 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting RAG Advertisements Across Advertising Styles
Mar 05, 2026Large language models (LLMs) enable a new form of advertising for retrieval-augmented generation (RAG) systems in which organic responses are blended with contextually relevant ads. The prospect of such "generated native ads" has sparked interest in whether they can be detected automatically. Existing datasets, however, do not reflect the diversity of advertising styles discussed in the marketing literature. In this paper, we (1) develop a taxonomy of advertising styles for LLMs, combining the style dimensions of explicitness and type of appeal, (2) simulate that advertisers may attempt to evade detection by changing their advertising style, and (3) evaluate a variety of ad-detection approaches with respect to their robustness under these changes. Expanding previous work on ad detection, we train models that use entity recognition to exactly locate an ad in an LLM response and find them to be both very effective at detecting responses with ads and largely robust to changes in the advertising style. Since ad blocking will be performed on low-resource end-user devices, we include lightweight models like random forests and SVMs in our evaluation. These models, however, are brittle under such changes, highlighting the need for further efficiency-oriented research for a practical approach to blocking of generated ads.
Overview of PAN 2026: Voight-Kampff Generative AI Detection, Text Watermarking, Multi-Author Writing Style Analysis, Generative Plagiarism Detection, and Reasoning Trajectory Detection
Feb 09, 2026The goal of the PAN workshop is to advance computational stylometry and text forensics via objective and reproducible evaluation. In 2026, we run the following five tasks: (1) Voight-Kampff Generative AI Detection, particularly in mixed and obfuscated authorship scenarios, (2) Text Watermarking, a new task that aims to find new and benchmark the robustness of existing text watermarking schemes, (3) Multi-author Writing Style Analysis, a continued task that aims to find positions of authorship change, (4) Generative Plagiarism Detection, a continued task that targets source retrieval and text alignment between generated text and source documents, and (5) Reasoning Trajectory Detection, a new task that deals with source detection and safety detection of LLM-generated or human-written reasoning trajectories. As in previous years, PAN invites software submissions as easy-to-reproduce Docker containers for most of the tasks. Since PAN 2012, more than 1,100 submissions have been made this way via the TIRA experimentation platform.
The Viability of Crowdsourcing for RAG Evaluation
Apr 22, 2025



How good are humans at writing and judging responses in retrieval-augmented generation (RAG) scenarios? To answer this question, we investigate the efficacy of crowdsourcing for RAG through two complementary studies: response writing and response utility judgment. We present the Crowd RAG Corpus 2025 (CrowdRAG-25), which consists of 903 human-written and 903 LLM-generated responses for the 301 topics of the TREC RAG'24 track, across the three discourse styles 'bulleted list', 'essay', and 'news'. For a selection of 65 topics, the corpus further contains 47,320 pairwise human judgments and 10,556 pairwise LLM judgments across seven utility dimensions (e.g., coverage and coherence). Our analyses give insights into human writing behavior for RAG and the viability of crowdsourcing for RAG evaluation. Human pairwise judgments provide reliable and cost-effective results compared to LLM-based pairwise or human/LLM-based pointwise judgments, as well as automated comparisons with human-written reference responses. All our data and tools are freely available.
A Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking
May 13, 2024
Cross-encoders distilled from large language models are more effective re-rankers than cross-encoders fine-tuned using manually labeled data. However, the distilled models do not reach the language model's effectiveness. We construct and release a new distillation dataset, named Rank-DistiLLM, to investigate whether insights from fine-tuning cross-encoders on manually labeled data -- hard-negative sampling, deep sampling, and listwise loss functions -- are transferable to large language model ranker distillation. Our dataset can be used to train cross-encoders that reach the effectiveness of large language models while being orders of magnitude more efficient. Code and data is available at: https://github.com/webis-de/msmarco-llm-distillation
If there's a Trigger Warning, then where's the Trigger? Investigating Trigger Warnings at the Passage Level
Apr 15, 2024



Trigger warnings are labels that preface documents with sensitive content if this content could be perceived as harmful by certain groups of readers. Since warnings about a document intuitively need to be shown before reading it, authors usually assign trigger warnings at the document level. What parts of their writing prompted them to assign a warning, however, remains unclear. We investigate for the first time the feasibility of identifying the triggering passages of a document, both manually and computationally. We create a dataset of 4,135 English passages, each annotated with one of eight common trigger warnings. In a large-scale evaluation, we then systematically evaluate the effectiveness of fine-tuned and few-shot classifiers, and their generalizability. We find that trigger annotation belongs to the group of subjective annotation tasks in NLP, and that automatic trigger classification remains challenging but feasible.
Are Large Language Models Reliable Argument Quality Annotators?
Apr 15, 2024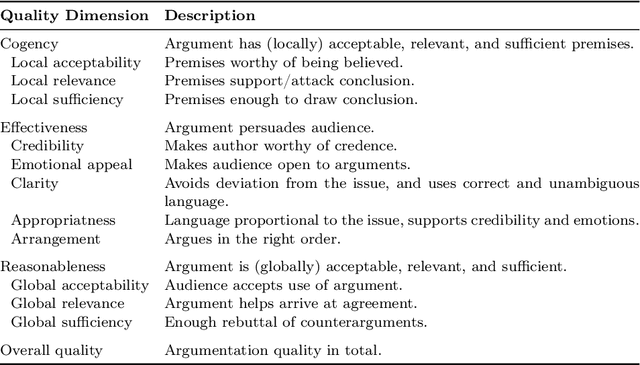

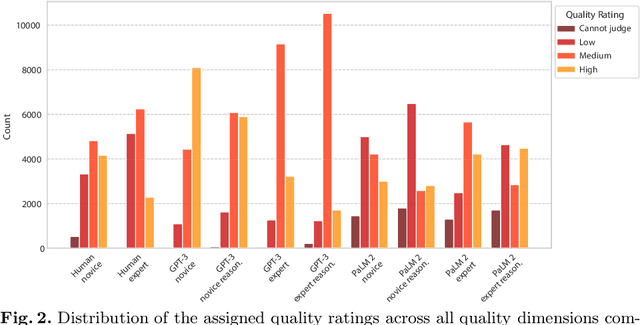
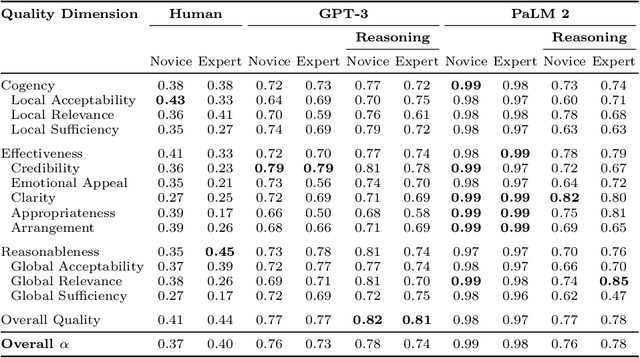
Evaluating the quality of arguments is a crucial aspect of any system leveraging argument mining. However, it is a challenge to obtain reliable and consistent annotations regarding argument quality, as this usually requires domain-specific expertise of the annotators. Even among experts, the assessment of argument quality is often inconsistent due to the inherent subjectivity of this task. In this paper, we study the potential of using state-of-the-art large language models (LLMs) as proxies for argument quality annotators. To assess the capability of LLMs in this regard, we analyze the agreement between model, human expert, and human novice annotators based on an established taxonomy of argument quality dimensions. Our findings highlight that LLMs can produce consistent annotations, with a moderately high agreement with human experts across most of the quality dimensions. Moreover, we show that using LLMs as additional annotators can significantly improve the agreement between annotators. These results suggest that LLMs can serve as a valuable tool for automated argument quality assessment, thus streamlining and accelerating the evaluation of large argument datasets.
Set-Encoder: Permutation-Invariant Inter-Passage Attention for Listwise Passage Re-Ranking with Cross-Encoders
Apr 11, 2024Cross-encoders are effective passage re-rankers. But when re-ranking multiple passages at once, existing cross-encoders inefficiently optimize the output ranking over several input permutations, as their passage interactions are not permutation-invariant. Moreover, their high memory footprint constrains the number of passages during listwise training. To tackle these issues, we propose the Set-Encoder, a new cross-encoder architecture that (1) introduces inter-passage attention with parallel passage processing to ensure permutation invariance between input passages, and that (2) uses fused-attention kernels to enable training with more passages at a time. In experiments on TREC Deep Learning and TIREx, the Set-Encoder is more effective than previous cross-encoders with a similar number of parameters. Compared to larger models, the Set-Encoder is more efficient and either on par or even more effective.
Task-Oriented Paraphrase Analytics
Mar 26, 2024



Since paraphrasing is an ill-defined task, the term "paraphrasing" covers text transformation tasks with different characteristics. Consequently, existing paraphrasing studies have applied quite different (explicit and implicit) criteria as to when a pair of texts is to be considered a paraphrase, all of which amount to postulating a certain level of semantic or lexical similarity. In this paper, we conduct a literature review and propose a taxonomy to organize the 25~identified paraphrasing (sub-)tasks. Using classifiers trained to identify the tasks that a given paraphrasing instance fits, we find that the distributions of task-specific instances in the known paraphrase corpora vary substantially. This means that the use of these corpora, without the respective paraphrase conditions being clearly defined (which is the normal case), must lead to incomparable and misleading results.
Detecting Generated Native Ads in Conversational Search
Feb 07, 2024
Conversational search engines such as YouChat and Microsoft Copilot use large language models (LLMs) to generate answers to queries. It is only a small step to also use this technology to generate and integrate advertising within these answers - instead of placing ads separately from the organic search results. This type of advertising is reminiscent of native advertising and product placement, both of which are very effective forms of subtle and manipulative advertising. It is likely that information seekers will be confronted with such use of LLM technology in the near future, especially when considering the high computational costs associated with LLMs, for which providers need to develop sustainable business models. This paper investigates whether LLMs can also be used as a countermeasure against generated native ads, i.e., to block them. For this purpose we compile a large dataset of ad-prone queries and of generated answers with automatically integrated ads to experiment with fine-tuned sentence transformers and state-of-the-art LLMs on the task of recognizing the ads. In our experiments sentence transformers achieve detection precision and recall values above 0.9, while the investigated LLMs struggle with the task.
Assisted Knowledge Graph Authoring: Human-Supervised Knowledge Graph Construction from Natural Language
Jan 15, 2024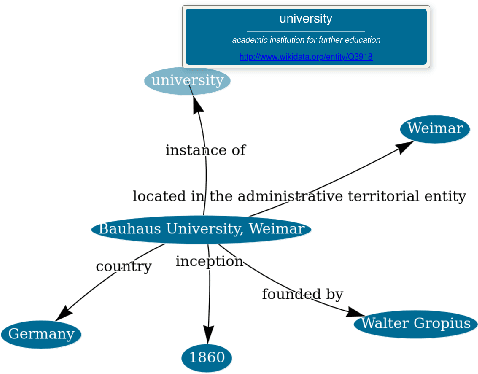


Encyclopedic knowledge graphs, such as Wikidata, host an extensive repository of millions of knowledge statements. However, domain-specific knowledge from fields such as history, physics, or medicine is significantly underrepresented in those graphs. Although few domain-specific knowledge graphs exist (e.g., Pubmed for medicine), developing specialized retrieval applications for many domains still requires constructing knowledge graphs from scratch. To facilitate knowledge graph construction, we introduce WAKA: a Web application that allows domain experts to create knowledge graphs through the medium with which they are most familiar: natural language.