 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine-Tuning Needs to Unlock the Potential of Token Priority
Feb 01, 2026The transition from fitting empirical data to achieving true human utility is fundamentally constrained by a granularity mismatch, where fine-grained autoregressive generation is often supervised by coarse or uniform signals. This position paper advocates Token Priority as the essential bridge, formalizing Supervised Fine-Tuning (SFT) not as simple optimization but as a precise distribution reshaping process that aligns raw data with the ideal alignment manifold. We analyze recent breakthroughs through this unified lens, categorizing them into two distinct regimes: Positive Priority for noise filtration and Signed Priority for toxic modes unlearning. We revisit existing progress and limitations, identify key challenges, and suggest directions for future research.
Empowering Reliable Visual-Centric Instruction Following in MLLMs
Jan 06, 2026Evaluating the instruction-following (IF) capabilities of Multimodal Large Language Models (MLLMs) is essential for rigorously assessing how faithfully model outputs adhere to user-specified intentions. Nevertheless, existing benchmarks for evaluating MLLMs' instruction-following capability primarily focus on verbal instructions in the textual modality. These limitations hinder a thorough analysis of instruction-following capabilities, as they overlook the implicit constraints embedded in the semantically rich visual modality. To address this gap, we introduce VC-IFEval, a new benchmark accompanied by a systematically constructed dataset that evaluates MLLMs' instruction-following ability under multimodal settings. Our benchmark systematically incorporates vision-dependent constraints into instruction design, enabling a more rigorous and fine-grained assessment of how well MLLMs align their outputs with both visual input and textual instructions. Furthermore, by fine-tuning MLLMs on our dataset, we achieve substantial gains in visual instruction-following accuracy and adherence. Through extensive evaluation across representative MLLMs, we provide new insights into the strengths and limitations of current models.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025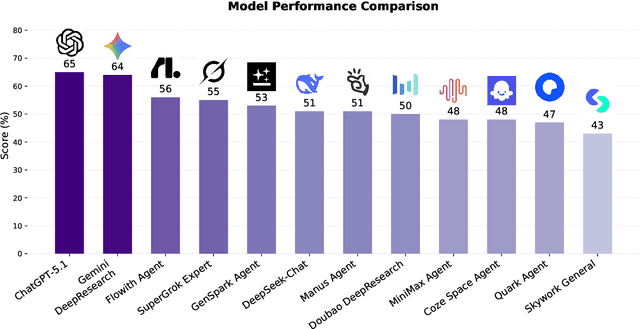
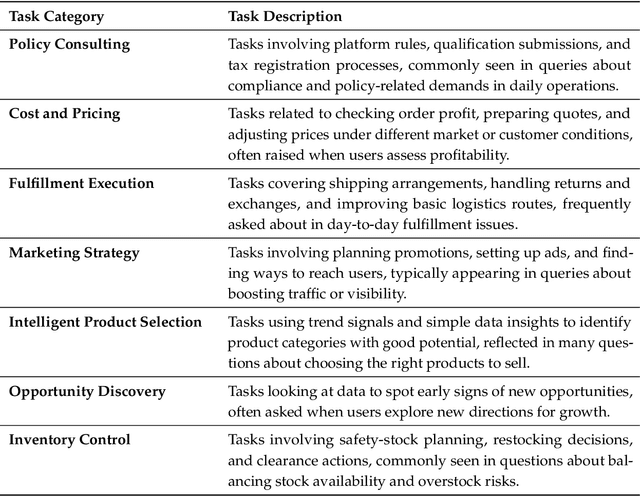

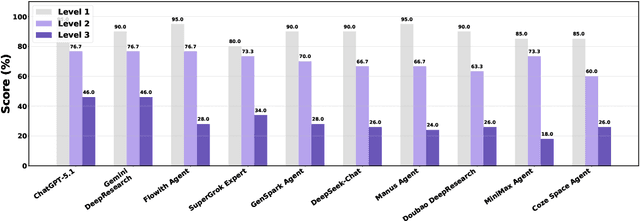
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Scaling Environments for LLM Agents in the Era of Learning from Interaction: A Survey
Nov 12, 2025LLM-based agents can autonomously accomplish complex tasks across various domains. However, to further cultivate capabilities such as adaptive behavior and long-term decision-making, training on static datasets built from human-level knowledge is insufficient. These datasets are costly to construct and lack both dynamism and realism. A growing consensus is that agents should instead interact directly with environments and learn from experience through reinforcement learning. We formalize this iterative process as the Generation-Execution-Feedback (GEF) loop, where environments generate tasks to challenge agents, return observations in response to agents' actions during task execution, and provide evaluative feedback on rollouts for subsequent learning. Under this paradigm, environments function as indispensable producers of experiential data, highlighting the need to scale them toward greater complexity, realism, and interactivity. In this survey, we systematically review representative methods for environment scaling from a pioneering environment-centric perspective and organize them along the stages of the GEF loop, namely task generation, task execution, and feedback. We further analyze benchmarks, implementation strategies, and applications, consolidating fragmented advances and outlining future research directions for agent intelligence.
Reasoning Path Divergence: A New Metric and Curation Strategy to Unlock LLM Diverse Thinking
Oct 30, 2025While Test-Time Scaling (TTS) has proven effective in improving the reasoning ability of large language models (LLMs), low diversity in model outputs often becomes a bottleneck; this is partly caused by the common "one problem, one solution" (1P1S) training practice, which provides a single canonical answer and can push models toward a narrow set of reasoning paths. To address this, we propose a "one problem, multiple solutions" (1PNS) training paradigm that exposes the model to a variety of valid reasoning trajectories and thus increases inference diversity. A core challenge for 1PNS is reliably measuring semantic differences between multi-step chains of thought, so we introduce Reasoning Path Divergence (RPD), a step-level metric that aligns and scores Long Chain-of-Thought solutions to capture differences in intermediate reasoning. Using RPD, we curate maximally diverse solution sets per problem and fine-tune Qwen3-4B-Base. Experiments show that RPD-selected training yields more varied outputs and higher pass@k, with an average +2.80% gain in pass@16 over a strong 1P1S baseline and a +4.99% gain on AIME24, demonstrating that 1PNS further amplifies the effectiveness of TTS. Our code is available at https://github.com/fengjujf/Reasoning-Path-Divergence .
Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4
Oct 30, 2025We present **Lean4PHYS**, a comprehensive reasoning framework for college-level physics problems in Lean4. **Lean4PHYS** includes *LeanPhysBench*, a college-level benchmark for formal physics reasoning in Lean4, which contains 200 hand-crafted and peer-reviewed statements derived from university textbooks and physics competition problems. To establish a solid foundation for formal reasoning in physics, we also introduce *PhysLib*, a community-driven repository containing fundamental unit systems and theorems essential for formal physics reasoning. Based on the benchmark and Lean4 repository we composed in **Lean4PHYS**, we report baseline results using major expert Math Lean4 provers and state-of-the-art closed-source models, with the best performance of DeepSeek-Prover-V2-7B achieving only 16% and Claude-Sonnet-4 achieving 35%. We also conduct a detailed analysis showing that our *PhysLib* can achieve an average improvement of 11.75% in model performance. This demonstrates the challenging nature of our *LeanPhysBench* and the effectiveness of *PhysLib*. To the best of our knowledge, this is the first study to provide a physics benchmark in Lean4.
Diversity-Enhanced Reasoning for Subjective Questions
Jul 27, 2025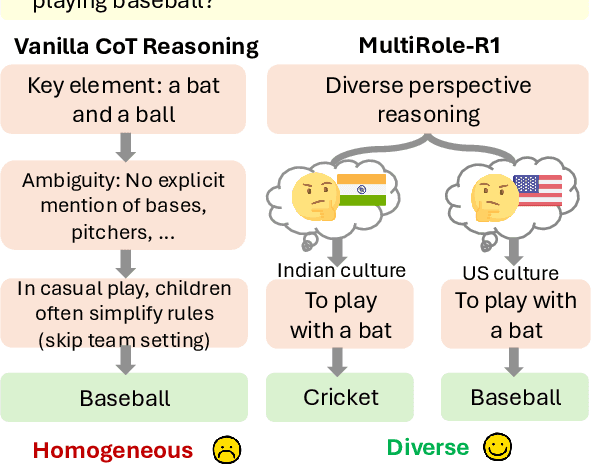
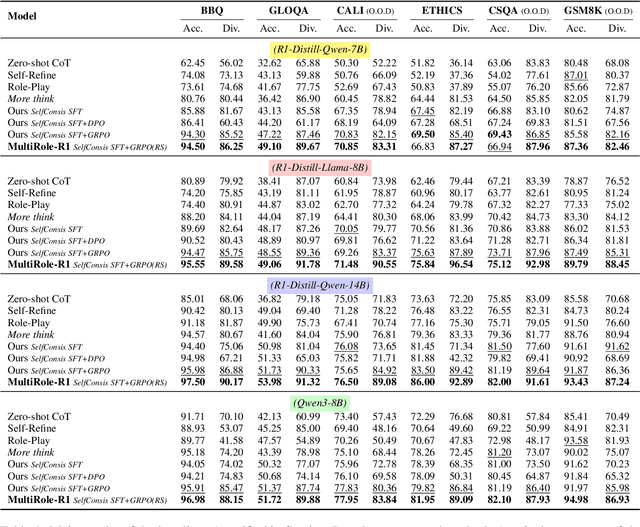
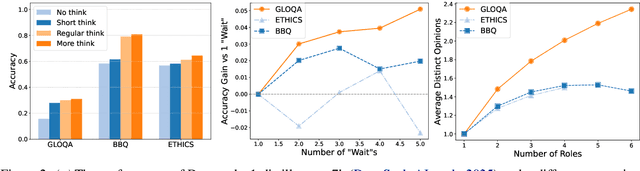
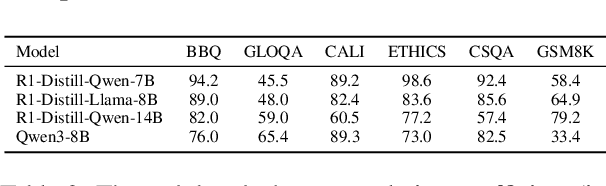
Large reasoning models (LRM) with long chain-of-thought (CoT) capabilities have shown strong performance on objective tasks, such as math reasoning and coding. However, their effectiveness on subjective questions that may have different responses from different perspectives is still limited by a tendency towards homogeneous reasoning, introduced by the reliance on a single ground truth in supervised fine-tuning and verifiable reward in reinforcement learning. Motivated by the finding that increasing role perspectives consistently improves performance, we propose MultiRole-R1, a diversity-enhanced framework with multiple role perspectives, to improve the accuracy and diversity in subjective reasoning tasks. MultiRole-R1 features an unsupervised data construction pipeline that generates reasoning chains that incorporate diverse role perspectives. We further employ reinforcement learning via Group Relative Policy Optimization (GRPO) with reward shaping, by taking diversity as a reward signal in addition to the verifiable reward. With specially designed reward functions, we successfully promote perspective diversity and lexical diversity, uncovering a positive relation between reasoning diversity and accuracy. Our experiment on six benchmarks demonstrates MultiRole-R1's effectiveness and generalizability in enhancing both subjective and objective reasoning, showcasing the potential of diversity-enhanced training in LRMs.
DocCHA: Towards LLM-Augmented Interactive Online diagnosis System
Jul 10, 2025Despite the impressive capabilities of Large Language Models (LLMs), existing Conversational Health Agents (CHAs) remain static and brittle, incapable of adaptive multi-turn reasoning, symptom clarification, or transparent decision-making. This hinders their real-world applicability in clinical diagnosis, where iterative and structured dialogue is essential. We propose DocCHA, a confidence-aware, modular framework that emulates clinical reasoning by decomposing the diagnostic process into three stages: (1) symptom elicitation, (2) history acquisition, and (3) causal graph construction. Each module uses interpretable confidence scores to guide adaptive questioning, prioritize informative clarifications, and refine weak reasoning links. Evaluated on two real-world Chinese consultation datasets (IMCS21, DX), DocCHA consistently outperforms strong prompting-based LLM baselines (GPT-3.5, GPT-4o, LLaMA-3), achieving up to 5.18 percent higher diagnostic accuracy and over 30 percent improvement in symptom recall, with only modest increase in dialogue turns. These results demonstrate the effectiveness of DocCHA in enabling structured, transparent, and efficient diagnostic conversations -- paving the way for trustworthy LLM-powered clinical assistants in multilingual and resource-constrained settings.
CultureCLIP: Empowering CLIP with Cultural Awareness through Synthetic Images and Contextualized Captions
Jul 08, 2025Pretrained vision-language models (VLMs) such as CLIP excel in multimodal understanding but struggle with contextually relevant fine-grained visual features, making it difficult to distinguish visually similar yet culturally distinct concepts. This limitation stems from the scarcity of high-quality culture-specific datasets, the lack of integrated contextual knowledge, and the absence of hard negatives highlighting subtle distinctions. To address these challenges, we first design a data curation pipeline that leverages open-sourced VLMs and text-to-image diffusion models to construct CulTwin, a synthetic cultural dataset. This dataset consists of paired concept-caption-image triplets, where concepts visually resemble each other but represent different cultural contexts. Then, we fine-tune CLIP on CulTwin to create CultureCLIP, which aligns cultural concepts with contextually enhanced captions and synthetic images through customized contrastive learning, enabling finer cultural differentiation while preserving generalization capabilities. Experiments on culturally relevant benchmarks show that CultureCLIP outperforms the base CLIP, achieving up to a notable 5.49% improvement in fine-grained concept recognition on certain tasks, while preserving CLIP's original generalization ability, validating the effectiveness of our data synthesis and VLM backbone training paradigm in capturing subtle cultural distinctions.
MATP-BENCH: Can MLLM Be a Good Automated Theorem Prover for Multimodal Problems?
Jun 06, 2025Numerous theorems, such as those in geometry, are often presented in multimodal forms (e.g., diagrams). Humans benefit from visual reasoning in such settings, using diagrams to gain intuition and guide the proof process. Modern Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in solving a wide range of mathematical problems. However, the potential of MLLMs as Automated Theorem Provers (ATPs), specifically in the multimodal domain, remains underexplored. In this paper, we introduce the Multimodal Automated Theorem Proving benchmark (MATP-BENCH), a new Multimodal, Multi-level, and Multi-language benchmark designed to evaluate MLLMs in this role as multimodal automated theorem provers. MATP-BENCH consists of 1056 multimodal theorems drawn from high school, university, and competition-level mathematics. All these multimodal problems are accompanied by formalizations in Lean 4, Coq and Isabelle, thus making the benchmark compatible with a wide range of theorem-proving frameworks. MATP-BENCH requires models to integrate sophisticated visual understanding with mastery of a broad spectrum of mathematical knowledge and rigorous symbolic reasoning to generate formal proofs. We use MATP-BENCH to evaluate a variety of advanced multimodal language models. Existing methods can only solve a limited number of the MATP-BENCH problems, indicating that this benchmark poses an open challenge for research on automated theorem proving.