 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentIR: Reasoning-Aware Retrieval for Deep Research Agents
Mar 05, 2026Deep Research agents are rapidly emerging as primary consumers of modern retrieval systems. Unlike human users who issue and refine queries without documenting their intermediate thought processes, Deep Research agents generate explicit natural language reasoning before each search call, revealing rich intent and contextual information that existing retrievers entirely ignore. To exploit this overlooked signal, we introduce: (1) Reasoning-Aware Retrieval, a retrieval paradigm that jointly embeds the agent's reasoning trace alongside its query; and (2) DR-Synth, a data synthesis method that generates Deep Research retriever training data from standard QA datasets. We demonstrate that both components are independently effective, and their combination yields a trained embedding model, AgentIR-4B, with substantial gains. On the challenging BrowseComp-Plus benchmark, AgentIR-4B achieves 68\% accuracy with the open-weight agent Tongyi-DeepResearch, compared to 50\% with conventional embedding models twice its size, and 37\% with BM25. Code and data are available at: https://texttron.github.io/AgentIR/.
Where Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking
Feb 26, 2026Zero-shot document re-ranking with Large Language Models (LLMs) has evolved from Pointwise methods to Listwise and Setwise approaches that optimize computational efficiency. Despite their success, these methods predominantly rely on generative scoring or output logits, which face bottlenecks in inference latency and result consistency. In-Context Re-ranking (ICR) has recently been proposed as an $O(1)$ alternative method. ICR extracts internal attention signals directly, avoiding the overhead of text generation. However, existing ICR methods simply aggregate signals across all layers; layer-wise contributions and their consistency across architectures have been left unexplored. Furthermore, no unified study has compared internal attention with traditional generative and likelihood-based mechanisms across diverse ranking frameworks under consistent conditions. In this paper, we conduct an orthogonal evaluation of generation, likelihood, and internal attention mechanisms across multiple ranking frameworks. We further identify a universal "bell-curve" distribution of relevance signals across transformer layers, which motivates the proposed Selective-ICR strategy that reduces inference latency by 30%-50% without compromising effectiveness. Finally, evaluation on the reasoning-intensive BRIGHT benchmark shows that precisely capturing high-quality in-context attention signals fundamentally reduces the need for model scaling and reinforcement learning: a zero-shot 8B model matches the performance of 14B reinforcement-learned re-rankers, while even a 0.6B model outperforms state-of-the-art generation-based approaches. These findings redefine the efficiency-effectiveness frontier for LLM-based re-ranking and highlight the latent potential of internal signals for complex reasoning ranking tasks. Our code and results are publicly available at https://github.com/ielab/Selective-ICR.
LACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
Leveraging Reference Documents for Zero-Shot Ranking via Large Language Models
Jun 13, 2025Large Language Models (LLMs) have demonstrated exceptional performance in the task of text ranking for information retrieval. While Pointwise ranking approaches offer computational efficiency by scoring documents independently, they often yield biased relevance estimates due to the lack of inter-document comparisons. In contrast, Pairwise methods improve ranking accuracy by explicitly comparing document pairs, but suffer from substantial computational overhead with quadratic complexity ($O(n^2)$). To address this tradeoff, we propose \textbf{RefRank}, a simple and effective comparative ranking method based on a fixed reference document. Instead of comparing all document pairs, RefRank prompts the LLM to evaluate each candidate relative to a shared reference anchor. By selecting the reference anchor that encapsulates the core query intent, RefRank implicitly captures relevance cues, enabling indirect comparison between documents via this common anchor. This reduces computational cost to linear time ($O(n)$) while importantly, preserving the advantages of comparative evaluation. To further enhance robustness, we aggregate multiple RefRank outputs using a weighted averaging scheme across different reference choices. Experiments on several benchmark datasets and with various LLMs show that RefRank significantly outperforms Pointwise baselines and could achieve performance at least on par with Pairwise approaches with a significantly lower computational cost.
MAGMaR Shared Task System Description: Video Retrieval with OmniEmbed
Jun 11, 2025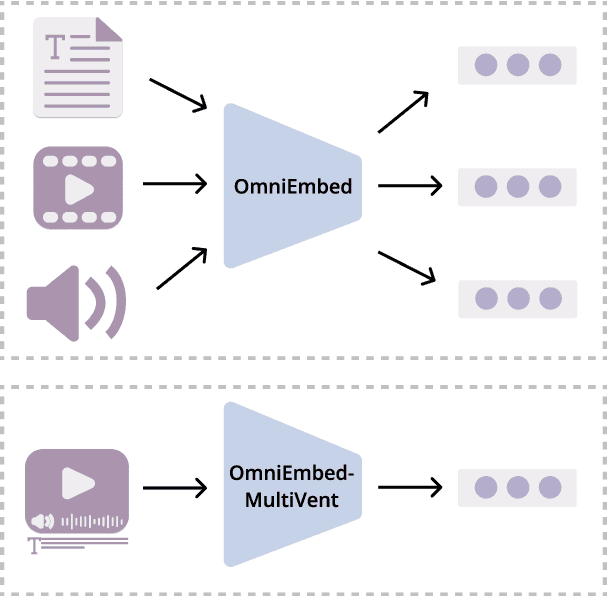
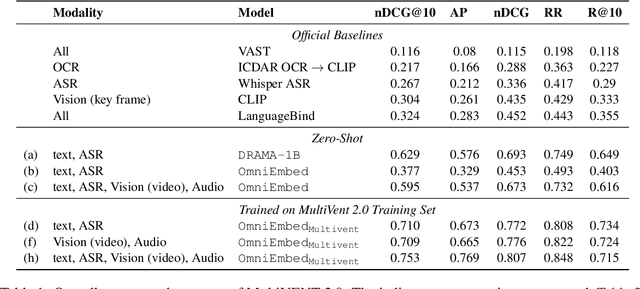
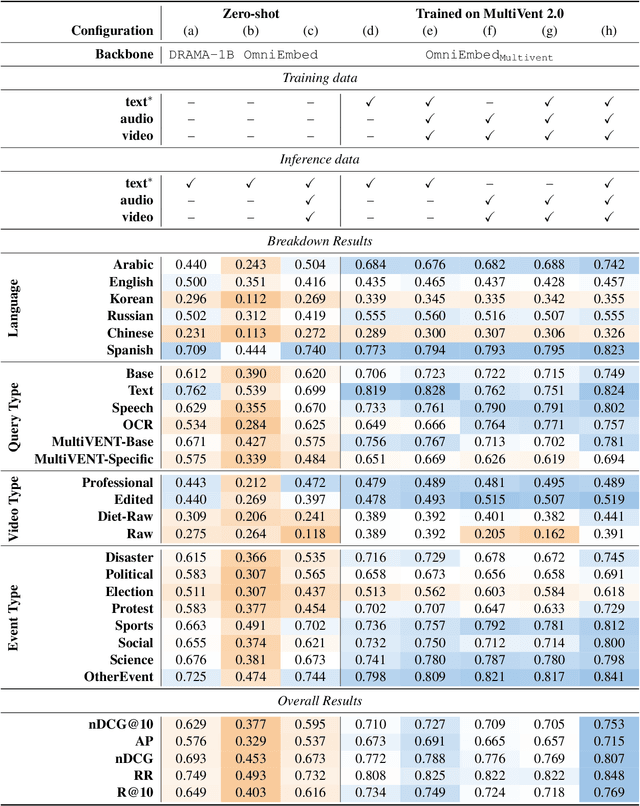
Effective video retrieval remains challenging due to the complexity of integrating visual, auditory, and textual modalities. In this paper, we explore unified retrieval methods using OmniEmbed, a powerful multimodal embedding model from the Tevatron 2.0 toolkit, in the context of the MAGMaR shared task. Evaluated on the comprehensive MultiVENT 2.0 dataset, OmniEmbed generates unified embeddings for text, images, audio, and video, enabling robust multimodal retrieval. By finetuning OmniEmbed with the combined multimodal data--visual frames, audio tracks, and textual descriptions provided in MultiVENT 2.0, we achieve substantial improvements in complex, multilingual video retrieval tasks. Our submission achieved the highest score on the MAGMaR shared task leaderboard among public submissions as of May 20th, 2025, highlighting the practical effectiveness of our unified multimodal retrieval approach. Model checkpoint in this work is opensourced.
Tevatron 2.0: Unified Document Retrieval Toolkit across Scale, Language, and Modality
May 05, 2025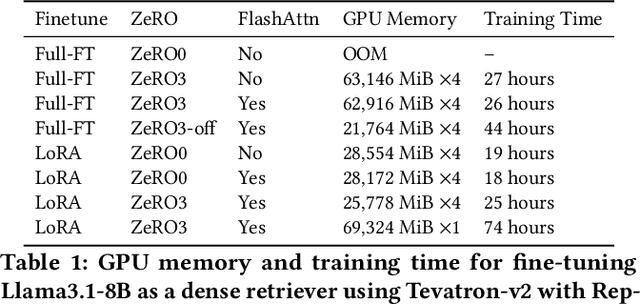
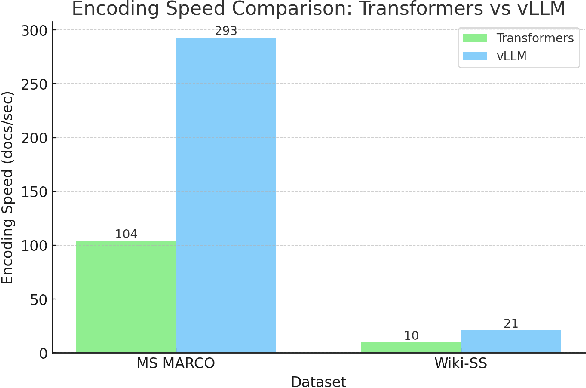
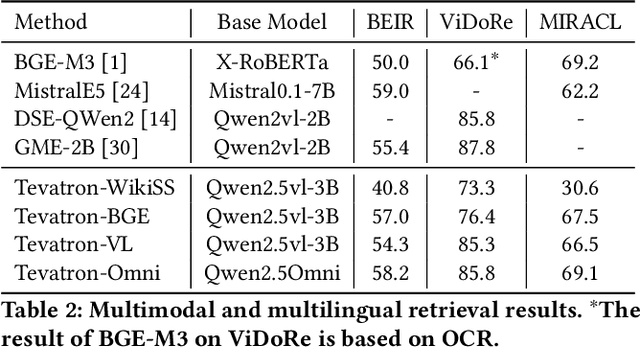

Recent advancements in large language models (LLMs) have driven interest in billion-scale retrieval models with strong generalization across retrieval tasks and languages. Additionally, progress in large vision-language models has created new opportunities for multimodal retrieval. In response, we have updated the Tevatron toolkit, introducing a unified pipeline that enables researchers to explore retriever models at different scales, across multiple languages, and with various modalities. This demo paper highlights the toolkit's key features, bridging academia and industry by supporting efficient training, inference, and evaluation of neural retrievers. We showcase a unified dense retriever achieving strong multilingual and multimodal effectiveness, and conduct a cross-modality zero-shot study to demonstrate its research potential. Alongside, we release OmniEmbed, to the best of our knowledge, the first embedding model that unifies text, image document, video, and audio retrieval, serving as a baseline for future research.
LLM-VPRF: Large Language Model Based Vector Pseudo Relevance Feedback
Apr 02, 2025Vector Pseudo Relevance Feedback (VPRF) has shown promising results in improving BERT-based dense retrieval systems through iterative refinement of query representations. This paper investigates the generalizability of VPRF to Large Language Model (LLM) based dense retrievers. We introduce LLM-VPRF and evaluate its effectiveness across multiple benchmark datasets, analyzing how different LLMs impact the feedback mechanism. Our results demonstrate that VPRF's benefits successfully extend to LLM architectures, establishing it as a robust technique for enhancing dense retrieval performance regardless of the underlying models. This work bridges the gap between VPRF with traditional BERT-based dense retrievers and modern LLMs, while providing insights into their future directions.
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning
Mar 08, 2025
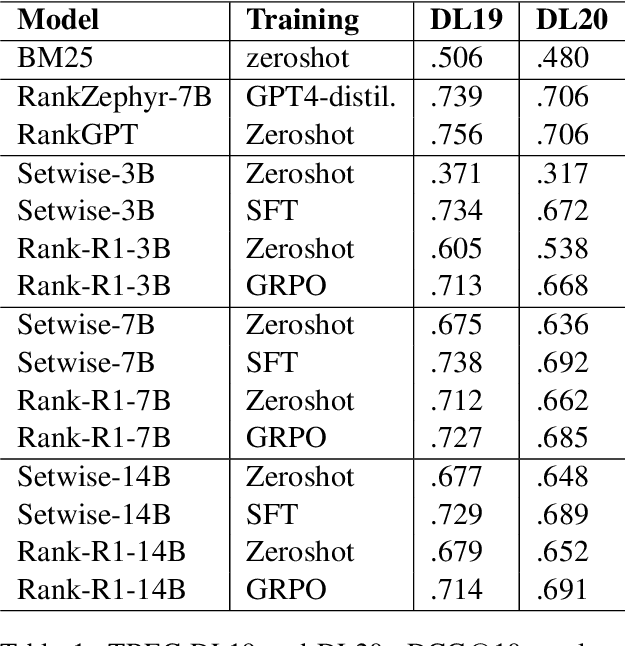
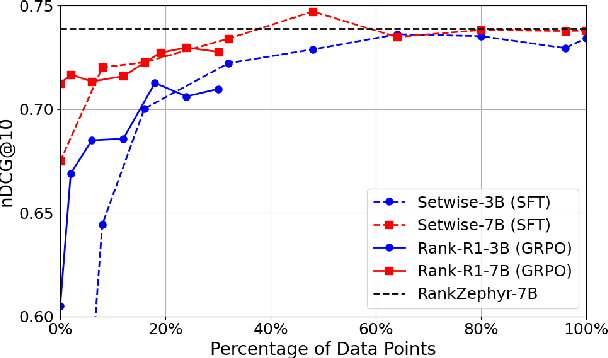
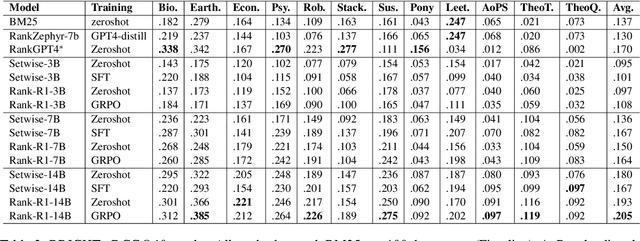
In this paper, we introduce Rank-R1, a novel LLM-based reranker that performs reasoning over both the user query and candidate documents before performing the ranking task. Existing document reranking methods based on large language models (LLMs) typically rely on prompting or fine-tuning LLMs to order or label candidate documents according to their relevance to a query. For Rank-R1, we use a reinforcement learning algorithm along with only a small set of relevance labels (without any reasoning supervision) to enhance the reasoning ability of LLM-based rerankers. Our hypothesis is that adding reasoning capabilities to the rerankers can improve their relevance assessement and ranking capabilities. Our experiments on the TREC DL and BRIGHT datasets show that Rank-R1 is highly effective, especially for complex queries. In particular, we find that Rank-R1 achieves effectiveness on in-domain datasets at par with that of supervised fine-tuning methods, but utilizing only 18\% of the training data used by the fine-tuning methods. We also find that the model largely outperforms zero-shot and supervised fine-tuning when applied to out-of-domain datasets featuring complex queries, especially when a 14B-size model is used. Finally, we qualitatively observe that Rank-R1's reasoning process improves the explainability of the ranking results, opening new opportunities for search engine results presentation and fruition.
Document Screenshot Retrievers are Vulnerable to Pixel Poisoning Attacks
Jan 28, 2025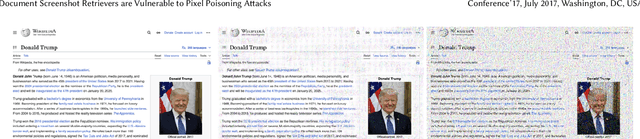
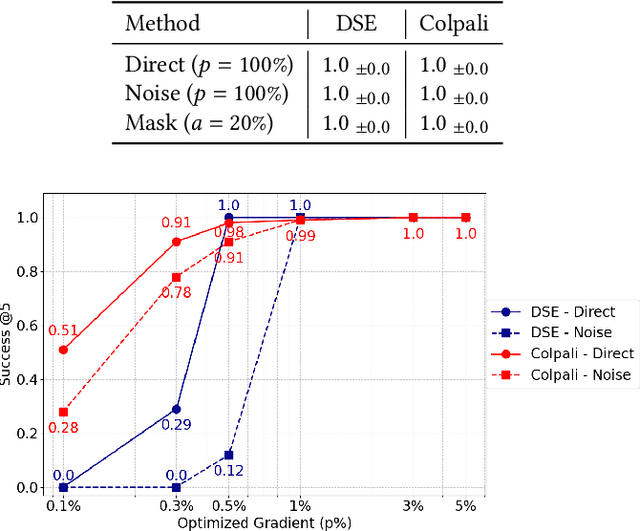

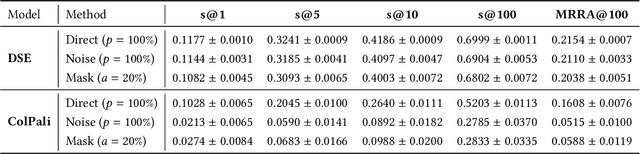
Recent advancements in dense retrieval have introduced vision-language model (VLM)-based retrievers, such as DSE and ColPali, which leverage document screenshots embedded as vectors to enable effective search and offer a simplified pipeline over traditional text-only methods. In this study, we propose three pixel poisoning attack methods designed to compromise VLM-based retrievers and evaluate their effectiveness under various attack settings and parameter configurations. Our empirical results demonstrate that injecting even a single adversarial screenshot into the retrieval corpus can significantly disrupt search results, poisoning the top-10 retrieved documents for 41.9% of queries in the case of DSE and 26.4% for ColPali. These vulnerability rates notably exceed those observed with equivalent attacks on text-only retrievers. Moreover, when targeting a small set of known queries, the attack success rate raises, achieving complete success in certain cases. By exposing the vulnerabilities inherent in vision-language models, this work highlights the potential risks associated with their deployment.
VISA: Retrieval Augmented Generation with Visual Source Attribution
Dec 19, 2024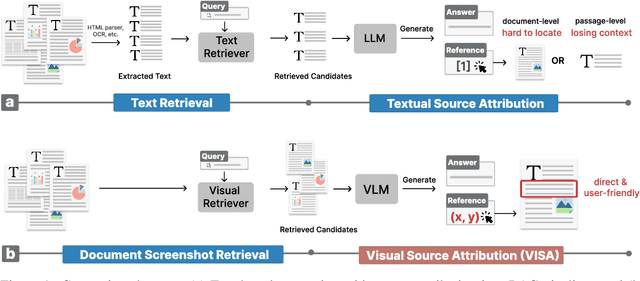
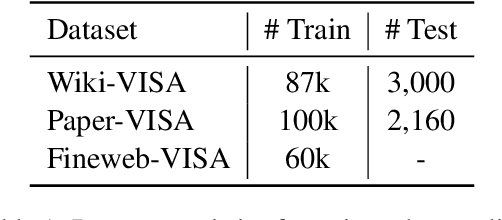
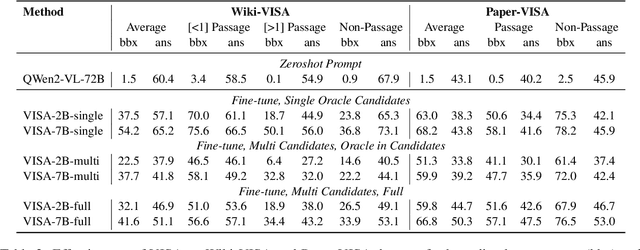

Generation with source attribution is important for enhancing the verifiability of retrieval-augmented generation (RAG) systems. However, existing approaches in RAG primarily link generated content to document-level references, making it challenging for users to locate evidence among multiple content-rich retrieved documents. To address this challenge, we propose Retrieval-Augmented Generation with Visual Source Attribution (VISA), a novel approach that combines answer generation with visual source attribution. Leveraging large vision-language models (VLMs), VISA identifies the evidence and highlights the exact regions that support the generated answers with bounding boxes in the retrieved document screenshots. To evaluate its effectiveness, we curated two datasets: Wiki-VISA, based on crawled Wikipedia webpage screenshots, and Paper-VISA, derived from PubLayNet and tailored to the medical domain. Experimental results demonstrate the effectiveness of VISA for visual source attribution on documents' original look, as well as highlighting the challenges for improvement. Code, data, and model checkpoints will be released.