 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Prompt Decoding for Multilingual Dense Retrieval
Paper and Code
May 15, 2023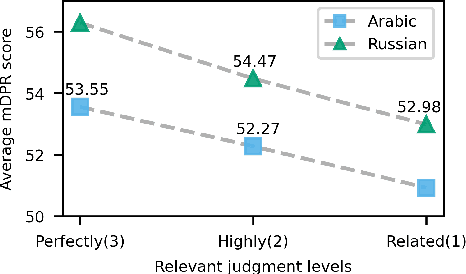
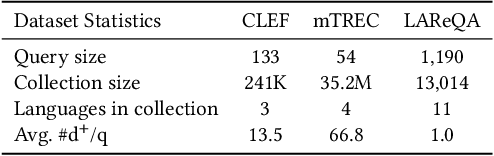
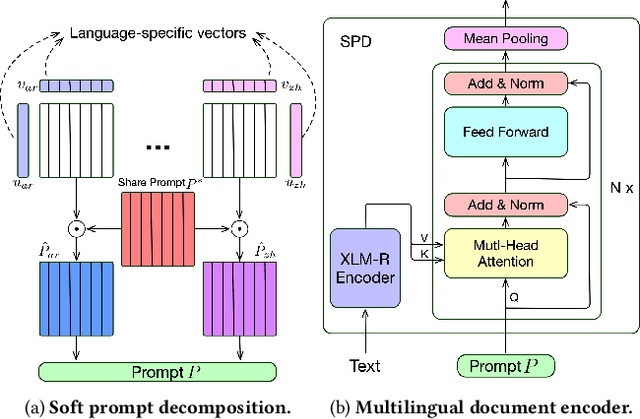
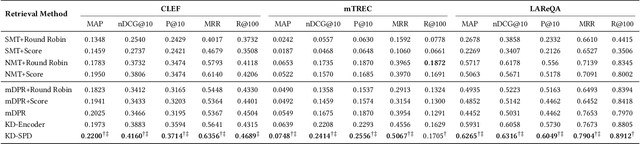
In this work, we explore a Multilingual Information Retrieval (MLIR) task, where the collection includes documents in multiple languages. We demonstrate that applying state-of-the-art approaches developed for cross-lingual information retrieval to MLIR tasks leads to sub-optimal performance. This is due to the heterogeneous and imbalanced nature of multilingual collections -- some languages are better represented in the collection and some benefit from large-scale training data. To address this issue, we present KD-SPD, a novel soft prompt decoding approach for MLIR that implicitly "translates" the representation of documents in different languages into the same embedding space. To address the challenges of data scarcity and imbalance, we introduce a knowledge distillation strategy. The teacher model is trained on rich English retrieval data, and by leveraging bi-text data, our distillation framework transfers its retrieval knowledge to the multilingual document encoder. Therefore, our approach does not require any multilingual retrieval training data. Extensive experiments on three MLIR datasets with a total of 15 languages demonstrate that KD-SPD significantly outperforms competitive baselines in all cases. We conduct extensive analyses to show that our method has less language bias and better zero-shot transfer ability towards new languages.