 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCDA: Thread-Constrained Discourse-Aware Modeling for Conversational Sentiment Quadruple Analysis
May 03, 2026Conversational Aspect-based Sentiment Quadruple Analysis (DiaASQ) needs to capture the complex interrelationships in multiple rounds of dialogues. Existing methods usually employ simple Graph Convolutional Networks (GCN), which introduce structural noise and fail to consider the temporal sequence of the dialogues, or use standard RoPE, which implicitly captures relative distances in a flat sequence but cannot clearly separate the token-level syntactic order from the utterance-level progression, and may suffer from the Distance Dilution problem. To address these issues, we propose a new framework that combines Thread-Constrained Directed Acyclic Graph (TC-DAG) and Discourse-Aware Rotary Position Embedding (D-RoPE). Specifically, TC-DAG filters out cross-thread noise based on thread constraints, maintains global connectivity through root anchoring, and incorporates the temporal sequence of the dialogues. D-RoPE aligns multi-layer semantics using dual-stream projection and multi-scale frequency signals, captures thread dependencies using tree-like distances, and alleviates the token-level Distance Dilution problem by incorporating utterance-level progressions. Experimental results on two benchmark datasets demonstrate that our framework achieves state-of-the-art performance.
Learning to Route Queries to Heads for Attention-based Re-ranking with Large Language Models
Apr 27, 2026Large Language Models (LLMs) have recently been explored as fine-grained zero-shot re-rankers by leveraging attention signals to estimate document relevance. However, existing methods either aggregate attention signals across all heads or rely on a statically selected subset identified by heuristic rules. This solution can be suboptimal because the informative heads can vary across queries or domains. Moreover, naively combining multiple heads can degrade performance due to redundancy or conflicting ranking signals. In this paper, we propose a query-dependent head selection method, RouteHead, for attention-based re-ranking with LLMs. Specifically, we learn a lightweight router that can map each query to an optimal head set, and relevance scores are computed by aggregating attention signals only from these heads. Since query-to-head optimal labels are unavailable, we first construct pseudo labels via an offline search. The router represents each head with a learnable embedding and represents each query using an embedding extracted from the hidden states of the frozen LLM. Then it is trained on the pseudo labels with a sparsity regularizer. Experiments on diverse benchmarks and multiple LLM backbones show that the proposed method consistently outperforms strong baselines.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Towards Pixel-Level VLM Perception via Simple Points Prediction
Jan 27, 2026We present SimpleSeg, a strikingly simple yet highly effective approach to endow Multimodal Large Language Models (MLLMs) with native pixel-level perception. Our method reframes segmentation as a simple sequence generation problem: the model directly predicts sequences of points (textual coordinates) delineating object boundaries, entirely within its language space. To achieve high fidelity, we introduce a two-stage SF$\to$RL training pipeline, where Reinforcement Learning with an IoU-based reward refines the point sequences to accurately match ground-truth contours. We find that the standard MLLM architecture possesses a strong, inherent capacity for low-level perception that can be unlocked without any specialized architecture. On segmentation benchmarks, SimpleSeg achieves performance that is comparable to, and often surpasses, methods relying on complex, task-specific designs. This work lays out that precise spatial understanding can emerge from simple point prediction, challenging the prevailing need for auxiliary components and paving the way for more unified and capable VLMs. Homepage: https://simpleseg.github.io/
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
MMErroR: A Benchmark for Erroneous Reasoning in Vision-Language Models
Jan 06, 2026Recent advances in Vision-Language Models (VLMs) have improved performance in multi-modal learning, raising the question of whether these models truly understand the content they process. Crucially, can VLMs detect when a reasoning process is wrong and identify its error type? To answer this, we present MMErroR, a multi-modal benchmark of 2,013 samples, each embedding a single coherent reasoning error. These samples span 24 subdomains across six top-level domains, ensuring broad coverage and taxonomic richness. Unlike existing benchmarks that focus on answer correctness, MMErroR targets a process-level, error-centric evaluation that requires models to detect incorrect reasoning and classify the error type within both visual and linguistic contexts. We evaluate 20 advanced VLMs, even the best model (Gemini-3.0-Pro) classifies the error in only 66.47\% of cases, underscoring the challenge of identifying erroneous reasoning. Furthermore, the ability to accurately identify errors offers valuable insights into the capabilities of multi-modal reasoning models. Project Page: https://mmerror-benchmark.github.io
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
G1: Bootstrapping Perception and Reasoning Abilities of Vision-Language Model via Reinforcement Learning
May 19, 2025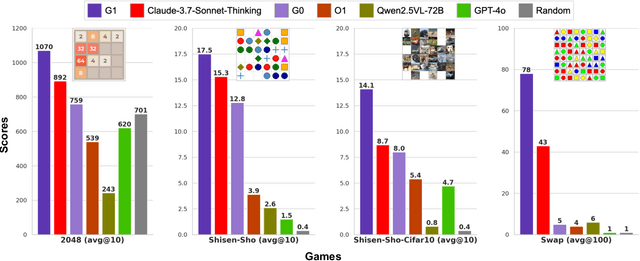
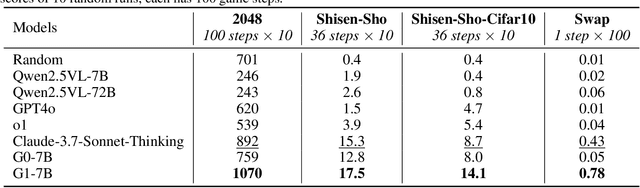
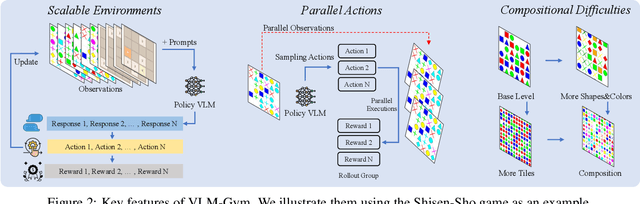
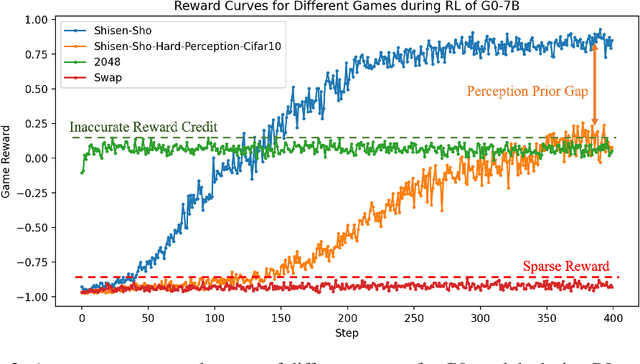
Vision-Language Models (VLMs) excel in many direct multimodal tasks but struggle to translate this prowess into effective decision-making within interactive, visually rich environments like games. This ``knowing-doing'' gap significantly limits their potential as autonomous agents, as leading VLMs often performing badly in simple games. To address this, we introduce VLM-Gym, a curated reinforcement learning (RL) environment featuring diverse visual games with unified interfaces and adjustable, compositional difficulty, specifically designed for scalable multi-game parallel training. Leveraging VLM-Gym, we train G0 models using pure RL-driven self-evolution, which demonstrate emergent perception and reasoning patterns. To further mitigate challenges arising from game diversity, we develop G1 models. G1 incorporates a perception-enhanced cold start prior to RL fine-tuning. Our resulting G1 models consistently surpass their teacher across all games and outperform leading proprietary models like Claude-3.7-Sonnet-Thinking. Systematic analysis reveals an intriguing finding: perception and reasoning abilities mutually bootstrap each other throughout the RL training process. Source code including VLM-Gym and RL training are released at https://github.com/chenllliang/G1 to foster future research in advancing VLMs as capable interactive agents.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.