 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin and Agentic AI for Wild Fire Disaster Management: Intelligent Virtual Situation Room
Feb 09, 2026According to the United Nations, wildfire frequency and intensity are projected to increase by approximately 14% by 2030 and 30% by 2050 due to global warming, posing critical threats to life, infrastructure, and ecosystems. Conventional disaster management frameworks rely on static simulations and passive data acquisition, hindering their ability to adapt to arbitrarily evolving wildfire episodes in real-time. To address these limitations, we introduce the Intelligent Virtual Situation Room (IVSR), a bidirectional Digital Twin (DT) platform augmented by autonomous AI agents. The IVSR continuously ingests multisource sensor imagery, weather data, and 3D forest models to create a live virtual replica of the fire environment. A similarity engine powered by AI aligns emerging conditions with a precomputed Disaster Simulation Library, retrieving and calibrating intervention tactics under the watchful eyes of experts. Authorized action-ranging from UAV redeployment to crew reallocation-is cycled back through standardized procedures to the physical layer, completing the loop between response and analysis. We validate IVSR through detailed case-study simulations provided by an industrial partner, demonstrating capabilities in localized incident detection, privacy-preserving playback, collider-based fire-spread projection, and site-specific ML retraining. Our results indicate marked reductions in detection-to-intervention latency and more effective resource coordination versus traditional systems. By uniting real-time bidirectional DTs with agentic AI, IVSR offers a scalable, semi-automated decision-support paradigm for proactive, adaptive wildfire disaster management.
Targeting Misalignment: A Conflict-Aware Framework for Reward-Model-based LLM Alignment
Dec 10, 2025Reward-model-based fine-tuning is a central paradigm in aligning Large Language Models with human preferences. However, such approaches critically rely on the assumption that proxy reward models accurately reflect intended supervision, a condition often violated due to annotation noise, bias, or limited coverage. This misalignment can lead to undesirable behaviors, where models optimize for flawed signals rather than true human values. In this paper, we investigate a novel framework to identify and mitigate such misalignment by treating the fine-tuning process as a form of knowledge integration. We focus on detecting instances of proxy-policy conflicts, cases where the base model strongly disagrees with the proxy. We argue that such conflicts often signify areas of shared ignorance, where neither the policy nor the reward model possesses sufficient knowledge, making them especially susceptible to misalignment. To this end, we propose two complementary metrics for identifying these conflicts: a localized Proxy-Policy Alignment Conflict Score (PACS) and a global Kendall-Tau Distance measure. Building on this insight, we design an algorithm named Selective Human-in-the-loop Feedback via Conflict-Aware Sampling (SHF-CAS) that targets high-conflict QA pairs for additional feedback, refining both the reward model and policy efficiently. Experiments on two alignment tasks demonstrate that our approach enhances general alignment performance, even when trained with a biased proxy reward. Our work provides a new lens for interpreting alignment failures and offers a principled pathway for targeted refinement in LLM training.
RGB-Th-Bench: A Dense benchmark for Visual-Thermal Understanding of Vision Language Models
Mar 27, 2025We introduce RGB-Th-Bench, the first benchmark designed to evaluate the ability of Vision-Language Models (VLMs) to comprehend RGB-Thermal image pairs. While VLMs have demonstrated remarkable progress in visual reasoning and multimodal understanding, their evaluation has been predominantly limited to RGB-based benchmarks, leaving a critical gap in assessing their capabilities in infrared vision tasks. Existing visible-infrared datasets are either task-specific or lack high-quality annotations necessary for rigorous model evaluation. To address these limitations, RGB-Th-Bench provides a comprehensive evaluation framework covering 14 distinct skill dimensions, with a total of 1,600+ expert-annotated Yes/No questions. The benchmark employs two accuracy metrics: a standard question-level accuracy and a stricter skill-level accuracy, which evaluates model robustness across multiple questions within each skill dimension. This design ensures a thorough assessment of model performance, including resilience to adversarial and hallucinated responses. We conduct extensive evaluations on 19 state-of-the-art VLMs, revealing significant performance gaps in RGB-Thermal understanding. Our results show that even the strongest models struggle with thermal image comprehension, with performance heavily constrained by their RGB-based capabilities. Additionally, the lack of large-scale application-specific and expert-annotated thermal-caption-pair datasets in pre-training is an important reason of the observed performance gap. RGB-Th-Bench highlights the urgent need for further advancements in multimodal learning to bridge the gap between visible and thermal image understanding. The dataset is available through this link, and the evaluation code will also be made publicly available.
Synthetic imagery for fuzzy object detection: A comparative study
Oct 01, 2024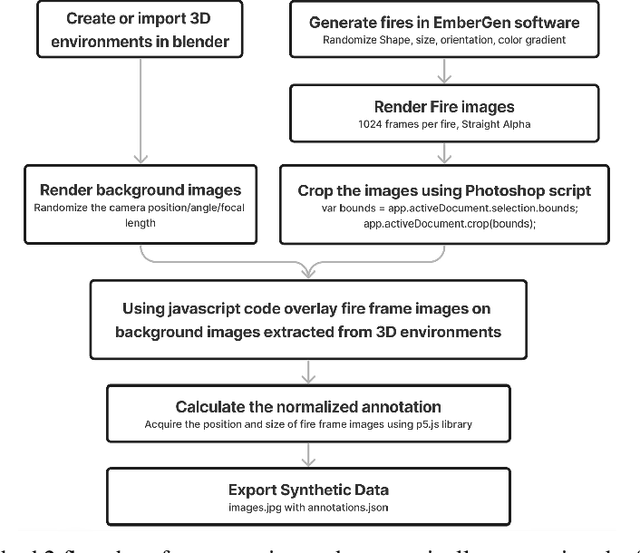

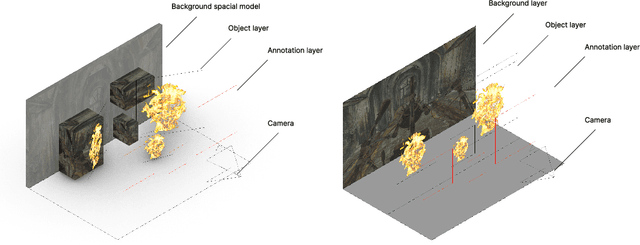
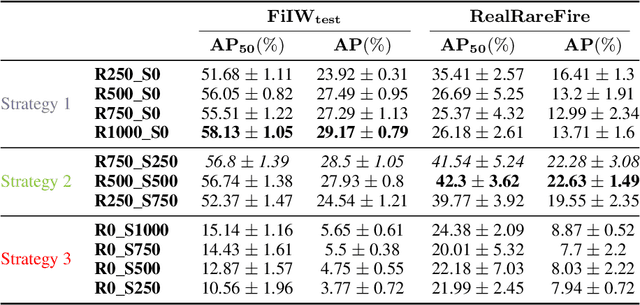
The fuzzy object detection is a challenging field of research in computer vision (CV). Distinguishing between fuzzy and non-fuzzy object detection in CV is important. Fuzzy objects such as fire, smoke, mist, and steam present significantly greater complexities in terms of visual features, blurred edges, varying shapes, opacity, and volume compared to non-fuzzy objects such as trees and cars. Collection of a balanced and diverse dataset and accurate annotation is crucial to achieve better ML models for fuzzy objects, however, the task of collection and annotation is still highly manual. In this research, we propose and leverage an alternative method of generating and automatically annotating fully synthetic fire images based on 3D models for training an object detection model. Moreover, the performance, and efficiency of the trained ML models on synthetic images is compared with ML models trained on real imagery and mixed imagery. Findings proved the effectiveness of the synthetic data for fire detection, while the performance improves as the test dataset covers a broader spectrum of real fires. Our findings illustrates that when synthetic imagery and real imagery is utilized in a mixed training set the resulting ML model outperforms models trained on real imagery as well as models trained on synthetic imagery for detection of a broad spectrum of fires. The proposed method for automating the annotation of synthetic fuzzy objects imagery carries substantial implications for reducing both time and cost in creating computer vision models specifically tailored for detecting fuzzy objects.