 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Alignment as Variational Expectation-Maximization
Oct 01, 2025Diffusion alignment aims to optimize diffusion models for the downstream objective. While existing methods based on reinforcement learning or direct backpropagation achieve considerable success in maximizing rewards, they often suffer from reward over-optimization and mode collapse. We introduce Diffusion Alignment as Variational Expectation-Maximization (DAV), a framework that formulates diffusion alignment as an iterative process alternating between two complementary phases: the E-step and the M-step. In the E-step, we employ test-time search to generate diverse and reward-aligned samples. In the M-step, we refine the diffusion model using samples discovered by the E-step. We demonstrate that DAV can optimize reward while preserving diversity for both continuous and discrete tasks: text-to-image synthesis and DNA sequence design.
Active Attacks: Red-teaming LLMs via Adaptive Environments
Sep 26, 2025



We address the challenge of generating diverse attack prompts for large language models (LLMs) that elicit harmful behaviors (e.g., insults, sexual content) and are used for safety fine-tuning. Rather than relying on manual prompt engineering, attacker LLMs can be trained with reinforcement learning (RL) to automatically generate such prompts using only a toxicity classifier as a reward. However, capturing a wide range of harmful behaviors is a significant challenge that requires explicit diversity objectives. Existing diversity-seeking RL methods often collapse to limited modes: once high-reward prompts are found, exploration of new regions is discouraged. Inspired by the active learning paradigm that encourages adaptive exploration, we introduce \textit{Active Attacks}, a novel RL-based red-teaming algorithm that adapts its attacks as the victim evolves. By periodically safety fine-tuning the victim LLM with collected attack prompts, rewards in exploited regions diminish, which forces the attacker to seek unexplored vulnerabilities. This process naturally induces an easy-to-hard exploration curriculum, where the attacker progresses beyond easy modes toward increasingly difficult ones. As a result, Active Attacks uncovers a wide range of local attack modes step by step, and their combination achieves wide coverage of the multi-mode distribution. Active Attacks, a simple plug-and-play module that seamlessly integrates into existing RL objectives, unexpectedly outperformed prior RL-based methods -- including GFlowNets, PPO, and REINFORCE -- by improving cross-attack success rates against GFlowNets, the previous state-of-the-art, from 0.07% to 31.28% (a relative gain greater than $400\ \times$) with only a 6% increase in computation. Our code is publicly available \href{https://github.com/dbsxodud-11/active_attacks}{here}.
Offline Model-Based Optimization: Comprehensive Review
Mar 21, 2025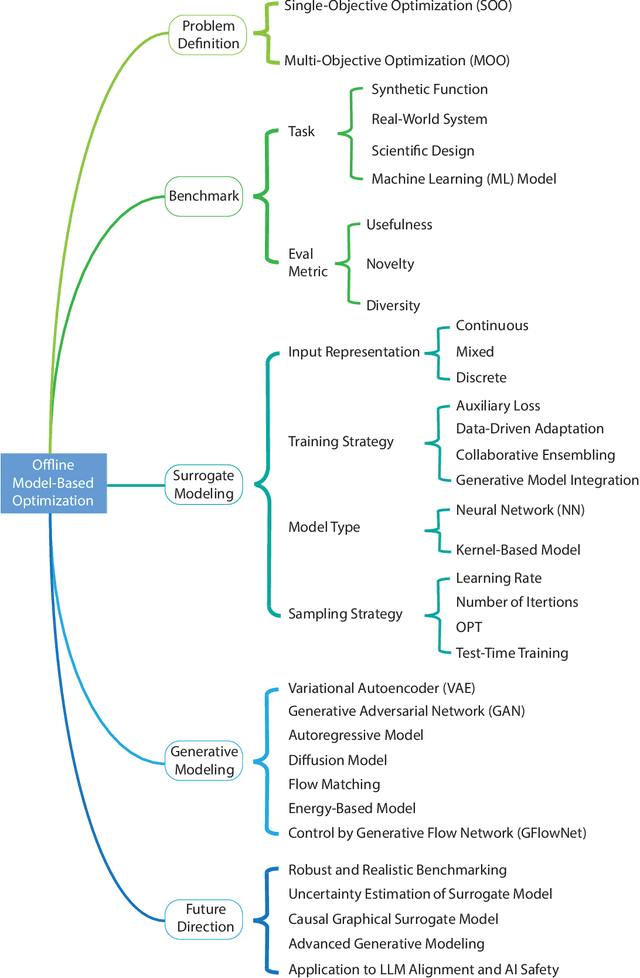
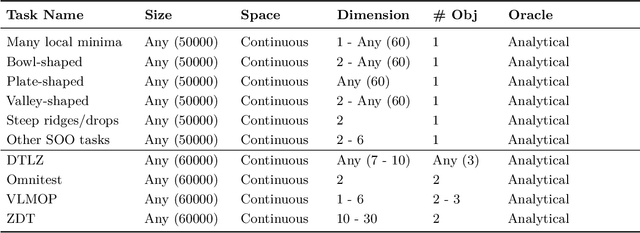

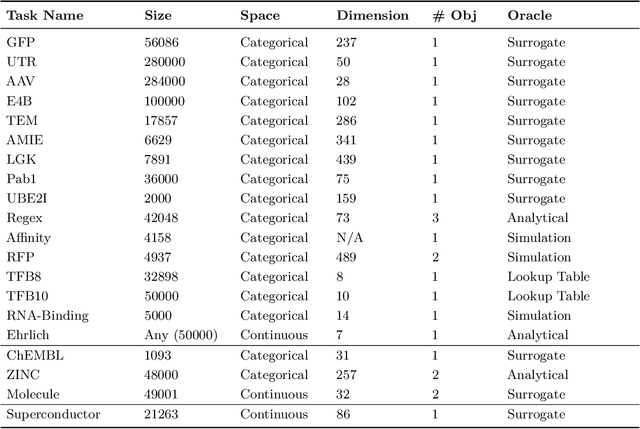
Offline optimization is a fundamental challenge in science and engineering, where the goal is to optimize black-box functions using only offline datasets. This setting is particularly relevant when querying the objective function is prohibitively expensive or infeasible, with applications spanning protein engineering, material discovery, neural architecture search, and beyond. The main difficulty lies in accurately estimating the objective landscape beyond the available data, where extrapolations are fraught with significant epistemic uncertainty. This uncertainty can lead to objective hacking(reward hacking), exploiting model inaccuracies in unseen regions, or other spurious optimizations that yield misleadingly high performance estimates outside the training distribution. Recent advances in model-based optimization(MBO) have harnessed the generalization capabilities of deep neural networks to develop offline-specific surrogate and generative models. Trained with carefully designed strategies, these models are more robust against out-of-distribution issues, facilitating the discovery of improved designs. Despite its growing impact in accelerating scientific discovery, the field lacks a comprehensive review. To bridge this gap, we present the first thorough review of offline MBO. We begin by formalizing the problem for both single-objective and multi-objective settings and by reviewing recent benchmarks and evaluation metrics. We then categorize existing approaches into two key areas: surrogate modeling, which emphasizes accurate function approximation in out-of-distribution regions, and generative modeling, which explores high-dimensional design spaces to identify high-performing designs. Finally, we examine the key challenges and propose promising directions for advancement in this rapidly evolving field including safe control of superintelligent systems.
Posterior Inference with Diffusion Models for High-dimensional Black-box Optimization
Feb 24, 2025Optimizing high-dimensional and complex black-box functions is crucial in numerous scientific applications. While Bayesian optimization (BO) is a powerful method for sample-efficient optimization, it struggles with the curse of dimensionality and scaling to thousands of evaluations. Recently, leveraging generative models to solve black-box optimization problems has emerged as a promising framework. However, those methods often underperform compared to BO methods due to limited expressivity and difficulty of uncertainty estimation in high-dimensional spaces. To overcome these issues, we introduce \textbf{DiBO}, a novel framework for solving high-dimensional black-box optimization problems. Our method iterates two stages. First, we train a diffusion model to capture the data distribution and an ensemble of proxies to predict function values with uncertainty quantification. Second, we cast the candidate selection as a posterior inference problem to balance exploration and exploitation in high-dimensional spaces. Concretely, we fine-tune diffusion models to amortize posterior inference. Extensive experiments demonstrate that our method outperforms state-of-the-art baselines across various synthetic and real-world black-box optimization tasks. Our code is publicly available \href{https://github.com/umkiyoung/DiBO}{here}
Learning to Sample Effective and Diverse Prompts for Text-to-Image Generation
Feb 17, 2025Recent advances in text-to-image diffusion models have achieved impressive image generation capabilities. However, it remains challenging to control the generation process with desired properties (e.g., aesthetic quality, user intention), which can be expressed as black-box reward functions. In this paper, we focus on prompt adaptation, which refines the original prompt into model-preferred prompts to generate desired images. While prior work uses reinforcement learning (RL) to optimize prompts, we observe that applying RL often results in generating similar postfixes and deterministic behaviors. To this end, we introduce \textbf{P}rompt \textbf{A}daptation with \textbf{G}FlowNets (\textbf{PAG}), a novel approach that frames prompt adaptation as a probabilistic inference problem. Our key insight is that leveraging Generative Flow Networks (GFlowNets) allows us to shift from reward maximization to sampling from an unnormalized density function, enabling both high-quality and diverse prompt generation. However, we identify that a naive application of GFlowNets suffers from mode collapse and uncovers a previously overlooked phenomenon: the progressive loss of neural plasticity in the model, which is compounded by inefficient credit assignment in sequential prompt generation. To address this critical challenge, we develop a systematic approach in PAG with flow reactivation, reward-prioritized sampling, and reward decomposition for prompt adaptation. Extensive experiments validate that PAG successfully learns to sample effective and diverse prompts for text-to-image generation. We also show that PAG exhibits strong robustness across various reward functions and transferability to different text-to-image models.
Improved Off-policy Reinforcement Learning in Biological Sequence Design
Oct 06, 2024
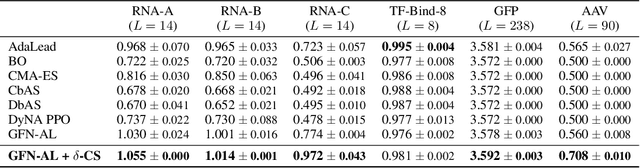
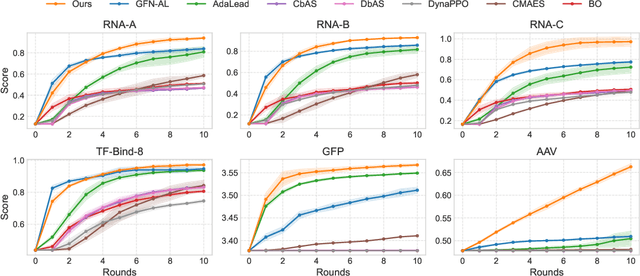
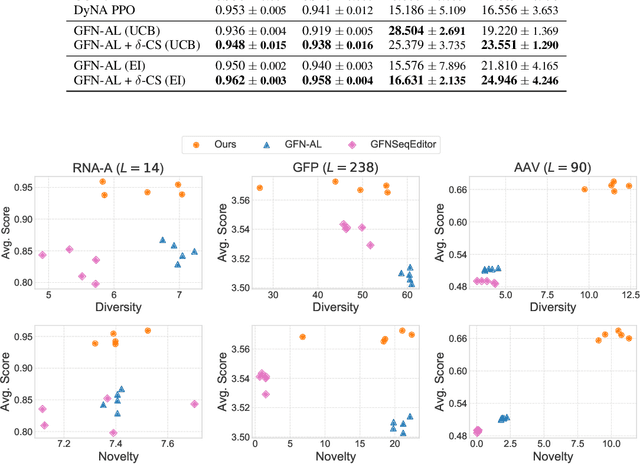
Designing biological sequences with desired properties is a significant challenge due to the combinatorially vast search space and the high cost of evaluating each candidate sequence. To address these challenges, reinforcement learning (RL) methods, such as GFlowNets, utilize proxy models for rapid reward evaluation and annotated data for policy training. Although these approaches have shown promise in generating diverse and novel sequences, the limited training data relative to the vast search space often leads to the misspecification of proxy for out-of-distribution inputs. We introduce $\delta$-Conservative Search, a novel off-policy search method for training GFlowNets designed to improve robustness against proxy misspecification. The key idea is to incorporate conservativeness, controlled by parameter $\delta$, to constrain the search to reliable regions. Specifically, we inject noise into high-score offline sequences by randomly masking tokens with a Bernoulli distribution of parameter $\delta$ and then denoise masked tokens using the GFlowNet policy. Additionally, $\delta$ is adaptively adjusted based on the uncertainty of the proxy model for each data point. This enables the reflection of proxy uncertainty to determine the level of conservativeness. Experimental results demonstrate that our method consistently outperforms existing machine learning methods in discovering high-score sequences across diverse tasks-including DNA, RNA, protein, and peptide design-especially in large-scale scenarios.
Adaptive teachers for amortized samplers
Oct 02, 2024



Amortized inference is the task of training a parametric model, such as a neural network, to approximate a distribution with a given unnormalized density where exact sampling is intractable. When sampling is implemented as a sequential decision-making process, reinforcement learning (RL) methods, such as generative flow networks, can be used to train the sampling policy. Off-policy RL training facilitates the discovery of diverse, high-reward candidates, but existing methods still face challenges in efficient exploration. We propose to use an adaptive training distribution (the Teacher) to guide the training of the primary amortized sampler (the Student) by prioritizing high-loss regions. The Teacher, an auxiliary behavior model, is trained to sample high-error regions of the Student and can generalize across unexplored modes, thereby enhancing mode coverage by providing an efficient training curriculum. We validate the effectiveness of this approach in a synthetic environment designed to present an exploration challenge, two diffusion-based sampling tasks, and four biochemical discovery tasks demonstrating its ability to improve sample efficiency and mode coverage.
An Offline Meta Black-box Optimization Framework for Adaptive Design of Urban Traffic Light Management Systems
Aug 14, 2024Complex urban road networks with high vehicle occupancy frequently face severe traffic congestion. Designing an effective strategy for managing multiple traffic lights plays a crucial role in managing congestion. However, most current traffic light management systems rely on human-crafted decisions, which may not adapt well to diverse traffic patterns. In this paper, we delve into two pivotal design components of the traffic light management system that can be dynamically adjusted to various traffic conditions: phase combination and phase time allocation. While numerous studies have sought an efficient strategy for managing traffic lights, most of these approaches consider a fixed traffic pattern and are limited to relatively small road networks. To overcome these limitations, we introduce a novel and practical framework to formulate the optimization of such design components using an offline meta black-box optimization. We then present a simple yet effective method to efficiently find a solution for the aforementioned problem. In our framework, we first collect an offline meta dataset consisting of pairs of design choices and corresponding congestion measures from various traffic patterns. After collecting the dataset, we employ the Attentive Neural Process (ANP) to predict the impact of the proposed design on congestion across various traffic patterns with well-calibrated uncertainty. Finally, Bayesian optimization, with ANP as a surrogate model, is utilized to find an optimal design for unseen traffic patterns through limited online simulations. Our experiment results show that our method outperforms state-of-the-art baselines on complex road networks in terms of the number of waiting vehicles. Surprisingly, the deployment of our method into a real-world traffic system was able to improve traffic throughput by 4.80\% compared to the original strategy.
Guided Trajectory Generation with Diffusion Models for Offline Model-based Optimization
Jun 29, 2024Optimizing complex and high-dimensional black-box functions is ubiquitous in science and engineering fields. Unfortunately, the online evaluation of these functions is restricted due to time and safety constraints in most cases. In offline model-based optimization (MBO), we aim to find a design that maximizes the target function using only a pre-existing offline dataset. While prior methods consider forward or inverse approaches to address the problem, these approaches are limited by conservatism and the difficulty of learning highly multi-modal mappings. Recently, there has been an emerging paradigm of learning to improve solutions with synthetic trajectories constructed from the offline dataset. In this paper, we introduce a novel conditional generative modeling approach to produce trajectories toward high-scoring regions. First, we construct synthetic trajectories toward high-scoring regions using the dataset while injecting locality bias for consistent improvement directions. Then, we train a conditional diffusion model to generate trajectories conditioned on their scores. Lastly, we sample multiple trajectories from the trained model with guidance to explore high-scoring regions beyond the dataset and select high-fidelity designs among generated trajectories with the proxy function. Extensive experiment results demonstrate that our method outperforms competitive baselines on Design-Bench and its practical variants. The code is publicly available in \texttt{https://github.com/dbsxodud-11/GTG}.
GTA: Generative Trajectory Augmentation with Guidance for Offline Reinforcement Learning
May 28, 2024Offline Reinforcement Learning (Offline RL) presents challenges of learning effective decision-making policies from static datasets without any online interactions. Data augmentation techniques, such as noise injection and data synthesizing, aim to improve Q-function approximation by smoothing the learned state-action region. However, these methods often fall short of directly improving the quality of offline datasets, leading to suboptimal results. In response, we introduce \textbf{GTA}, Generative Trajectory Augmentation, a novel generative data augmentation approach designed to enrich offline data by augmenting trajectories to be both high-rewarding and dynamically plausible. GTA applies a diffusion model within the data augmentation framework. GTA partially noises original trajectories and then denoises them with classifier-free guidance via conditioning on amplified return value. Our results show that GTA, as a general data augmentation strategy, enhances the performance of widely used offline RL algorithms in both dense and sparse reward settings. Furthermore, we conduct a quality analysis of data augmented by GTA and demonstrate that GTA improves the quality of the data. Our code is available at https://github.com/Jaewoopudding/GTA