 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSET: Swapping-Sliding Explanation for Time Series Classifiers in Affect Detection
Oct 16, 2024

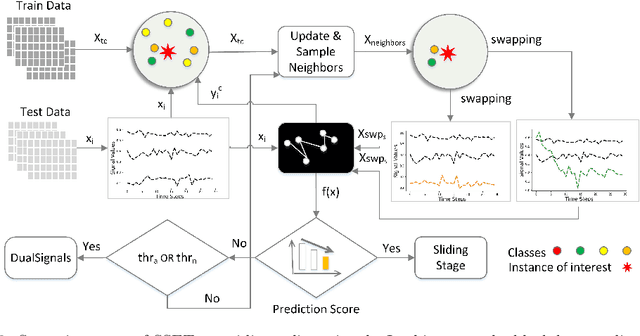
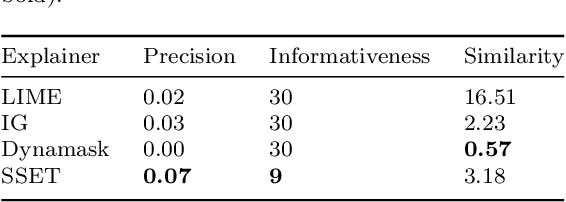
Local explanation of machine learning (ML) models has recently received significant attention due to its ability to reduce ambiguities about why the models make specific decisions. Extensive efforts have been invested to address explainability for different data types, particularly images. However, the work on multivariate time series data is limited. A possible reason is that the conflation of time and other variables in time series data can cause the generated explanations to be incomprehensible to humans. In addition, some efforts on time series fall short of providing accurate explanations as they either ignore a context in the time domain or impose differentiability requirements on the ML models. Such restrictions impede their ability to provide valid explanations in real-world applications and non-differentiable ML settings. In this paper, we propose a swapping--sliding decision explanation for multivariate time series classifiers, called SSET. The proposal consists of swapping and sliding stages, by which salient sub-sequences causing significant drops in the prediction score are presented as explanations. In the former stage, the important variables are detected by swapping the series of interest with close train data from target classes. In the latter stage, the salient observations of these variables are explored by sliding a window over each time step. Additionally, the model measures the importance of different variables over time in a novel way characterized by multiple factors. We leverage SSET on affect detection domain where evaluations are performed on two real-world physiological time series datasets, WESAD and MAHNOB-HCI, and a deep convolutional classifier, CN-Waterfall. This classifier has shown superior performance to prior models to detect human affective states. Comparing SSET with several benchmarks, including LIME, integrated gradients, and Dynamask, we found..
Synthetic imagery for fuzzy object detection: A comparative study
Oct 01, 2024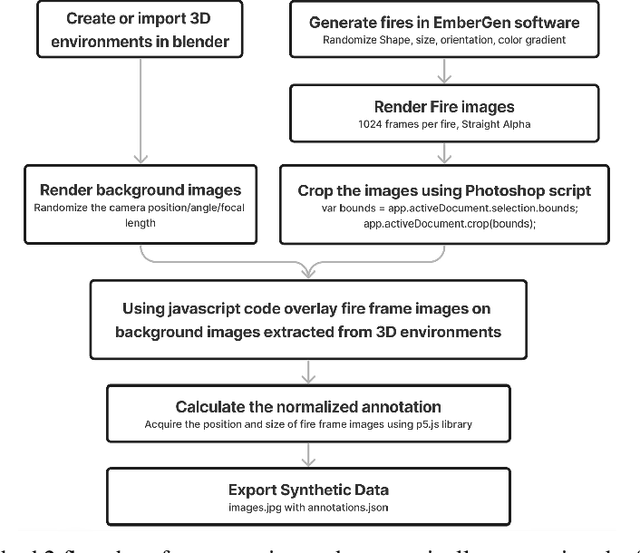

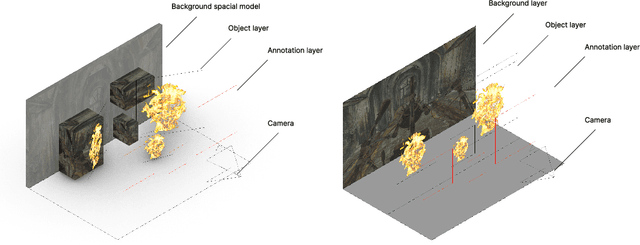
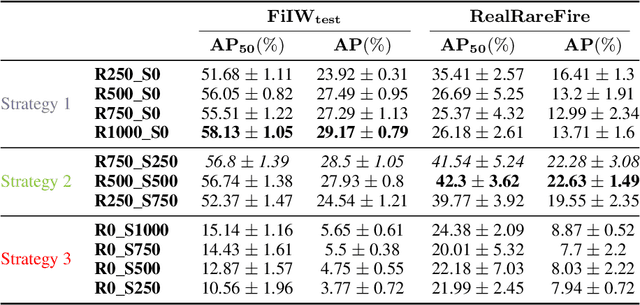
The fuzzy object detection is a challenging field of research in computer vision (CV). Distinguishing between fuzzy and non-fuzzy object detection in CV is important. Fuzzy objects such as fire, smoke, mist, and steam present significantly greater complexities in terms of visual features, blurred edges, varying shapes, opacity, and volume compared to non-fuzzy objects such as trees and cars. Collection of a balanced and diverse dataset and accurate annotation is crucial to achieve better ML models for fuzzy objects, however, the task of collection and annotation is still highly manual. In this research, we propose and leverage an alternative method of generating and automatically annotating fully synthetic fire images based on 3D models for training an object detection model. Moreover, the performance, and efficiency of the trained ML models on synthetic images is compared with ML models trained on real imagery and mixed imagery. Findings proved the effectiveness of the synthetic data for fire detection, while the performance improves as the test dataset covers a broader spectrum of real fires. Our findings illustrates that when synthetic imagery and real imagery is utilized in a mixed training set the resulting ML model outperforms models trained on real imagery as well as models trained on synthetic imagery for detection of a broad spectrum of fires. The proposed method for automating the annotation of synthetic fuzzy objects imagery carries substantial implications for reducing both time and cost in creating computer vision models specifically tailored for detecting fuzzy objects.
Smooth-edged Perturbations Improve Perturbation-based Image Explanations
Sep 06, 2024Perturbation-based post-hoc image explanation methods are commonly used to explain image prediction models by perturbing parts of the input to measure how those parts affect the output. Due to the intractability of perturbing each pixel individually, images are typically attributed to larger segments. The Randomized Input Sampling for Explanations (RISE) method solved this issue by using smooth perturbation masks. While this method has proven effective and popular, it has not been investigated which parts of the method are responsible for its success. This work tests many combinations of mask sampling, segmentation techniques, smoothing, and attribution calculation. The results show that the RISE-style pixel attribution is beneficial to all evaluated methods. Furthermore, it is shown that attribution calculation is the least impactful parameter. The implementation of this work is available online: https://github.com/guspih/post-hoc-image-perturbation.
Contextual Importance and Utility in Python: New Functionality and Insights with the py-ciu Package
Aug 19, 2024The availability of easy-to-use and reliable software implementations is important for allowing researchers in academia and industry to test, assess and take into use eXplainable AI (XAI) methods. This paper describes the \texttt{py-ciu} Python implementation of the Contextual Importance and Utility (CIU) model-agnostic, post-hoc explanation method and illustrates capabilities of CIU that go beyond the current state-of-the-art that could be useful for XAI practitioners in general.
Feature Importance versus Feature Influence and What It Signifies for Explainable AI
Aug 07, 2023



When used in the context of decision theory, feature importance expresses how much changing the value of a feature can change the model outcome (or the utility of the outcome), compared to other features. Feature importance should not be confused with the feature influence used by most state-of-the-art post-hoc Explainable AI methods. Contrary to feature importance, feature influence is measured against a reference level or baseline. The Contextual Importance and Utility (CIU) method provides a unified definition of global and local feature importance that is applicable also for post-hoc explanations, where the value utility concept provides instance-level assessment of how favorable or not a feature value is for the outcome. The paper shows how CIU can be applied to both global and local explainability, assesses the fidelity and stability of different methods, and shows how explanations that use contextual importance and contextual utility can provide more expressive and flexible explanations than when using influence only.
Context, Utility and Influence of an Explanation
Mar 22, 2023Contextual utility theory integrates context-sensitive factors into utility-based decision-making models. It stresses the importance of understanding individual decision-makers' preferences, values, and beliefs and the situational factors that affect them. Contextual utility theory benefits explainable AI. First, it can improve transparency and understanding of how AI systems affect decision-making. It can reveal AI model biases and limitations by considering personal preferences and context. Second, contextual utility theory can make AI systems more personalized and adaptable to users and stakeholders. AI systems can better meet user needs and values by incorporating demographic and cultural data. Finally, contextual utility theory promotes ethical AI development and social responsibility. AI developers can create ethical systems that benefit society by considering contextual factors like societal norms and values. This work, demonstrates how contextual utility theory can improve AI system transparency, personalization, and ethics, benefiting both users and developers.
Do intermediate feature coalitions aid explainability of black-box models?
Mar 21, 2023
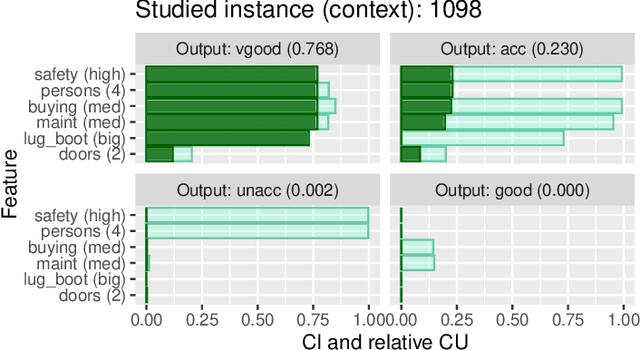

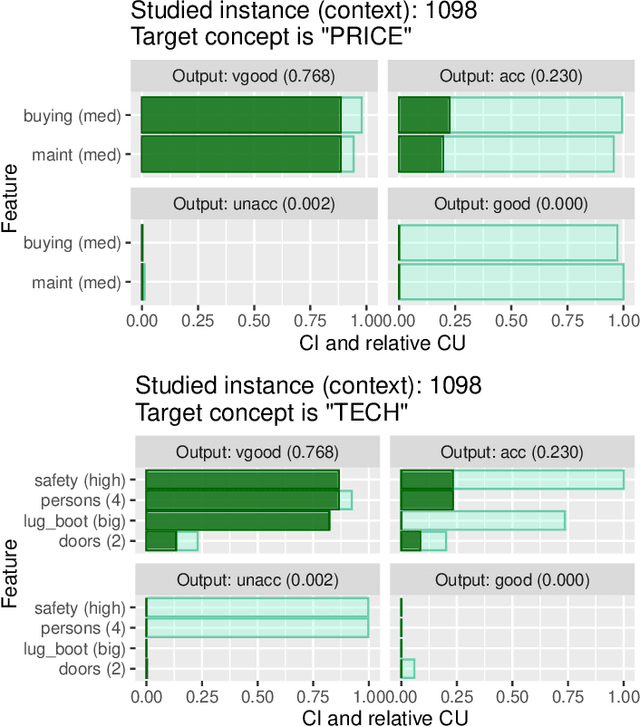
This work introduces the notion of intermediate concepts based on levels structure to aid explainability for black-box models. The levels structure is a hierarchical structure in which each level corresponds to features of a dataset (i.e., a player-set partition). The level of coarseness increases from the trivial set, which only comprises singletons, to the set, which only contains the grand coalition. In addition, it is possible to establish meronomies, i.e., part-whole relationships, via a domain expert that can be utilised to generate explanations at an abstract level. We illustrate the usability of this approach in a real-world car model example and the Titanic dataset, where intermediate concepts aid in explainability at different levels of abstraction.
Contextual Importance and Utility: aTheoretical Foundation
Feb 15, 2022This paper provides new theory to support to the eXplainable AI (XAI) method Contextual Importance and Utility (CIU). CIU arithmetic is based on the concepts of Multi-Attribute Utility Theory, which gives CIU a solid theoretical foundation. The novel concept of contextual influence is also defined, which makes it possible to compare CIU directly with so-called additive feature attribution (AFA) methods for model-agnostic outcome explanation. One key takeaway is that the "influence" concept used by AFA methods is inadequate for outcome explanation purposes even for simple models to explain. Experiments with simple models show that explanations using contextual importance (CI) and contextual utility (CU) produce explanations where influence-based methods fail. It is also shown that CI and CU guarantees explanation faithfulness towards the explained model.
Comparing seven methods for state-of-health time series prediction for the lithium-ion battery packs of forklifts
Jul 06, 2021
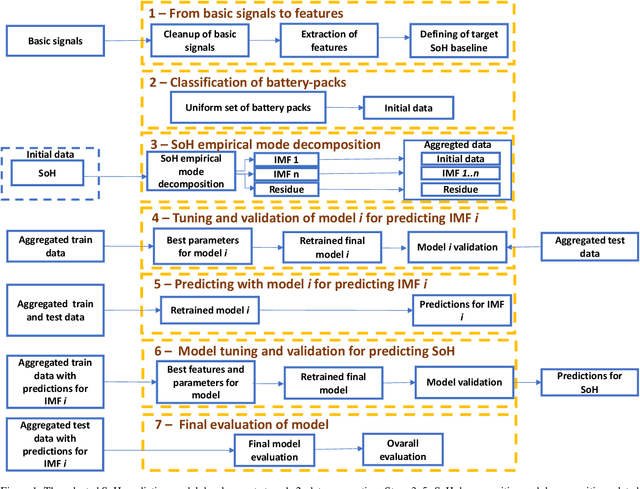


A key aspect for the forklifts is the state-of-health (SoH) assessment to ensure the safety and the reliability of uninterrupted power source. Forecasting the battery SoH well is imperative to enable preventive maintenance and hence to reduce the costs. This paper demonstrates the capabilities of gradient boosting regression for predicting the SoH timeseries under circumstances when there is little prior information available about the batteries. We compared the gradient boosting method with light gradient boosting, extra trees, extreme gradient boosting, random forests, long short-term memory networks and with combined convolutional neural network and long short-term memory networks methods. We used multiple predictors and lagged target signal decomposition results as additional predictors and compared the yielded prediction results with different sets of predictors for each method. For this work, we are in possession of a unique data set of 45 lithium-ion battery packs with large variation in the data. The best model that we derived was validated by a novel walk-forward algorithm that also calculates point-wise confidence intervals for the predictions; we yielded reasonable predictions and confidence intervals for the predictions. Furthermore, we verified this model against five other lithium-ion battery packs; the best model generalised to greater extent to this set of battery packs. The results about the final model suggest that we were able to enhance the results in respect to previously developed models. Moreover, we further validated the model for extracting cycle counts presented in our previous work with data from new forklifts; their battery packs completed around 3000 cycles in a 10-year service period, which corresponds to the cycle life for commercial Nickel-Cobalt-Manganese (NMC) cells.
* 16 pages, 10 figures and 10 tables
Explainable Artificial Intelligence for Human Decision-Support System in Medical Domain
May 05, 2021



In the present paper we present the potential of Explainable Artificial Intelligence methods for decision-support in medical image analysis scenarios. With three types of explainable methods applied to the same medical image data set our aim was to improve the comprehensibility of the decisions provided by the Convolutional Neural Network (CNN). The visual explanations were provided on in-vivo gastral images obtained from a Video capsule endoscopy (VCE), with the goal of increasing the health professionals' trust in the black box predictions. We implemented two post-hoc interpretable machine learning methods LIME and SHAP and the alternative explanation approach CIU, centered on the Contextual Value and Utility (CIU). The produced explanations were evaluated using human evaluation. We conducted three user studies based on the explanations provided by LIME, SHAP and CIU. Users from different non-medical backgrounds carried out a series of tests in the web-based survey setting and stated their experience and understanding of the given explanations. Three user groups (n=20, 20, 20) with three distinct forms of explanations were quantitatively analyzed. We have found that, as hypothesized, the CIU explainable method performed better than both LIME and SHAP methods in terms of increasing support for human decision-making as well as being more transparent and thus understandable to users. Additionally, CIU outperformed LIME and SHAP by generating explanations more rapidly. Our findings suggest that there are notable differences in human decision-making between various explanation support settings. In line with that, we present three potential explainable methods that can with future improvements in implementation be generalized on different medical data sets and can provide great decision-support for medical experts.