 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
The Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining
Jan 01, 2026Multilingual large language models achieve impressive cross-lingual performance despite largely monolingual pretraining. While bilingual data in pretraining corpora is widely believed to enable these abilities, details of its contributions remain unclear. We investigate this question by pretraining models from scratch under controlled conditions, comparing the standard web corpus with a monolingual-only version that removes all multilingual documents. Despite constituting only 2% of the corpus, removing bilingual data causes translation performance to drop 56% in BLEU, while behaviour on cross-lingual QA and general reasoning tasks remains stable, with training curves largely overlapping the baseline. To understand this asymmetry, we categorize bilingual data into parallel (14%), code-switching (72%), and miscellaneous documents (14%) based on the semantic relevance of content in different languages. We then conduct granular ablations by reintroducing parallel or code-switching data into the monolingual-only corpus. Our experiments reveal that parallel data almost fully restores translation performance (91% of the unfiltered baseline), whereas code-switching contributes minimally. Other cross-lingual tasks remain largely unaffected by either type. These findings reveal that translation critically depends on systematic token-level alignments from parallel data, whereas cross-lingual understanding and reasoning appear to be achievable even without bilingual data.
Drawing Conclusions from Draws: Rethinking Preference Semantics in Arena-Style LLM Evaluation
Oct 02, 2025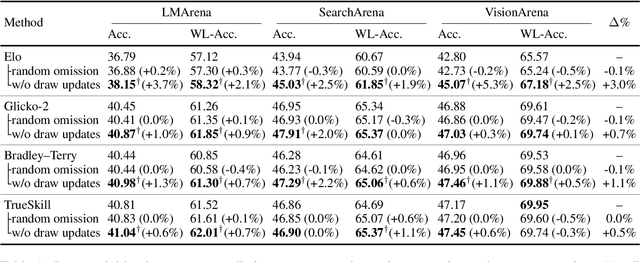
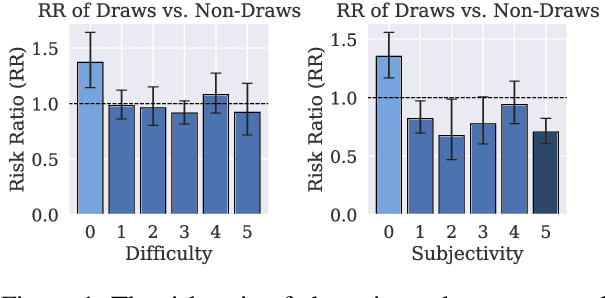
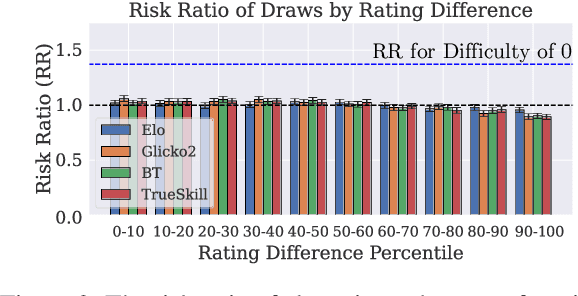
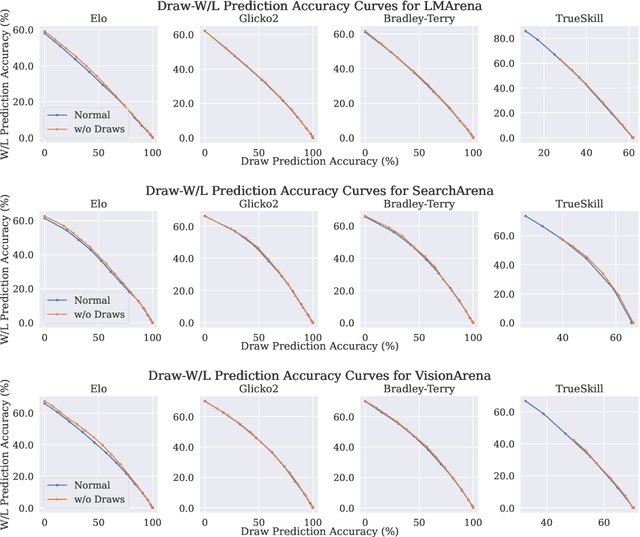
In arena-style evaluation of large language models (LLMs), two LLMs respond to a user query, and the user chooses the winning response or deems the "battle" a draw, resulting in an adjustment to the ratings of both models. The prevailing approach for modeling these rating dynamics is to view battles as two-player game matches, as in chess, and apply the Elo rating system and its derivatives. In this paper, we critically examine this paradigm. Specifically, we question whether a draw genuinely means that the two models are equal and hence whether their ratings should be equalized. Instead, we conjecture that draws are more indicative of query difficulty: if the query is too easy, then both models are more likely to succeed equally. On three real-world arena datasets, we show that ignoring rating updates for draws yields a 1-3% relative increase in battle outcome prediction accuracy (which includes draws) for all four rating systems studied. Further analyses suggest that draws occur more for queries rated as very easy and those as highly objective, with risk ratios of 1.37 and 1.35, respectively. We recommend future rating systems to reconsider existing draw semantics and to account for query properties in rating updates.
MAGMaR Shared Task System Description: Video Retrieval with OmniEmbed
Jun 11, 2025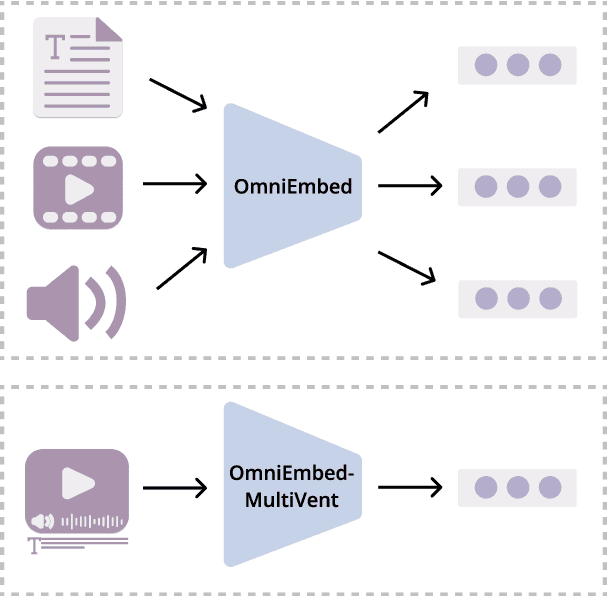
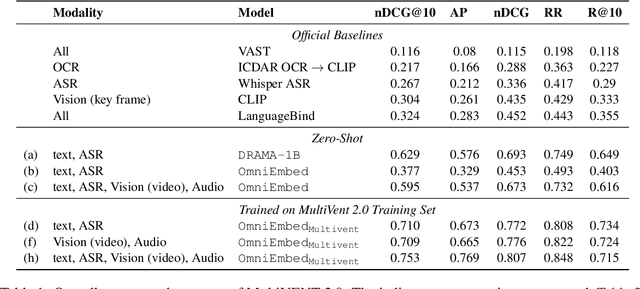
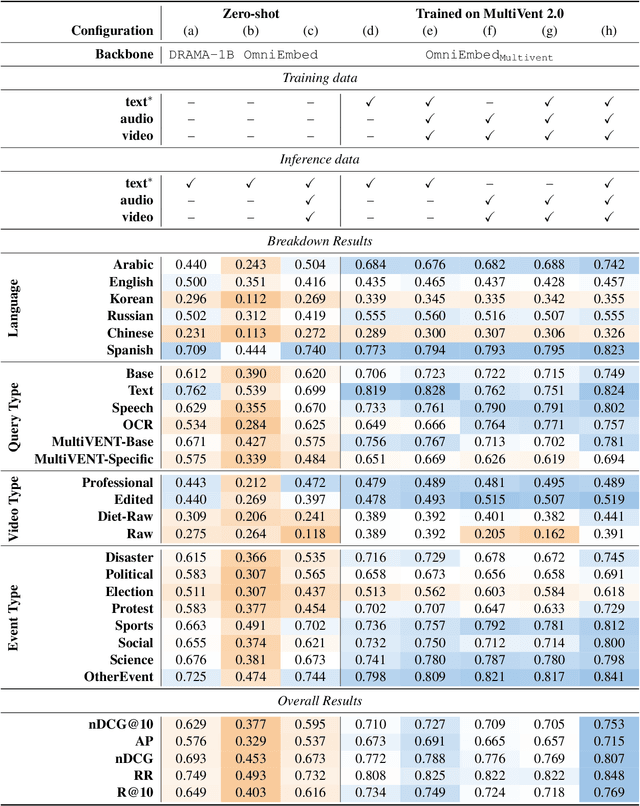
Effective video retrieval remains challenging due to the complexity of integrating visual, auditory, and textual modalities. In this paper, we explore unified retrieval methods using OmniEmbed, a powerful multimodal embedding model from the Tevatron 2.0 toolkit, in the context of the MAGMaR shared task. Evaluated on the comprehensive MultiVENT 2.0 dataset, OmniEmbed generates unified embeddings for text, images, audio, and video, enabling robust multimodal retrieval. By finetuning OmniEmbed with the combined multimodal data--visual frames, audio tracks, and textual descriptions provided in MultiVENT 2.0, we achieve substantial improvements in complex, multilingual video retrieval tasks. Our submission achieved the highest score on the MAGMaR shared task leaderboard among public submissions as of May 20th, 2025, highlighting the practical effectiveness of our unified multimodal retrieval approach. Model checkpoint in this work is opensourced.
Fixing Data That Hurts Performance: Cascading LLMs to Relabel Hard Negatives for Robust Information Retrieval
May 22, 2025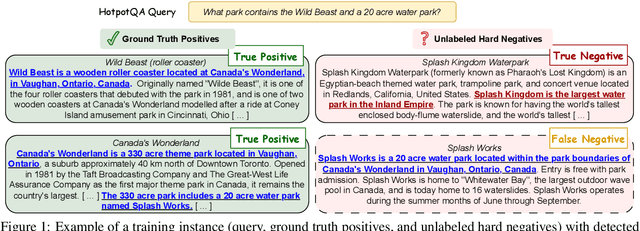
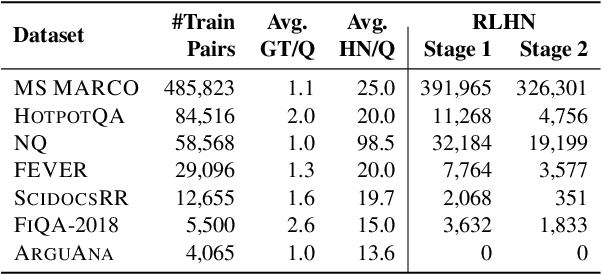
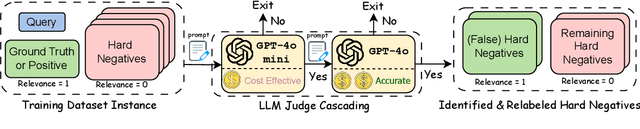
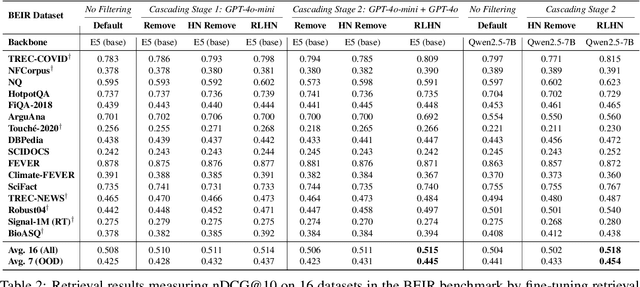
Training robust retrieval and reranker models typically relies on large-scale retrieval datasets; for example, the BGE collection contains 1.6 million query-passage pairs sourced from various data sources. However, we find that certain datasets can negatively impact model effectiveness -- pruning 8 out of 15 datasets from the BGE collection reduces the training set size by 2.35$\times$ and increases nDCG@10 on BEIR by 1.0 point. This motivates a deeper examination of training data quality, with a particular focus on "false negatives", where relevant passages are incorrectly labeled as irrelevant. We propose a simple, cost-effective approach using cascading LLM prompts to identify and relabel hard negatives. Experimental results show that relabeling false negatives with true positives improves both E5 (base) and Qwen2.5-7B retrieval models by 0.7-1.4 nDCG@10 on BEIR and by 1.7-1.8 nDCG@10 on zero-shot AIR-Bench evaluation. Similar gains are observed for rerankers fine-tuned on the relabeled data, such as Qwen2.5-3B on BEIR. The reliability of the cascading design is further supported by human annotation results, where we find judgment by GPT-4o shows much higher agreement with humans than GPT-4o-mini.
A Survey of Model Architectures in Information Retrieval
Feb 20, 2025This survey examines the evolution of model architectures in information retrieval (IR), focusing on two key aspects: backbone models for feature extraction and end-to-end system architectures for relevance estimation. The review intentionally separates architectural considerations from training methodologies to provide a focused analysis of structural innovations in IR systems.We trace the development from traditional term-based methods to modern neural approaches, particularly highlighting the impact of transformer-based models and subsequent large language models (LLMs). We conclude by discussing emerging challenges and future directions, including architectural optimizations for performance and scalability, handling of multimodal, multilingual data, and adaptation to novel application domains beyond traditional search paradigms.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.