 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Language Models Diverge from Natural Language: Comparative Analysis and Improved Inference
Feb 24, 2026Modern Protein Language Models (PLMs) apply transformer-based model architectures from natural language processing to biological sequences, predicting a variety of protein functions and properties. However, protein language has key differences from natural language, such as a rich functional space despite a vocabulary of only 20 amino acids. These differences motivate research into how transformer-based architectures operate differently in the protein domain and how we can better leverage PLMs to solve protein-related tasks. In this work, we begin by directly comparing how the distribution of information stored across layers of attention heads differs between the protein and natural language domain. Furthermore, we adapt a simple early-exit technique-originally used in the natural language domain to improve efficiency at the cost of performance-to achieve both increased accuracy and substantial efficiency gains in protein non-structural property prediction by allowing the model to automatically select protein representations from the intermediate layers of the PLMs for the specific task and protein at hand. We achieve performance gains ranging from 0.4 to 7.01 percentage points while simultaneously improving efficiency by over 10 percent across models and non-structural prediction tasks. Our work opens up an area of research directly comparing how language models change behavior when moved into the protein domain and advances language modeling in biological domains.
mCLM: A Function-Infused and Synthesis-Friendly Modular Chemical Language Model
May 18, 2025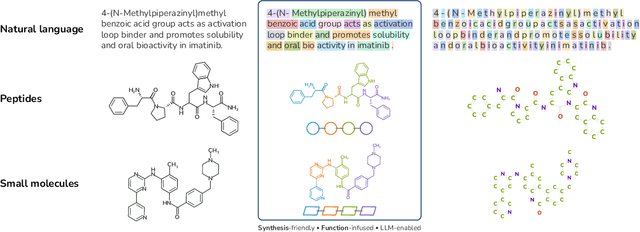
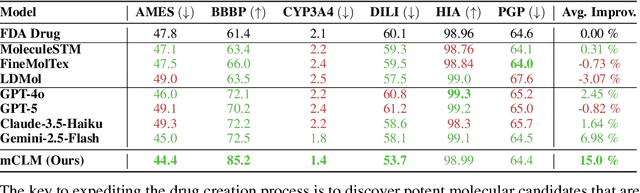
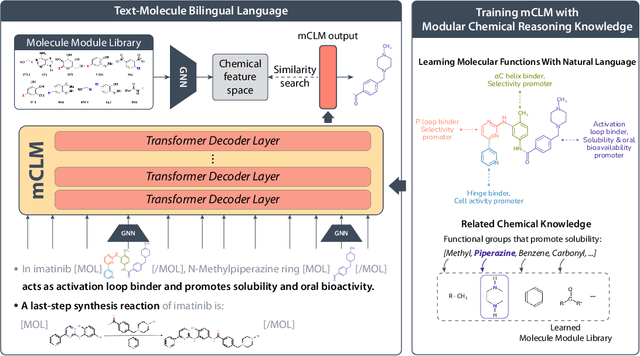
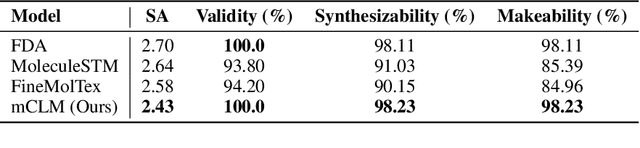
Despite their ability to understand chemical knowledge and accurately generate sequential representations, large language models (LLMs) remain limited in their capacity to propose novel molecules with drug-like properties. In addition, the molecules that LLMs propose can often be challenging to make in the lab. To more effectively enable the discovery of functional small molecules, LLMs need to learn a molecular language. However, LLMs are currently limited by encoding molecules from atoms. In this paper, we argue that just like tokenizing texts into (sub-)word tokens instead of characters, molecules should be decomposed and reassembled at the level of functional building blocks, i.e., parts of molecules that bring unique functions and serve as effective building blocks for real-world automated laboratory synthesis. This motivates us to propose mCLM, a modular Chemical-Language Model tokenizing molecules into building blocks and learning a bilingual language model of both natural language descriptions of functions and molecule building blocks. By reasoning on such functional building blocks, mCLM guarantees to generate efficiently synthesizable molecules thanks to recent progress in block-based chemistry, while also improving the functions of molecules in a principled manner. In experiments on 430 FDA-approved drugs, we find mCLM capable of significantly improving 5 out of 6 chemical functions critical to determining drug potentials. More importantly, mCLM can reason on multiple functions and improve the FDA-rejected drugs (``fallen angels'') over multiple iterations to greatly improve their shortcomings.
Computation Mechanism Behind LLM Position Generalization
Mar 17, 2025



Most written natural languages are composed of sequences of words and sentences. Similar to humans, large language models (LLMs) exhibit flexibility in handling textual positions - a phenomenon we term position generalization. They can understand texts with position perturbations and generalize to longer texts than those encountered during training with the latest techniques. These phenomena suggest that LLMs handle positions tolerantly, but how LLMs computationally process positional relevance remains largely unexplored. This work connects the linguistic phenomenon with LLMs' computational mechanisms. We show how LLMs enforce certain computational mechanisms for the aforementioned tolerance in position perturbations. Despite the complex design of the self-attention mechanism, this work reveals that LLMs learn a counterintuitive disentanglement of attention logits. Their values show a 0.959 linear correlation with an approximation of the arithmetic sum of positional relevance and semantic importance. Furthermore, we identify a prevalent pattern in intermediate features, which we prove theoretically enables this effect. The pattern, which is different from how randomly initialized parameters would behave, suggests that it is a learned behavior rather than a natural result of the model architecture. Based on these findings, we provide computational explanations and criteria for LLMs' position flexibilities. This work takes a pioneering step in linking position generalization with modern LLMs' internal mechanisms.
Can Language Models Follow Multiple Turns of Entangled Instructions?
Mar 17, 2025Despite significant achievements in improving the instruction-following capabilities of large language models (LLMs), the ability to process multiple potentially entangled or conflicting instructions remains a considerable challenge. Real-world scenarios often require consistency across multiple instructions over time, such as secret privacy, personal preferences, and prioritization, which demand sophisticated abilities to integrate multiple turns and carefully balance competing objectives when instructions intersect or conflict. This work presents a systematic investigation of LLMs' capabilities in handling multiple turns of instructions, covering three levels of difficulty: (1) retrieving information from instructions, (2) tracking and reasoning across turns, and (3) resolving conflicts among instructions. We construct MultiTurnInstruct with around 1.1K high-quality multi-turn conversations through the human-in-the-loop approach and result in nine capability categories, including statics and dynamics, reasoning, and multitasking. Our finding reveals an intriguing trade-off between different capabilities. While GPT models demonstrate superior memorization, they show reduced effectiveness in privacy-protection tasks requiring selective information withholding. Larger models exhibit stronger reasoning capabilities but still struggle with resolving conflicting instructions. Importantly, these performance gaps cannot be attributed solely to information loss, as models demonstrate strong BLEU scores on memorization tasks but their attention mechanisms fail to integrate multiple related instructions effectively. These findings highlight critical areas for improvement in complex real-world tasks involving multi-turn instructions.
The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination
Feb 22, 2025



Hallucination is a persistent challenge in large language models (LLMs), where even with rigorous quality control, models often generate distorted facts. This paradox, in which error generation continues despite high-quality training data, calls for a deeper understanding of the underlying LLM mechanisms. To address it, we propose a novel concept: knowledge overshadowing, where model's dominant knowledge can obscure less prominent knowledge during text generation, causing the model to fabricate inaccurate details. Building on this idea, we introduce a novel framework to quantify factual hallucinations by modeling knowledge overshadowing. Central to our approach is the log-linear law, which predicts that the rate of factual hallucination increases linearly with the logarithmic scale of (1) Knowledge Popularity, (2) Knowledge Length, and (3) Model Size. The law provides a means to preemptively quantify hallucinations, offering foresight into their occurrence even before model training or inference. Built on overshadowing effect, we propose a new decoding strategy CoDa, to mitigate hallucinations, which notably enhance model factuality on Overshadow (27.9%), MemoTrap (13.1%) and NQ-Swap (18.3%). Our findings not only deepen understandings of the underlying mechanisms behind hallucinations but also provide actionable insights for developing more predictable and controllable language models.
SyncMind: Measuring Agent Out-of-Sync Recovery in Collaborative Software Engineering
Feb 10, 2025
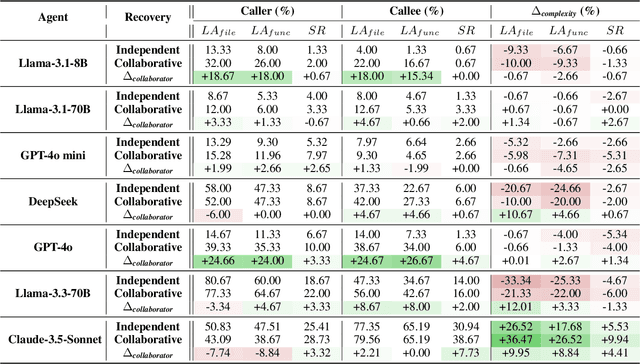


Software engineering (SE) is increasingly collaborative, with developers working together on shared complex codebases. Effective collaboration in shared environments requires participants -- whether humans or AI agents -- to stay on the same page as their environment evolves. When a collaborator's understanding diverges from the current state -- what we term the out-of-sync challenge -- the collaborator's actions may fail, leading to integration issues. In this work, we introduce SyncMind, a framework that systematically defines the out-of-sync problem faced by large language model (LLM) agents in collaborative software engineering (CSE). Based on SyncMind, we create SyncBench, a benchmark featuring 24,332 instances of agent out-of-sync scenarios in real-world CSE derived from 21 popular GitHub repositories with executable verification tests. Experiments on SyncBench uncover critical insights into existing LLM agents' capabilities and limitations. Besides substantial performance gaps among agents (from Llama-3.1 agent <= 3.33% to Claude-3.5-Sonnet >= 28.18%), their consistently low collaboration willingness (<= 4.86%) suggests fundamental limitations of existing LLM in CSE. However, when collaboration occurs, it positively correlates with out-of-sync recovery success. Minimal performance differences in agents' resource-aware out-of-sync recoveries further reveal their significant lack of resource awareness and adaptability, shedding light on future resource-efficient collaborative systems. Code and data are openly available on our project website: https://xhguo7.github.io/SyncMind/.
Learning to Generate Research Idea with Dynamic Control
Dec 19, 2024The rapid advancements in large language models (LLMs) have demonstrated their potential to accelerate scientific discovery, particularly in automating the process of research ideation. LLM-based systems have shown promise in generating hypotheses and research ideas. However, current approaches predominantly rely on prompting-based pre-trained models, limiting their ability to optimize generated content effectively. Moreover, they also lack the capability to deal with the complex interdependence and inherent restrictions among novelty, feasibility, and effectiveness, which remains challenging due to the inherent trade-offs among these dimensions, such as the innovation-feasibility conflict. To address these limitations, we for the first time propose fine-tuning LLMs to be better idea proposers and introduce a novel framework that employs a two-stage approach combining Supervised Fine-Tuning (SFT) and controllable Reinforcement Learning (RL). In the SFT stage, the model learns foundational patterns from pairs of research papers and follow-up ideas. In the RL stage, multi-dimensional reward modeling, guided by fine-grained feedback, evaluates and optimizes the generated ideas across key metrics. Dimensional controllers enable dynamic adjustment of generation, while a sentence-level decoder ensures context-aware emphasis during inference. Our framework provides a balanced approach to research ideation, achieving high-quality outcomes by dynamically navigating the trade-offs among novelty, feasibility, and effectiveness.
Schema-Guided Culture-Aware Complex Event Simulation with Multi-Agent Role-Play
Oct 24, 2024



Complex news events, such as natural disasters and socio-political conflicts, require swift responses from the government and society. Relying on historical events to project the future is insufficient as such events are sparse and do not cover all possible conditions and nuanced situations. Simulation of these complex events can help better prepare and reduce the negative impact. We develop a controllable complex news event simulator guided by both the event schema representing domain knowledge about the scenario and user-provided assumptions representing case-specific conditions. As event dynamics depend on the fine-grained social and cultural context, we further introduce a geo-diverse commonsense and cultural norm-aware knowledge enhancement component. To enhance the coherence of the simulation, apart from the global timeline of events, we take an agent-based approach to simulate the individual character states, plans, and actions. By incorporating the schema and cultural norms, our generated simulations achieve much higher coherence and appropriateness and are received favorably by participants from a humanitarian assistance organization.
MentalArena: Self-play Training of Language Models for Diagnosis and Treatment of Mental Health Disorders
Oct 09, 2024



Mental health disorders are one of the most serious diseases in the world. Most people with such a disease lack access to adequate care, which highlights the importance of training models for the diagnosis and treatment of mental health disorders. However, in the mental health domain, privacy concerns limit the accessibility of personalized treatment data, making it challenging to build powerful models. In this paper, we introduce MentalArena, a self-play framework to train language models by generating domain-specific personalized data, where we obtain a better model capable of making a personalized diagnosis and treatment (as a therapist) and providing information (as a patient). To accurately model human-like mental health patients, we devise Symptom Encoder, which simulates a real patient from both cognition and behavior perspectives. To address intent bias during patient-therapist interactions, we propose Symptom Decoder to compare diagnosed symptoms with encoded symptoms, and dynamically manage the dialogue between patient and therapist according to the identified deviations. We evaluated MentalArena against 6 benchmarks, including biomedicalQA and mental health tasks, compared to 6 advanced models. Our models, fine-tuned on both GPT-3.5 and Llama-3-8b, significantly outperform their counterparts, including GPT-4o. We hope that our work can inspire future research on personalized care. Code is available in https://github.com/Scarelette/MentalArena/tree/main
Eliminating Position Bias of Language Models: A Mechanistic Approach
Jul 01, 2024


Position bias has proven to be a prevalent issue of modern language models (LMs), where the models prioritize content based on its position within the given context. This bias often leads to unexpected model failures and hurts performance, robustness, and reliability across various applications. Our mechanistic analysis attributes the position bias to two components employed in nearly all state-of-the-art LMs: causal attention and relative positional encodings. Specifically, we find that causal attention generally causes models to favor distant content, while relative positional encodings like RoPE prefer nearby ones based on the analysis of retrieval-augmented question answering (QA). Further, our empirical study on object detection reveals that position bias is also present in vision-language models (VLMs). Based on the above analyses, we propose to ELIMINATE position bias caused by different input segment orders (e.g., options in LM-as-a-judge, retrieved documents in QA) in a TRAINING-FREE ZERO-SHOT manner. Our method changes the causal attention to bidirectional attention between segments and utilizes model attention values to decide the relative orders of segments instead of using the order provided in input prompts, therefore enabling Position-INvariant inferencE (PINE) at the segment level. By eliminating position bias, models achieve better performance and reliability in downstream tasks where position bias widely exists, such as LM-as-a-judge and retrieval-augmented QA. Notably, PINE is especially useful when adapting LMs for evaluating reasoning pairs: it consistently provides 8 to 10 percentage points performance gains in most cases, and makes Llama-3-70B-Instruct perform even better than GPT-4-0125-preview on the RewardBench reasoning subset.