 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-based Trial and Error Falls Behind in the Era of Experience
Jan 29, 2026While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and the testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Tasks), a novel framework that decouples exploration from exploitation. We employ lightweight "scouts" (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
Towards Reliable Medical LLMs: Benchmarking and Enhancing Confidence Estimation of Large Language Models in Medical Consultation
Jan 22, 2026Large-scale language models (LLMs) often offer clinical judgments based on incomplete information, increasing the risk of misdiagnosis. Existing studies have primarily evaluated confidence in single-turn, static settings, overlooking the coupling between confidence and correctness as clinical evidence accumulates during real consultations, which limits their support for reliable decision-making. We propose the first benchmark for assessing confidence in multi-turn interaction during realistic medical consultations. Our benchmark unifies three types of medical data for open-ended diagnostic generation and introduces an information sufficiency gradient to characterize the confidence-correctness dynamics as evidence increases. We implement and compare 27 representative methods on this benchmark; two key insights emerge: (1) medical data amplifies the inherent limitations of token-level and consistency-level confidence methods, and (2) medical reasoning must be evaluated for both diagnostic accuracy and information completeness. Based on these insights, we present MedConf, an evidence-grounded linguistic self-assessment framework that constructs symptom profiles via retrieval-augmented generation, aligns patient information with supporting, missing, and contradictory relations, and aggregates them into an interpretable confidence estimate through weighted integration. Across two LLMs and three medical datasets, MedConf consistently outperforms state-of-the-art methods on both AUROC and Pearson correlation coefficient metrics, maintaining stable performance under conditions of information insufficiency and multimorbidity. These results demonstrate that information adequacy is a key determinant of credible medical confidence modeling, providing a new pathway toward building more reliable and interpretable large medical models.
Mastering Massive Multi-Task Reinforcement Learning via Mixture-of-Expert Decision Transformer
May 30, 2025Despite recent advancements in offline multi-task reinforcement learning (MTRL) have harnessed the powerful capabilities of the Transformer architecture, most approaches focus on a limited number of tasks, with scaling to extremely massive tasks remaining a formidable challenge. In this paper, we first revisit the key impact of task numbers on current MTRL method, and further reveal that naively expanding the parameters proves insufficient to counteract the performance degradation as the number of tasks escalates. Building upon these insights, we propose M3DT, a novel mixture-of-experts (MoE) framework that tackles task scalability by further unlocking the model's parameter scalability. Specifically, we enhance both the architecture and the optimization of the agent, where we strengthen the Decision Transformer (DT) backbone with MoE to reduce task load on parameter subsets, and introduce a three-stage training mechanism to facilitate efficient training with optimal performance. Experimental results show that, by increasing the number of experts, M3DT not only consistently enhances its performance as model expansion on the fixed task numbers, but also exhibits remarkable task scalability, successfully extending to 160 tasks with superior performance.
Plasticine: Accelerating Research in Plasticity-Motivated Deep Reinforcement Learning
Apr 24, 2025Developing lifelong learning agents is crucial for artificial general intelligence. However, deep reinforcement learning (RL) systems often suffer from plasticity loss, where neural networks gradually lose their ability to adapt during training. Despite its significance, this field lacks unified benchmarks and evaluation protocols. We introduce Plasticine, the first open-source framework for benchmarking plasticity optimization in deep RL. Plasticine provides single-file implementations of over 13 mitigation methods, 10 evaluation metrics, and learning scenarios with increasing non-stationarity levels from standard to open-ended environments. This framework enables researchers to systematically quantify plasticity loss, evaluate mitigation strategies, and analyze plasticity dynamics across different contexts. Our documentation, examples, and source code are available at https://github.com/RLE-Foundation/Plasticine.
Faster and Better 3D Splatting via Group Training
Dec 10, 2024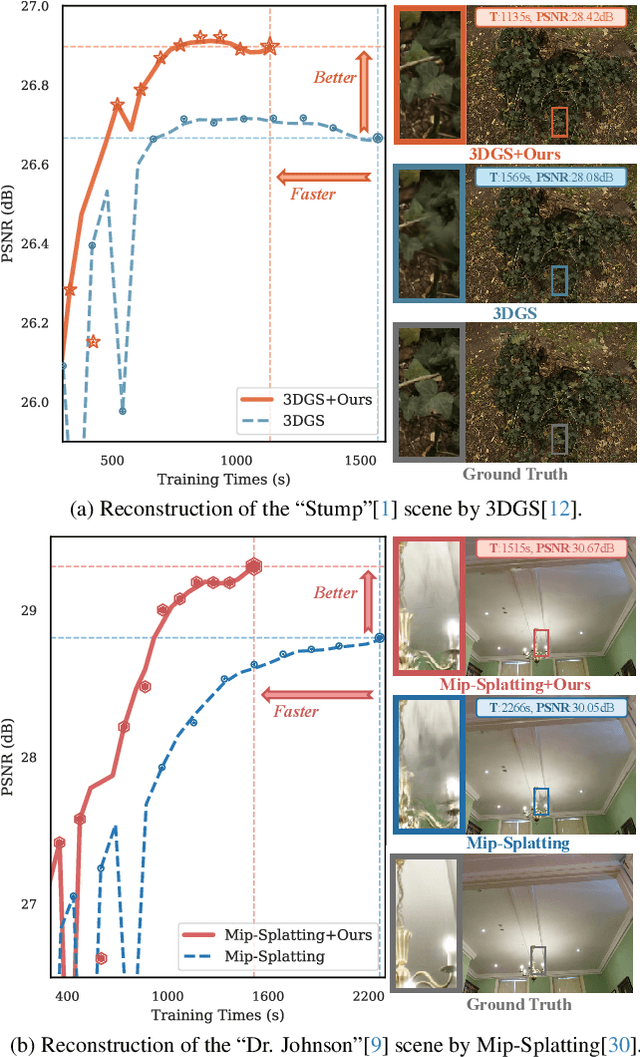

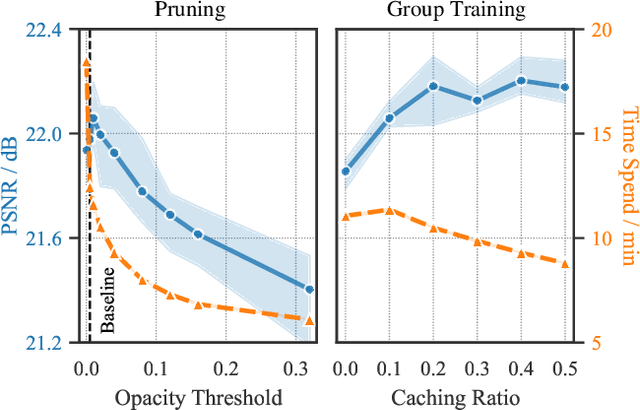

3D Gaussian Splatting (3DGS) has emerged as a powerful technique for novel view synthesis, demonstrating remarkable capability in high-fidelity scene reconstruction through its Gaussian primitive representations. However, the computational overhead induced by the massive number of primitives poses a significant bottleneck to training efficiency. To overcome this challenge, we propose Group Training, a simple yet effective strategy that organizes Gaussian primitives into manageable groups, optimizing training efficiency and improving rendering quality. This approach shows universal compatibility with existing 3DGS frameworks, including vanilla 3DGS and Mip-Splatting, consistently achieving accelerated training while maintaining superior synthesis quality. Extensive experiments reveal that our straightforward Group Training strategy achieves up to 30% faster convergence and improved rendering quality across diverse scenarios.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping
Feb 22, 2024Self-alignment is an effective way to reduce the cost of human annotation while ensuring promising model capability. However, most current methods complete the data collection and training steps in a single round, which may overlook the continuously improving ability of self-aligned models. This gives rise to a key query: What if we do multi-time bootstrapping self-alignment? Does this strategy enhance model performance or lead to rapid degradation? In this paper, our pioneering exploration delves into the impact of bootstrapping self-alignment on large language models. Our findings reveal that bootstrapping self-alignment markedly surpasses the single-round approach, by guaranteeing data diversity from in-context learning. To further exploit the capabilities of bootstrapping, we investigate and adjust the training order of data, which yields improved performance of the model. Drawing on these findings, we propose Step-On-Feet Tuning (SOFT) which leverages model's continuously enhanced few-shot ability to boost zero or one-shot performance. Based on easy-to-hard training recipe, we propose SOFT+ which further boost self-alignment's performance. Our experiments demonstrate the efficiency of SOFT (SOFT+) across various classification and generation tasks, highlighting the potential of bootstrapping self-alignment on continually enhancing model alignment performance.
Revisiting Plasticity in Visual Reinforcement Learning: Data, Modules and Training Stages
Oct 11, 2023



Plasticity, the ability of a neural network to evolve with new data, is crucial for high-performance and sample-efficient visual reinforcement learning (VRL). Although methods like resetting and regularization can potentially mitigate plasticity loss, the influences of various components within the VRL framework on the agent's plasticity are still poorly understood. In this work, we conduct a systematic empirical exploration focusing on three primary underexplored facets and derive the following insightful conclusions: (1) data augmentation is essential in maintaining plasticity; (2) the critic's plasticity loss serves as the principal bottleneck impeding efficient training; and (3) without timely intervention to recover critic's plasticity in the early stages, its loss becomes catastrophic. These insights suggest a novel strategy to address the high replay ratio (RR) dilemma, where exacerbated plasticity loss hinders the potential improvements of sample efficiency brought by increased reuse frequency. Rather than setting a static RR for the entire training process, we propose Adaptive RR, which dynamically adjusts the RR based on the critic's plasticity level. Extensive evaluations indicate that Adaptive RR not only avoids catastrophic plasticity loss in the early stages but also benefits from more frequent reuse in later phases, resulting in superior sample efficiency.
Are Large Language Models Really Robust to Word-Level Perturbations?
Sep 27, 2023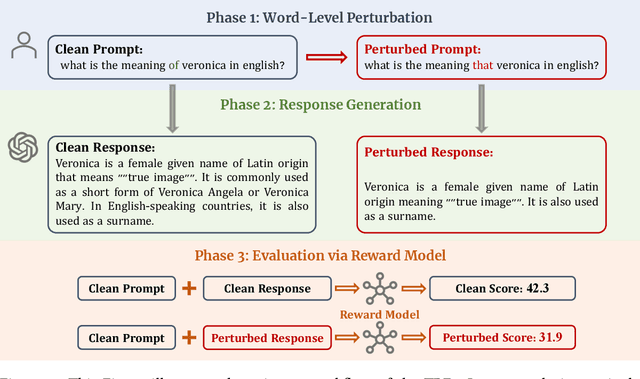


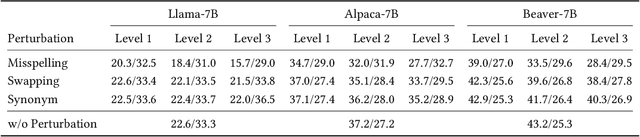
The swift advancement in the scales and capabilities of Large Language Models (LLMs) positions them as promising tools for a variety of downstream tasks. In addition to the pursuit of better performance and the avoidance of violent feedback on a certain prompt, to ensure the responsibility of the LLM, much attention is drawn to the robustness of LLMs. However, existing evaluation methods mostly rely on traditional question answering datasets with predefined supervised labels, which do not align with the superior generation capabilities of contemporary LLMs. To address this issue, we propose a novel rational evaluation approach that leverages pre-trained reward models as diagnostic tools to evaluate the longer conversation generated from more challenging open questions by LLMs, which we refer to as the Reward Model for Reasonable Robustness Evaluation (TREvaL). Longer conversations manifest the comprehensive grasp of language models in terms of their proficiency in understanding questions, a capability not entirely encompassed by individual words or letters, which may exhibit oversimplification and inherent biases. Our extensive empirical experiments demonstrate that TREvaL provides an innovative method for evaluating the robustness of an LLM. Furthermore, our results demonstrate that LLMs frequently exhibit vulnerability to word-level perturbations that are commonplace in daily language usage. Notably, we are surprised to discover that robustness tends to decrease as fine-tuning (SFT and RLHF) is conducted. The code of TREval is available in https://github.com/Harry-mic/TREvaL.
Normalization Enhances Generalization in Visual Reinforcement Learning
Jun 01, 2023



Recent advances in visual reinforcement learning (RL) have led to impressive success in handling complex tasks. However, these methods have demonstrated limited generalization capability to visual disturbances, which poses a significant challenge for their real-world application and adaptability. Though normalization techniques have demonstrated huge success in supervised and unsupervised learning, their applications in visual RL are still scarce. In this paper, we explore the potential benefits of integrating normalization into visual RL methods with respect to generalization performance. We find that, perhaps surprisingly, incorporating suitable normalization techniques is sufficient to enhance the generalization capabilities, without any additional special design. We utilize the combination of two normalization techniques, CrossNorm and SelfNorm, for generalizable visual RL. Extensive experiments are conducted on DMControl Generalization Benchmark and CARLA to validate the effectiveness of our method. We show that our method significantly improves generalization capability while only marginally affecting sample efficiency. In particular, when integrated with DrQ-v2, our method enhances the test performance of DrQ-v2 on CARLA across various scenarios, from 14% of the training performance to 97%.
Learning Better with Less: Effective Augmentation for Sample-Efficient Visual Reinforcement Learning
May 25, 2023



Data augmentation (DA) is a crucial technique for enhancing the sample efficiency of visual reinforcement learning (RL) algorithms. Notably, employing simple observation transformations alone can yield outstanding performance without extra auxiliary representation tasks or pre-trained encoders. However, it remains unclear which attributes of DA account for its effectiveness in achieving sample-efficient visual RL. To investigate this issue and further explore the potential of DA, this work conducts comprehensive experiments to assess the impact of DA's attributes on its efficacy and provides the following insights and improvements: (1) For individual DA operations, we reveal that both ample spatial diversity and slight hardness are indispensable. Building on this finding, we introduce Random PadResize (Rand PR), a new DA operation that offers abundant spatial diversity with minimal hardness. (2) For multi-type DA fusion schemes, the increased DA hardness and unstable data distribution result in the current fusion schemes being unable to achieve higher sample efficiency than their corresponding individual operations. Taking the non-stationary nature of RL into account, we propose a RL-tailored multi-type DA fusion scheme called Cycling Augmentation (CycAug), which performs periodic cycles of different DA operations to increase type diversity while maintaining data distribution consistency. Extensive evaluations on the DeepMind Control suite and CARLA driving simulator demonstrate that our methods achieve superior sample efficiency compared with the prior state-of-the-art methods.