 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Classification for Confidential Documents
Apr 09, 2026Unauthorized disclosure of confidential documents demands robust, low-leakage classification. In real work environments, there is a lot of inflow and outflow of documents. To continuously update knowledge, we propose a methodology for classifying confidential documents using Retrieval Augmented Classification (RAC). To confirm this effectiveness, we compare RAC and supervised fine tuning (FT) on the WikiLeaks US Diplomacy corpus under realistic sequence-length constraints. On balanced data, RAC matches FT. On unbalanced data, RAC is more stable while delivering comparable performance--about 96% Accuracy on both the original (unbalanced) and augmented (balanced) sets, and up to 94% F1 with proper prompting--whereas FT attains 90% F1 trained on the augmented, balanced set but drops to 88% F1 trained on the original, unbalanced set. When robust augmentation is infeasible, RAC provides a practical, security-preserving path to strong classification by keeping sensitive content out of model weights and under your control, and it remains robust as real-world conditions change in class balance, data, context length, or governance requirements. Because RAC grounds decisions in an external vector store with similarity matching, it is less sensitive to label skew, reduces parameter-level leakage, and can incorporate new data immediately via reindexing--a difficult step for FT, which typically requires retraining. The contributions of this paper are threefold: first, a RAC-based classification pipeline and evaluation recipe; second, a controlled study that isolates class imbalance and context-length effects for FT versus RAC in confidential-document grading; and third, actionable guidance on RAC design patterns for governed deployments.
* Appears in: KSII The 17th International Conference on Internet (ICONI) 2025, Dec 2025. 7 pages (48-54)
Adaptive Replay Buffer for Offline-to-Online Reinforcement Learning
Dec 11, 2025Offline-to-Online Reinforcement Learning (O2O RL) faces a critical dilemma in balancing the use of a fixed offline dataset with newly collected online experiences. Standard methods, often relying on a fixed data-mixing ratio, struggle to manage the trade-off between early learning stability and asymptotic performance. To overcome this, we introduce the Adaptive Replay Buffer (ARB), a novel approach that dynamically prioritizes data sampling based on a lightweight metric we call 'on-policyness'. Unlike prior methods that rely on complex learning procedures or fixed ratios, ARB is designed to be learning-free and simple to implement, seamlessly integrating into existing O2O RL algorithms. It assesses how closely collected trajectories align with the current policy's behavior and assigns a proportional sampling weight to each transition within that trajectory. This strategy effectively leverages offline data for initial stability while progressively focusing learning on the most relevant, high-rewarding online experiences. Our extensive experiments on D4RL benchmarks demonstrate that ARB consistently mitigates early performance degradation and significantly improves the final performance of various O2O RL algorithms, highlighting the importance of an adaptive, behavior-aware replay buffer design.
Low-Rank Curvature for Zeroth-Order Optimization in LLM Fine-Tuning
Nov 11, 2025We introduce LOREN, a curvature-aware zeroth-order (ZO) optimization method for fine-tuning large language models (LLMs). Existing ZO methods, which estimate gradients via finite differences using random perturbations, often suffer from high variance and suboptimal search directions. Our approach addresses these challenges by: (i) reformulating the problem of gradient preconditioning as that of adaptively estimating an anisotropic perturbation distribution for gradient estimation, (ii) capturing curvature through a low-rank block diagonal preconditioner using the framework of natural evolution strategies, and (iii) applying a REINFORCE leave-one-out (RLOO) gradient estimator to reduce variance. Experiments on standard LLM benchmarks show that our method outperforms state-of-the-art ZO methods by achieving higher accuracy and faster convergence, while cutting peak memory usage by up to 27.3% compared with MeZO-Adam.
Geometric Backstepping Control of Omnidirectional Tiltrotors Incorporating Servo-Rotor Dynamics for Robustness against Sudden Disturbances
Oct 02, 2025This work presents a geometric backstepping controller for a variable-tilt omnidirectional multirotor that explicitly accounts for both servo and rotor dynamics. Considering actuator dynamics is essential for more effective and reliable operation, particularly during aggressive flight maneuvers or recovery from sudden disturbances. While prior studies have investigated actuator-aware control for conventional and fixed-tilt multirotors, these approaches rely on linear relationships between actuator input and wrench, which cannot capture the nonlinearities induced by variable tilt angles. In this work, we exploit the cascade structure between the rigid-body dynamics of the multirotor and its nonlinear actuator dynamics to design the proposed backstepping controller and establish exponential stability of the overall system. Furthermore, we reveal parametric uncertainty in the actuator model through experiments, and we demonstrate that the proposed controller remains robust against such uncertainty. The controller was compared against a baseline that does not account for actuator dynamics across three experimental scenarios: fast translational tracking, rapid rotational tracking, and recovery from sudden disturbance. The proposed method consistently achieved better tracking performance, and notably, while the baseline diverged and crashed during the fastest translational trajectory tracking and the recovery experiment, the proposed controller maintained stability and successfully completed the tasks, thereby demonstrating its effectiveness.
Diffusion Alignment as Variational Expectation-Maximization
Oct 01, 2025Diffusion alignment aims to optimize diffusion models for the downstream objective. While existing methods based on reinforcement learning or direct backpropagation achieve considerable success in maximizing rewards, they often suffer from reward over-optimization and mode collapse. We introduce Diffusion Alignment as Variational Expectation-Maximization (DAV), a framework that formulates diffusion alignment as an iterative process alternating between two complementary phases: the E-step and the M-step. In the E-step, we employ test-time search to generate diverse and reward-aligned samples. In the M-step, we refine the diffusion model using samples discovered by the E-step. We demonstrate that DAV can optimize reward while preserving diversity for both continuous and discrete tasks: text-to-image synthesis and DNA sequence design.
MAC: An Efficient Gradient Preconditioning using Mean Activation Approximated Curvature
Jun 10, 2025Second-order optimization methods for training neural networks, such as KFAC, exhibit superior convergence by utilizing curvature information of loss landscape. However, it comes at the expense of high computational burden. In this work, we analyze the two components that constitute the layer-wise Fisher information matrix (FIM) used in KFAC: the Kronecker factors related to activations and pre-activation gradients. Based on empirical observations on their eigenspectra, we propose efficient approximations for them, resulting in a computationally efficient optimization method called MAC. To the best of our knowledge, MAC is the first algorithm to apply the Kronecker factorization to the FIM of attention layers used in transformers and explicitly integrate attention scores into the preconditioning. We also study the convergence property of MAC on nonlinear neural networks and provide two conditions under which it converges to global minima. Our extensive evaluations on various network architectures and datasets show that the proposed method outperforms KFAC and other state-of-the-art methods in terms of accuracy, end-to-end training time, and memory usage. Code is available at https://github.com/hseung88/mac.
NysAct: A Scalable Preconditioned Gradient Descent using Nystrom Approximation
Jun 10, 2025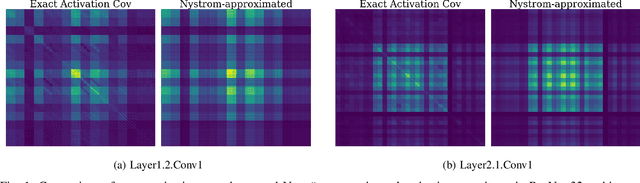
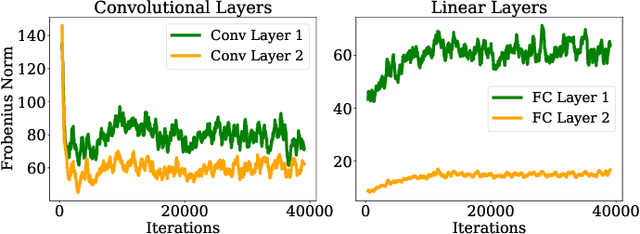
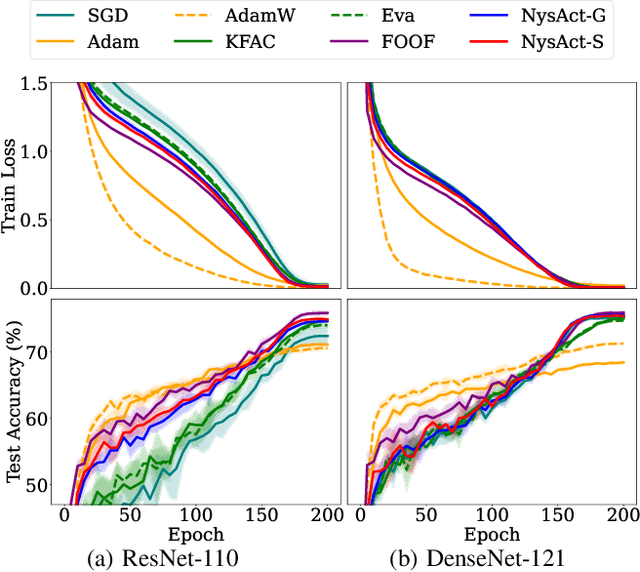
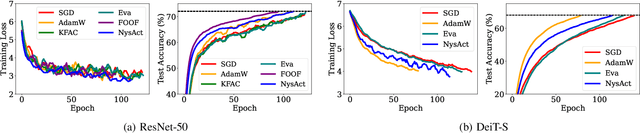
Adaptive gradient methods are computationally efficient and converge quickly, but they often suffer from poor generalization. In contrast, second-order methods enhance convergence and generalization but typically incur high computational and memory costs. In this work, we introduce NysAct, a scalable first-order gradient preconditioning method that strikes a balance between state-of-the-art first-order and second-order optimization methods. NysAct leverages an eigenvalue-shifted Nystrom method to approximate the activation covariance matrix, which is used as a preconditioning matrix, significantly reducing time and memory complexities with minimal impact on test accuracy. Our experiments show that NysAct not only achieves improved test accuracy compared to both first-order and second-order methods but also demands considerably less computational resources than existing second-order methods. Code is available at https://github.com/hseung88/nysact.
An Adaptive Method Stabilizing Activations for Enhanced Generalization
Jun 10, 2025We introduce AdaAct, a novel optimization algorithm that adjusts learning rates according to activation variance. Our method enhances the stability of neuron outputs by incorporating neuron-wise adaptivity during the training process, which subsequently leads to better generalization -- a complementary approach to conventional activation regularization methods. Experimental results demonstrate AdaAct's competitive performance across standard image classification benchmarks. We evaluate AdaAct on CIFAR and ImageNet, comparing it with other state-of-the-art methods. Importantly, AdaAct effectively bridges the gap between the convergence speed of Adam and the strong generalization capabilities of SGD, all while maintaining competitive execution times. Code is available at https://github.com/hseung88/adaact.
TAMP: Token-Adaptive Layerwise Pruning in Multimodal Large Language Models
Apr 15, 2025Multimodal Large Language Models (MLLMs) have shown remarkable versatility in understanding diverse multimodal data and tasks. However, these capabilities come with an increased model scale. While post-training pruning reduces model size in unimodal models, its application to MLLMs often yields limited success. Our analysis discovers that conventional methods fail to account for the unique token attributes across layers and modalities inherent to MLLMs. Inspired by this observation, we propose TAMP, a simple yet effective pruning framework tailored for MLLMs, featuring two key components: (1) Diversity-Aware Sparsity, which adjusts sparsity ratio per layer based on diversities among multimodal output tokens, preserving more parameters in high-diversity layers; and (2) Adaptive Multimodal Input Activation, which identifies representative multimodal input tokens using attention scores to guide unstructured weight pruning. We validate our method on two state-of-the-art MLLMs: LLaVA-NeXT, designed for vision-language tasks, and VideoLLaMA2, capable of processing audio, visual, and language modalities. Empirical experiments across various multimodal evaluation benchmarks demonstrate that each component of our approach substantially outperforms existing pruning techniques.
Posterior Inference with Diffusion Models for High-dimensional Black-box Optimization
Feb 24, 2025Optimizing high-dimensional and complex black-box functions is crucial in numerous scientific applications. While Bayesian optimization (BO) is a powerful method for sample-efficient optimization, it struggles with the curse of dimensionality and scaling to thousands of evaluations. Recently, leveraging generative models to solve black-box optimization problems has emerged as a promising framework. However, those methods often underperform compared to BO methods due to limited expressivity and difficulty of uncertainty estimation in high-dimensional spaces. To overcome these issues, we introduce \textbf{DiBO}, a novel framework for solving high-dimensional black-box optimization problems. Our method iterates two stages. First, we train a diffusion model to capture the data distribution and an ensemble of proxies to predict function values with uncertainty quantification. Second, we cast the candidate selection as a posterior inference problem to balance exploration and exploitation in high-dimensional spaces. Concretely, we fine-tune diffusion models to amortize posterior inference. Extensive experiments demonstrate that our method outperforms state-of-the-art baselines across various synthetic and real-world black-box optimization tasks. Our code is publicly available \href{https://github.com/umkiyoung/DiBO}{here}