 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting RAG Advertisements Across Advertising Styles
Mar 05, 2026Large language models (LLMs) enable a new form of advertising for retrieval-augmented generation (RAG) systems in which organic responses are blended with contextually relevant ads. The prospect of such "generated native ads" has sparked interest in whether they can be detected automatically. Existing datasets, however, do not reflect the diversity of advertising styles discussed in the marketing literature. In this paper, we (1) develop a taxonomy of advertising styles for LLMs, combining the style dimensions of explicitness and type of appeal, (2) simulate that advertisers may attempt to evade detection by changing their advertising style, and (3) evaluate a variety of ad-detection approaches with respect to their robustness under these changes. Expanding previous work on ad detection, we train models that use entity recognition to exactly locate an ad in an LLM response and find them to be both very effective at detecting responses with ads and largely robust to changes in the advertising style. Since ad blocking will be performed on low-resource end-user devices, we include lightweight models like random forests and SVMs in our evaluation. These models, however, are brittle under such changes, highlighting the need for further efficiency-oriented research for a practical approach to blocking of generated ads.
Overview of PAN 2026: Voight-Kampff Generative AI Detection, Text Watermarking, Multi-Author Writing Style Analysis, Generative Plagiarism Detection, and Reasoning Trajectory Detection
Feb 09, 2026The goal of the PAN workshop is to advance computational stylometry and text forensics via objective and reproducible evaluation. In 2026, we run the following five tasks: (1) Voight-Kampff Generative AI Detection, particularly in mixed and obfuscated authorship scenarios, (2) Text Watermarking, a new task that aims to find new and benchmark the robustness of existing text watermarking schemes, (3) Multi-author Writing Style Analysis, a continued task that aims to find positions of authorship change, (4) Generative Plagiarism Detection, a continued task that targets source retrieval and text alignment between generated text and source documents, and (5) Reasoning Trajectory Detection, a new task that deals with source detection and safety detection of LLM-generated or human-written reasoning trajectories. As in previous years, PAN invites software submissions as easy-to-reproduce Docker containers for most of the tasks. Since PAN 2012, more than 1,100 submissions have been made this way via the TIRA experimentation platform.
Detecting Generated Native Ads in Conversational Search
Feb 07, 2024
Conversational search engines such as YouChat and Microsoft Copilot use large language models (LLMs) to generate answers to queries. It is only a small step to also use this technology to generate and integrate advertising within these answers - instead of placing ads separately from the organic search results. This type of advertising is reminiscent of native advertising and product placement, both of which are very effective forms of subtle and manipulative advertising. It is likely that information seekers will be confronted with such use of LLM technology in the near future, especially when considering the high computational costs associated with LLMs, for which providers need to develop sustainable business models. This paper investigates whether LLMs can also be used as a countermeasure against generated native ads, i.e., to block them. For this purpose we compile a large dataset of ad-prone queries and of generated answers with automatically integrated ads to experiment with fine-tuned sentence transformers and state-of-the-art LLMs on the task of recognizing the ads. In our experiments sentence transformers achieve detection precision and recall values above 0.9, while the investigated LLMs struggle with the task.
Evaluating Generative Ad Hoc Information Retrieval
Nov 08, 2023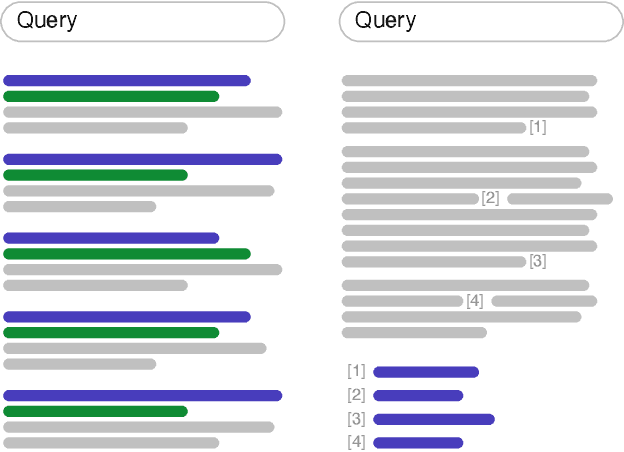

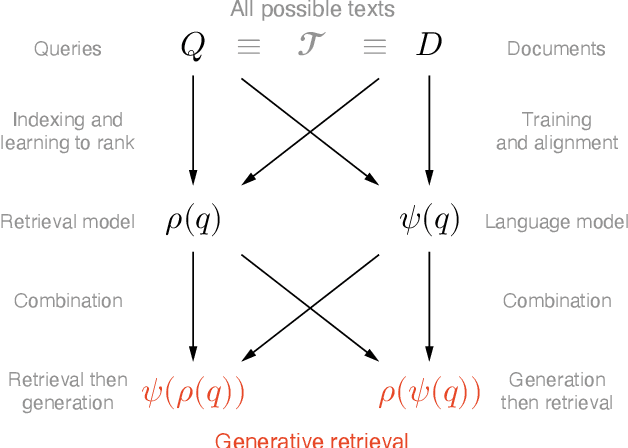
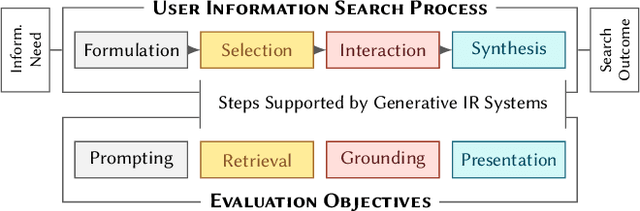
Recent advances in large language models have enabled the development of viable generative information retrieval systems. A generative retrieval system returns a grounded generated text in response to an information need instead of the traditional document ranking. Quantifying the utility of these types of responses is essential for evaluating generative retrieval systems. As the established evaluation methodology for ranking-based ad hoc retrieval may seem unsuitable for generative retrieval, new approaches for reliable, repeatable, and reproducible experimentation are required. In this paper, we survey the relevant information retrieval and natural language processing literature, identify search tasks and system architectures in generative retrieval, develop a corresponding user model, and study its operationalization. This theoretical analysis provides a foundation and new insights for the evaluation of generative ad hoc retrieval systems.
The Information Retrieval Experiment Platform
May 30, 2023We integrate ir_datasets, ir_measures, and PyTerrier with TIRA in the Information Retrieval Experiment Platform (TIREx) to promote more standardized, reproducible, scalable, and even blinded retrieval experiments. Standardization is achieved when a retrieval approach implements PyTerrier's interfaces and the input and output of an experiment are compatible with ir_datasets and ir_measures. However, none of this is a must for reproducibility and scalability, as TIRA can run any dockerized software locally or remotely in a cloud-native execution environment. Version control and caching ensure efficient (re)execution. TIRA allows for blind evaluation when an experiment runs on a remote server or cloud not under the control of the experimenter. The test data and ground truth are then hidden from public access, and the retrieval software has to process them in a sandbox that prevents data leaks. We currently host an instance of TIREx with 15 corpora (1.9 billion documents) on which 32 shared retrieval tasks are based. Using Docker images of 50 standard retrieval approaches, we automatically evaluated all approaches on all tasks (50 $\cdot$ 32 = 1,600~runs) in less than a week on a midsize cluster (1,620 CPU cores and 24 GPUs). This instance of TIREx is open for submissions and will be integrated with the IR Anthology, as well as released open source.
SMAuC -- The Scientific Multi-Authorship Corpus
Nov 04, 2022



With an ever-growing number of new publications each day, scientific writing poses an interesting domain for authorship analysis of both single-author and multi-author documents. Unfortunately, most existing corpora lack either material from the science domain or the required metadata. Hence, we present SMAuC, a new metadata-rich corpus designed specifically for authorship analysis in scientific writing. With more than three million publications from various scientific disciplines, SMAuC is the largest openly available corpus for authorship analysis to date. It combines a wide and diverse range of scientific texts from the humanities and natural sciences with rich and curated metadata, including unique and carefully disambiguated author IDs. We hope SMAuC will contribute significantly to advancing the field of authorship analysis in the science domain.
FastWARC: Optimizing Large-Scale Web Archive Analytics
Nov 22, 2021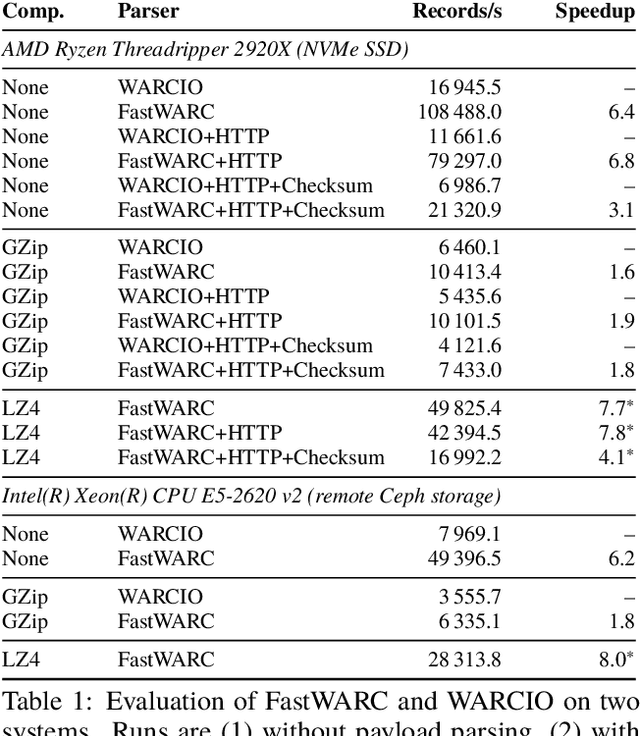
Web search and other large-scale web data analytics rely on processing archives of web pages stored in a standardized and efficient format. Since its introduction in 2008, the IIPC's Web ARCive (WARC) format has become the standard format for this purpose. As a list of individually compressed records of HTTP requests and responses, it allows for constant-time random access to all kinds of web data via off-the-shelf open source parsers in many programming languages, such as WARCIO, the de-facto standard for Python. When processing web archives at the terabyte or petabyte scale, however, even small inefficiencies in these tools add up quickly, resulting in hours, days, or even weeks of wasted compute time. Reviewing the basic components of WARCIO and analyzing its bottlenecks, we proceed to build FastWARC, a new high-performance WARC processing library for Python, written in C++/Cython, which yields performance improvements by factors of 1.6-8x.
The Impact of Main Content Extraction on Near-Duplicate Detection
Nov 21, 2021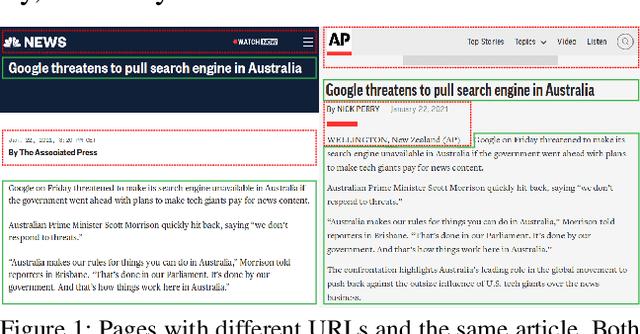

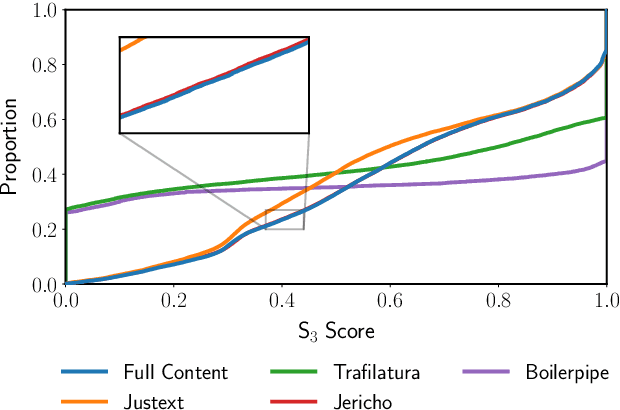
Commercial web search engines employ near-duplicate detection to ensure that users see each relevant result only once, albeit the underlying web crawls typically include (near-)duplicates of many web pages. We revisit the risks and potential of near-duplicates with an information retrieval focus, motivating that current efforts toward an open and independent European web search infrastructure should maintain metadata on duplicate and near-duplicate documents in its index. Near-duplicate detection implemented in an open web search infrastructure should provide a suitable similarity threshold, a difficult choice since identical pages may substantially differ in parts of a page that are irrelevant to searchers (templates, advertisements, etc.). We study this problem by comparing the similarity of pages for five (main) content extraction methods in two studies on the ClueWeb crawls. We find that the full content of pages serves precision-oriented near-duplicate-detection, while main content extraction is more recall-oriented.
A Stylometric Inquiry into Hyperpartisan and Fake News
Feb 18, 2017
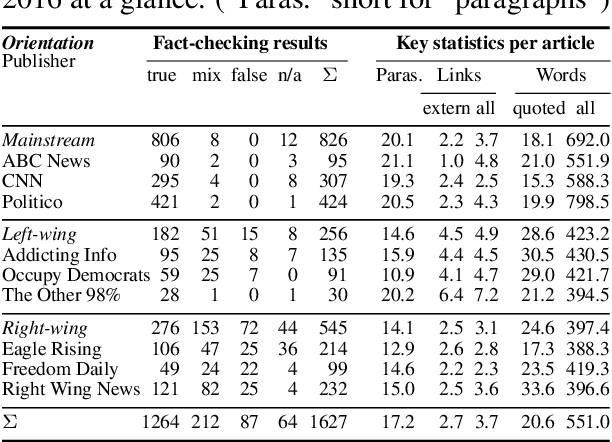
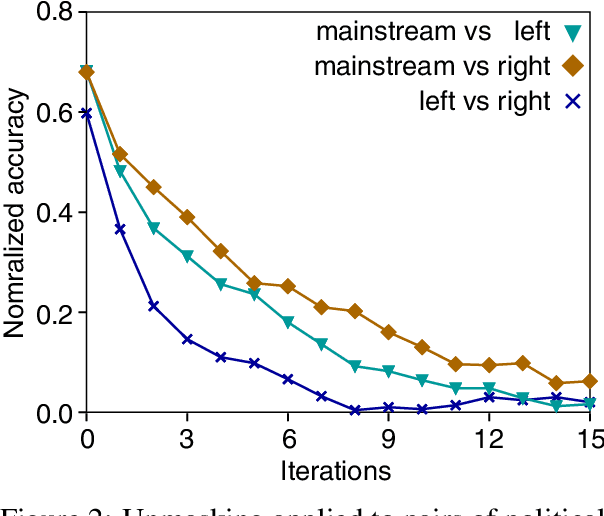
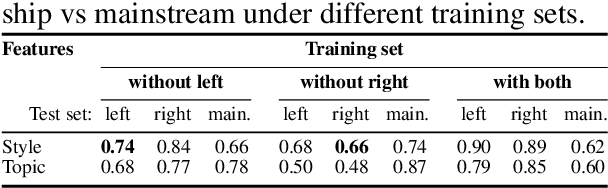
This paper reports on a writing style analysis of hyperpartisan (i.e., extremely one-sided) news in connection to fake news. It presents a large corpus of 1,627 articles that were manually fact-checked by professional journalists from BuzzFeed. The articles originated from 9 well-known political publishers, 3 each from the mainstream, the hyperpartisan left-wing, and the hyperpartisan right-wing. In sum, the corpus contains 299 fake news, 97% of which originated from hyperpartisan publishers. We propose and demonstrate a new way of assessing style similarity between text categories via Unmasking---a meta-learning approach originally devised for authorship verification---, revealing that the style of left-wing and right-wing news have a lot more in common than any of the two have with the mainstream. Furthermore, we show that hyperpartisan news can be discriminated well by its style from the mainstream (F1=0.78), as can be satire from both (F1=0.81). Unsurprisingly, style-based fake news detection does not live up to scratch (F1=0.46). Nevertheless, the former results are important to implement pre-screening for fake news detectors.