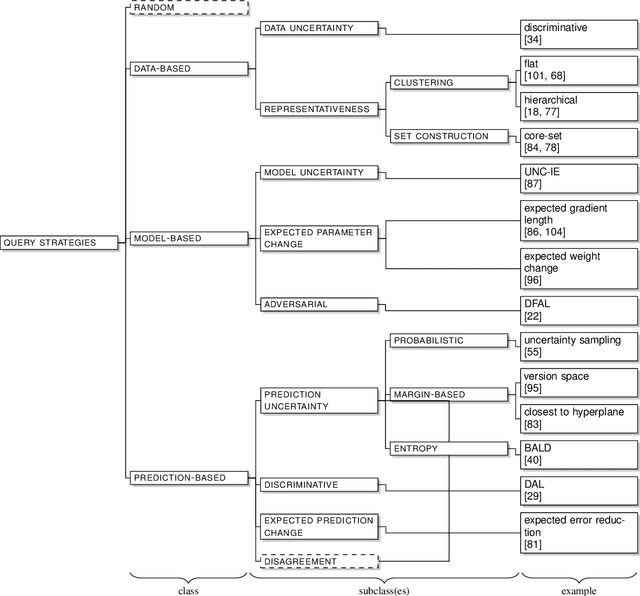
Natural language processing (NLP) and neural networks (NNs) have both undergone significant changes in recent years. For active learning (AL) purposes, NNs are, however, less commonly used -- despite their current popularity. By using the superior text classification performance of NNs for AL, we can either increase a model's performance using the same amount of data or reduce the data and therefore the required annotation efforts while keeping the same performance. We review AL for text classification using deep neural networks (DNNs) and elaborate on two main causes which used to hinder the adoption: (a) the inability of NNs to provide reliable uncertainty estimates, on which the most commonly used query strategies rely, and (b) the challenge of training DNNs on small data. To investigate the former, we construct a taxonomy of query strategies, which distinguishes between data-based, model-based, and prediction-based instance selection, and investigate the prevalence of these classes in recent research. Moreover, we review recent NN-based advances in NLP like word embeddings or language models in the context of (D)NNs, survey the current state-of-the-art at the intersection of AL, text classification, and DNNs and relate recent advances in NLP to AL. Finally, we analyze recent work in AL for text classification, connect the respective query strategies to the taxonomy, and outline commonalities and shortcomings. As a result, we highlight gaps in current research and present open research questions.