 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWISV: Wireless-Informed Semantic Verification for Distributed Speculative Decoding in Device-Edge LLM Inference
Apr 20, 2026While distributed device-edge speculative decoding enhances resource utilization across heterogeneous nodes, its performance is often bottlenecked by conventional token-level verification strategies. Such rigid alignment leads to excessive rejections, significantly diminishing the accepted sequence length and increasing interaction rounds under fluctuating wireless conditions. In this paper, we propose WISV (Wireless-Informed Semantic Verification), a novel distributed speculative decoding framework that goes beyond strict token-level matching via a channel-aware semantic acceptance policy. WISV integrates a lightweight decision head into the edge-side target LLM to dynamically evaluate speculative tokens by synthesizing high-dimensional hidden representations with instantaneous channel state information (CSI). To optimize the trade-off between verification fidelity and communication overhead, we further design two tailored communication protocols: full-hidden upload and mismatch-first selective-hidden upload. Extensive simulations using a 1B drafter and an 8B target model demonstrate that WISV achieves up to a 60.8% increase in accepted length, a 37.3% reduction in interaction rounds, and a 31.4% improvement in end-to-end latency compared to vanilla speculative decoding across tested settings, while maintaining a negligible task accuracy drop (<1%). Finally, we validate WISV on a hardware testbed comprising an NVIDIA Jetson AGX Orin and an A40-equipped server, confirming its real-world efficacy in accelerating edge-deployed LLM inference.
Robust Optimization for Mitigating Reward Hacking with Correlated Proxies
Apr 13, 2026Designing robust reinforcement learning (RL) agents in the presence of imperfect reward signals remains a core challenge. In practice, agents are often trained with proxy rewards that only approximate the true objective, leaving them vulnerable to reward hacking, where high proxy returns arise from unintended or exploitative behaviors. Recent work formalizes this issue using r-correlation between proxy and true rewards, but existing methods like occupancy-regularized policy optimization (ORPO) optimize against a fixed proxy and do not provide strong guarantees against broader classes of correlated proxies. In this work, we formulate reward hacking as a robust policy optimization problem over the space of all r-correlated proxy rewards. We derive a tractable max-min formulation, where the agent maximizes performance under the worst-case proxy consistent with the correlation constraint. We further show that when the reward is a linear function of known features, our approach can be adapted to incorporate this prior knowledge, yielding both improved policies and interpretable worst-case rewards. Experiments across several environments show that our algorithms consistently outperform ORPO in worst-case returns, and offer improved robustness and stability across different levels of proxy-true reward correlation. These results show that our approach provides both robustness and transparency in settings where reward design is inherently uncertain. The code is available at https://github.com/ZixuanLiu4869/reward_hacking.
MemBoost: A Memory-Boosted Framework for Cost-Aware LLM Inference
Mar 27, 2026Large Language Models (LLMs) deliver strong performance but incur high inference cost in real-world services, especially under workloads with repeated or near-duplicate queries across users and sessions. In this work, we propose MemBoost, a memory-boosted LLM serving framework that enables a lightweight model to reuse previously generated answers and retrieve relevant supporting information for cheap inference, while selectively escalating difficult or uncertain queries to a stronger model. Unlike standard retrieval-augmented generation, which primarily grounds a single response, MemBoost is designed for interactive settings by supporting answer reuse, continual memory growth, and cost-aware routing. Experiments across multiple models under simulated workloads show that MemBoost substantially reduces expensive large-model invocations and overall inference cost, while maintaining high answer quality comparable to the strong model baseline.
Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Mar 11, 2026Deep Reinforcement learning (DRL) has achieved remarkable success in domains with well-defined reward structures, such as Atari games and locomotion. In contrast, dexterous manipulation lacks general-purpose reward formulations and typically depends on task-specific, handcrafted priors to guide hand-object interactions. We propose Contact Coverage-Guided Exploration (CCGE), a general exploration method designed for general-purpose dexterous manipulation tasks. CCGE represents contact state as the intersection between object surface points and predefined hand keypoints, encouraging dexterous hands to discover diverse and novel contact patterns, namely which fingers contact which object regions. It maintains a contact counter conditioned on discretized object states obtained via learned hash codes, capturing how frequently each finger interacts with different object regions. This counter is leveraged in two complementary ways: (1) to assign a count-based contact coverage reward that promotes exploration of novel contact patterns, and (2) an energy-based reaching reward that guides the agent toward under-explored contact regions. We evaluate CCGE on a diverse set of dexterous manipulation tasks, including cluttered object singulation, constrained object retrieval, in-hand reorientation, and bimanual manipulation. Experimental results show that CCGE substantially improves training efficiency and success rates over existing exploration methods, and that the contact patterns learned with CCGE transfer robustly to real-world robotic systems. Project page is https://contact-coverage-guided-exploration.github.io.
LycheeCluster: Efficient Long-Context Inference with Structure-Aware Chunking and Hierarchical KV Indexing
Mar 09, 2026The quadratic complexity of the attention mechanism and the substantial memory footprint of the Key-Value (KV) cache present severe computational and memory challenges for Large Language Models (LLMs) processing long contexts. Existing retrieval-based methods often compromise semantic integrity through fixed-size chunking and suffer from inefficient linear scanning. In this paper, we propose LycheeCluster, a novel method for efficient KV cache management. LycheeCluster preserves local semantic coherence via boundary-aware chunking and constructs a recursive hierarchical index rooted in the triangle inequality. This design transforms cache retrieval from a linear scan into a theoretically bounded, logarithmic-time pruning process, while a lazy update strategy supports efficient streaming generation. Experiments demonstrate that LycheeCluster achieves up to a 3.6x end-to-end inference speedup with negligible degradation in model performance, outperforming state-of-the-art KV cache management methods (e.g., Quest, ClusterKV). We will release our code and kernels after publication.
What Makes Value Learning Efficient in Residual Reinforcement Learning?
Feb 11, 2026Residual reinforcement learning (RL) enables stable online refinement of expressive pretrained policies by freezing the base and learning only bounded corrections. However, value learning in residual RL poses unique challenges that remain poorly understood. In this work, we identify two key bottlenecks: cold start pathology, where the critic lacks knowledge of the value landscape around the base policy, and structural scale mismatch, where the residual contribution is dwarfed by the base action. Through systematic investigation, we uncover the mechanisms underlying these bottlenecks, revealing that simple yet principled solutions suffice: base-policy transitions serve as an essential value anchor for implicit warmup, and critic normalization effectively restores representation sensitivity for discerning value differences. Based on these insights, we propose DAWN (Data-Anchored Warmup and Normalization), a minimal approach targeting efficient value learning in residual RL. By addressing these bottlenecks, DAWN demonstrates substantial efficiency gains across diverse benchmarks, policy architectures, and observation modalities.
Targeting Misalignment: A Conflict-Aware Framework for Reward-Model-based LLM Alignment
Dec 10, 2025Reward-model-based fine-tuning is a central paradigm in aligning Large Language Models with human preferences. However, such approaches critically rely on the assumption that proxy reward models accurately reflect intended supervision, a condition often violated due to annotation noise, bias, or limited coverage. This misalignment can lead to undesirable behaviors, where models optimize for flawed signals rather than true human values. In this paper, we investigate a novel framework to identify and mitigate such misalignment by treating the fine-tuning process as a form of knowledge integration. We focus on detecting instances of proxy-policy conflicts, cases where the base model strongly disagrees with the proxy. We argue that such conflicts often signify areas of shared ignorance, where neither the policy nor the reward model possesses sufficient knowledge, making them especially susceptible to misalignment. To this end, we propose two complementary metrics for identifying these conflicts: a localized Proxy-Policy Alignment Conflict Score (PACS) and a global Kendall-Tau Distance measure. Building on this insight, we design an algorithm named Selective Human-in-the-loop Feedback via Conflict-Aware Sampling (SHF-CAS) that targets high-conflict QA pairs for additional feedback, refining both the reward model and policy efficiently. Experiments on two alignment tasks demonstrate that our approach enhances general alignment performance, even when trained with a biased proxy reward. Our work provides a new lens for interpreting alignment failures and offers a principled pathway for targeted refinement in LLM training.
Causal Inspired Multi Modal Recommendation
Oct 14, 2025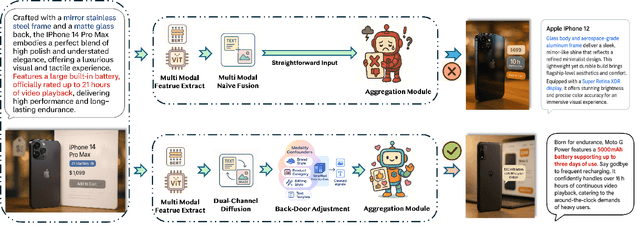
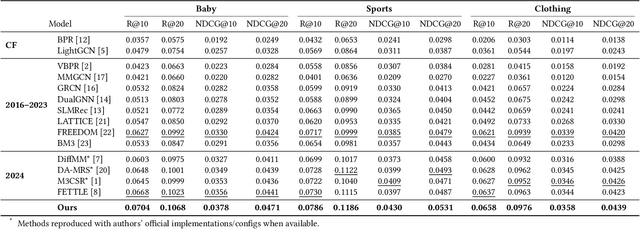
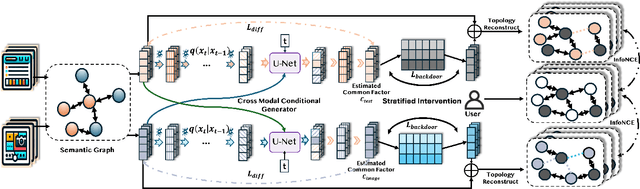
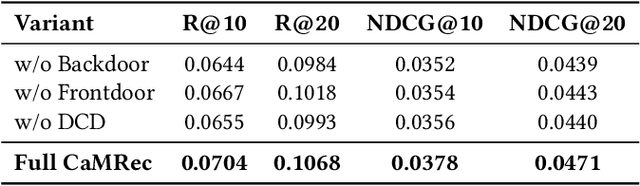
Multimodal recommender systems enhance personalized recommendations in e-commerce and online advertising by integrating visual, textual, and user-item interaction data. However, existing methods often overlook two critical biases: (i) modal confounding, where latent factors (e.g., brand style or product category) simultaneously drive multiple modalities and influence user preference, leading to spurious feature-preference associations; (ii) interaction bias, where genuine user preferences are mixed with noise from exposure effects and accidental clicks. To address these challenges, we propose a Causal-inspired multimodal Recommendation framework. Specifically, we introduce a dual-channel cross-modal diffusion module to identify hidden modal confounders, utilize back-door adjustment with hierarchical matching and vector-quantized codebooks to block confounding paths, and apply front-door adjustment combined with causal topology reconstruction to build a deconfounded causal subgraph. Extensive experiments on three real-world e-commerce datasets demonstrate that our method significantly outperforms state-of-the-art baselines while maintaining strong interpretability.
On the Hardness of Unsupervised Domain Adaptation: Optimal Learners and Information-Theoretic Perspective
Jul 09, 2025



This paper studies the hardness of unsupervised domain adaptation (UDA) under covariate shift. We model the uncertainty that the learner faces by a distribution $\pi$ in the ground-truth triples $(p, q, f)$ -- which we call a UDA class -- where $(p, q)$ is the source -- target distribution pair and $f$ is the classifier. We define the performance of a learner as the overall target domain risk, averaged over the randomness of the ground-truth triple. This formulation couples the source distribution, the target distribution and the classifier in the ground truth, and deviates from the classical worst-case analyses, which pessimistically emphasize the impact of hard but rare UDA instances. In this formulation, we precisely characterize the optimal learner. The performance of the optimal learner then allows us to define the learning difficulty for the UDA class and for the observed sample. To quantify this difficulty, we introduce an information-theoretic quantity -- Posterior Target Label Uncertainty (PTLU) -- along with its empirical estimate (EPTLU) from the sample , which capture the uncertainty in the prediction for the target domain. Briefly, PTLU is the entropy of the predicted label in the target domain under the posterior distribution of ground-truth classifier given the observed source and target samples. By proving that such a quantity serves to lower-bound the risk of any learner, we suggest that these quantities can be used as proxies for evaluating the hardness of UDA learning. We provide several examples to demonstrate the advantage of PTLU, relative to the existing measures, in evaluating the difficulty of UDA learning.
DexSinGrasp: Learning a Unified Policy for Dexterous Object Singulation and Grasping in Cluttered Environments
Apr 06, 2025Grasping objects in cluttered environments remains a fundamental yet challenging problem in robotic manipulation. While prior works have explored learning-based synergies between pushing and grasping for two-fingered grippers, few have leveraged the high degrees of freedom (DoF) in dexterous hands to perform efficient singulation for grasping in cluttered settings. In this work, we introduce DexSinGrasp, a unified policy for dexterous object singulation and grasping. DexSinGrasp enables high-dexterity object singulation to facilitate grasping, significantly improving efficiency and effectiveness in cluttered environments. We incorporate clutter arrangement curriculum learning to enhance success rates and generalization across diverse clutter conditions, while policy distillation enables a deployable vision-based grasping strategy. To evaluate our approach, we introduce a set of cluttered grasping tasks with varying object arrangements and occlusion levels. Experimental results show that our method outperforms baselines in both efficiency and grasping success rate, particularly in dense clutter. Codes, appendix, and videos are available on our project website https://nus-lins-lab.github.io/dexsingweb/.