 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMAuC -- The Scientific Multi-Authorship Corpus
Nov 04, 2022



With an ever-growing number of new publications each day, scientific writing poses an interesting domain for authorship analysis of both single-author and multi-author documents. Unfortunately, most existing corpora lack either material from the science domain or the required metadata. Hence, we present SMAuC, a new metadata-rich corpus designed specifically for authorship analysis in scientific writing. With more than three million publications from various scientific disciplines, SMAuC is the largest openly available corpus for authorship analysis to date. It combines a wide and diverse range of scientific texts from the humanities and natural sciences with rich and curated metadata, including unique and carefully disambiguated author IDs. We hope SMAuC will contribute significantly to advancing the field of authorship analysis in the science domain.
STEREO: Scientific Text Reuse in Open Access Publications
Dec 22, 2021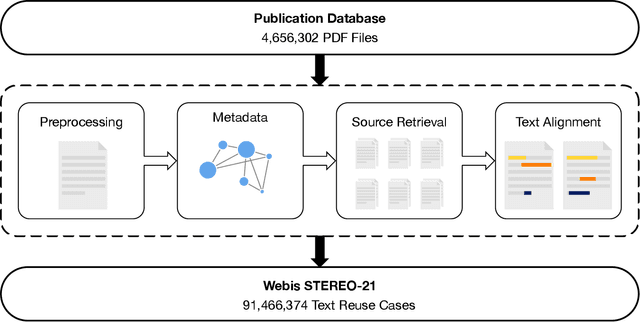
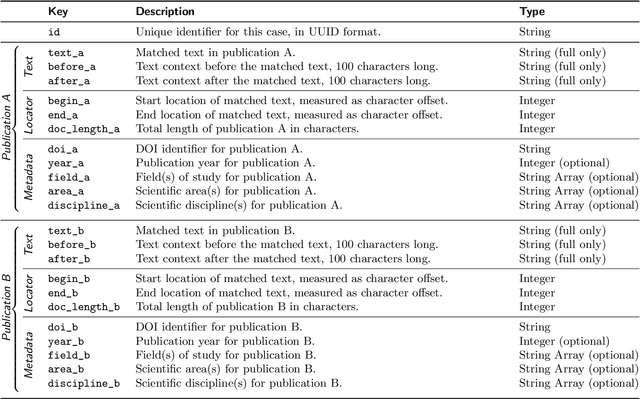
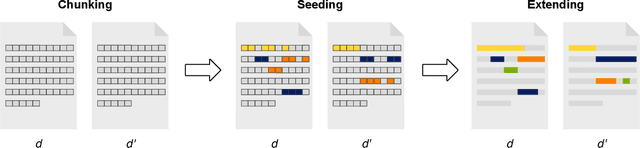

We present the Webis-STEREO-21 dataset, a massive collection of Scientific Text Reuse in Open-access publications. It contains more than 91 million cases of reused text passages found in 4.2 million unique open-access publications. Featuring a high coverage of scientific disciplines and varieties of reuse, as well as comprehensive metadata to contextualize each case, our dataset addresses the most salient shortcomings of previous ones on scientific writing. Webis-STEREO-21 allows for tackling a wide range of research questions from different scientific backgrounds, facilitating both qualitative and quantitative analysis of the phenomenon as well as a first-time grounding on the base rate of text reuse in scientific publications.